 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre We Making Progress in Multimodal Domain Generalization? A Comprehensive Benchmark Study
May 07, 2026Despite the growing popularity of Multimodal Domain Generalization (MMDG) for enhancing model robustness, it remains unclear whether reported performance gains reflect genuine algorithmic progress or are artifacts of inconsistent evaluation protocols. Current research is fragmented, with studies varying significantly across datasets, modality configurations, and experimental settings. Furthermore, existing benchmarks focus predominantly on action recognition, often neglecting critical real-world challenges such as input corruptions, missing modalities, and model trustworthiness. This lack of standardization obscures a reliable assessment of the field's advancement. To address this issue, we introduce MMDG-Bench, the first unified and comprehensive benchmark for MMDG, which standardizes evaluation across six datasets spanning three diverse tasks: action recognition, mechanical fault diagnosis, and sentiment analysis. MMDG-Bench encompasses six modality combinations, nine representative methods, and multiple evaluation settings. Beyond standard accuracy, it systematically assesses corruption robustness, missing-modality generalization, misclassification detection, and out-of-distribution detection. With 7, 402 neural networks trained in total across 95 unique cross-domain tasks, MMDG-Bench yields five key findings: (1) under fair comparisons, recent specialized MMDG methods offer only marginal improvements over ERM baseline; (2) no single method consistently outperforms others across datasets or modality combinations; (3) a substantial gap to upper-bound performance persists, indicating that MMDG remains far from solved; (4) trimodal fusion does not consistently outperform the strongest bimodal configurations; and (5) all evaluated methods exhibit significant degradation under corruption and missing-modality scenarios, with some methods further compromising model trustworthiness.
Disentangling Damage from Operational Variability: A Label-Free Self-Supervised Representation Learning Framework for Output-Only Structural Damage Identification
Apr 21, 2026Damage identification is a core task in structural health monitoring. In practice, however, its reliability is often compromised by confounding non-damage effects, such as variations in excitation and environmental conditions, which can induce changes comparable to or larger than those caused by structural damage. To address this challenge, this study proposes a self-supervised label-free disentangled representation learning framework for robust vibration-based structural damage identification. The proposed framework employs an autoencoder with two latent representations to learn directly from raw vibration acceleration signals. A self-supervised invariance regularization, implemented via Variance-Invariance-Covariance Regularization (VICReg), is imposed on one latent representation using baseline data where structural damage is assumed constant but operational and environmental conditions vary. In addition, a frequency-domain constraint is introduced to enforce agreement between the power spectral density reconstructed from the latent representation and that computed from the corresponding input time series. Together, these mechanisms promote disentanglement, enabling the learned representation to be sensitive to damage-related characteristics while remaining invariant to nuisance variability. The framework is trained in a fully end-to-end and label-free manner, requiring no prior information on damage, excitation, or environmental conditions, making it well-suited for real-world applications. Its effectiveness is validated on two distinct real-world vibration datasets, including a bridge and a gearbox. The results demonstrate robustness to operational variability, strong generalization capability, and good performance in both damage detection and quantification.
Multimodal Learning for Arcing Detection in Pantograph-Catenary Systems
Feb 09, 2026The pantograph-catenary interface is essential for ensuring uninterrupted and reliable power delivery in electrified rail systems. However, electrical arcing at this interface poses serious risks, including accelerated wear of contact components, degraded system performance, and potential service disruptions. Detecting arcing events at the pantograph-catenary interface is challenging due to their transient nature, noisy operating environment, data scarcity, and the difficulty of distinguishing arcs from other similar transient phenomena. To address these challenges, we propose a novel multimodal framework that combines high-resolution image data with force measurements to more accurately and robustly detect arcing events. First, we construct two arcing detection datasets comprising synchronized visual and force measurements. One dataset is built from data provided by the Swiss Federal Railways (SBB), and the other is derived from publicly available videos of arcing events in different railway systems and synthetic force data that mimic the characteristics observed in the real dataset. Leveraging these datasets, we propose MultiDeepSAD, an extension of the DeepSAD algorithm for multiple modalities with a new loss formulation. Additionally, we introduce tailored pseudo-anomaly generation techniques specific to each data type, such as synthetic arc-like artifacts in images and simulated force irregularities, to augment training data and improve the discriminative ability of the model. Through extensive experiments and ablation studies, we demonstrate that our framework significantly outperforms baseline approaches, exhibiting enhanced sensitivity to real arcing events even under domain shifts and limited availability of real arcing observations.
A Mechanistic Analysis of Transformers for Dynamical Systems
Dec 24, 2025Transformers are increasingly adopted for modeling and forecasting time-series, yet their internal mechanisms remain poorly understood from a dynamical systems perspective. In contrast to classical autoregressive and state-space models, which benefit from well-established theoretical foundations, Transformer architectures are typically treated as black boxes. This gap becomes particularly relevant as attention-based models are considered for general-purpose or zero-shot forecasting across diverse dynamical regimes. In this work, we do not propose a new forecasting model, but instead investigate the representational capabilities and limitations of single-layer Transformers when applied to dynamical data. Building on a dynamical systems perspective we interpret causal self-attention as a linear, history-dependent recurrence and analyze how it processes temporal information. Through a series of linear and nonlinear case studies, we identify distinct operational regimes. For linear systems, we show that the convexity constraint imposed by softmax attention fundamentally restricts the class of dynamics that can be represented, leading to oversmoothing in oscillatory settings. For nonlinear systems under partial observability, attention instead acts as an adaptive delay-embedding mechanism, enabling effective state reconstruction when sufficient temporal context and latent dimensionality are available. These results help bridge empirical observations with classical dynamical systems theory, providing insight into when and why Transformers succeed or fail as models of dynamical systems.
Adapting Vision-Language Models Without Labels: A Comprehensive Survey
Aug 07, 2025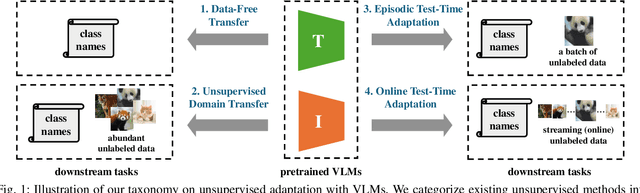
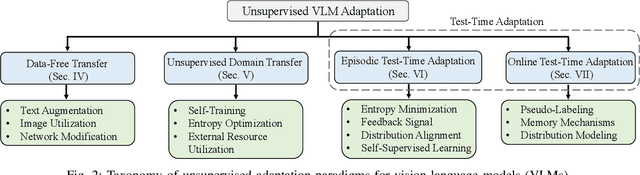
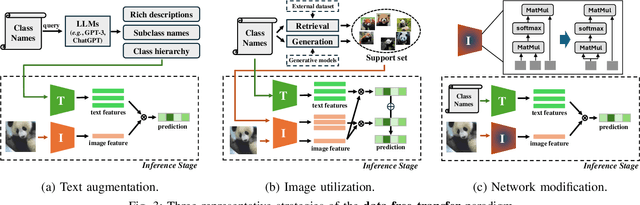
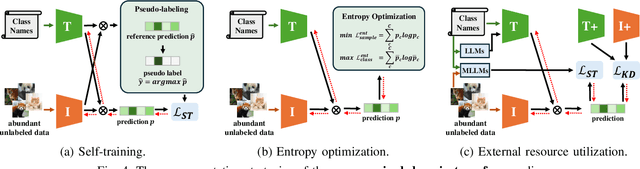
Vision-Language Models (VLMs) have demonstrated remarkable generalization capabilities across a wide range of tasks. However, their performance often remains suboptimal when directly applied to specific downstream scenarios without task-specific adaptation. To enhance their utility while preserving data efficiency, recent research has increasingly focused on unsupervised adaptation methods that do not rely on labeled data. Despite the growing interest in this area, there remains a lack of a unified, task-oriented survey dedicated to unsupervised VLM adaptation. To bridge this gap, we present a comprehensive and structured overview of the field. We propose a taxonomy based on the availability and nature of unlabeled visual data, categorizing existing approaches into four key paradigms: Data-Free Transfer (no data), Unsupervised Domain Transfer (abundant data), Episodic Test-Time Adaptation (batch data), and Online Test-Time Adaptation (streaming data). Within this framework, we analyze core methodologies and adaptation strategies associated with each paradigm, aiming to establish a systematic understanding of the field. Additionally, we review representative benchmarks across diverse applications and highlight open challenges and promising directions for future research. An actively maintained repository of relevant literature is available at https://github.com/tim-learn/Awesome-LabelFree-VLMs.
Beyond Static Models: Hypernetworks for Adaptive and Generalizable Forecasting in Complex Parametric Dynamical Systems
Jun 24, 2025



Dynamical systems play a key role in modeling, forecasting, and decision-making across a wide range of scientific domains. However, variations in system parameters, also referred to as parametric variability, can lead to drastically different model behavior and output, posing challenges for constructing models that generalize across parameter regimes. In this work, we introduce the Parametric Hypernetwork for Learning Interpolated Networks (PHLieNet), a framework that simultaneously learns: (a) a global mapping from the parameter space to a nonlinear embedding and (b) a mapping from the inferred embedding to the weights of a dynamics propagation network. The learned embedding serves as a latent representation that modulates a base network, termed the hypernetwork, enabling it to generate the weights of a target network responsible for forecasting the system's state evolution conditioned on the previous time history. By interpolating in the space of models rather than observations, PHLieNet facilitates smooth transitions across parameterized system behaviors, enabling a unified model that captures the dynamic behavior across a broad range of system parameterizations. The performance of the proposed technique is validated in a series of dynamical systems with respect to its ability to extrapolate in time and interpolate and extrapolate in the parameter space, i.e., generalize to dynamics that were unseen during training. In all cases, our approach outperforms or matches state-of-the-art baselines in both short-term forecast accuracy and in capturing long-term dynamical features, such as attractor statistics.
Automating Traffic Monitoring with SHM Sensor Networks via Vision-Supervised Deep Learning
Jun 23, 2025Bridges, as critical components of civil infrastructure, are increasingly affected by deterioration, making reliable traffic monitoring essential for assessing their remaining service life. Among operational loads, traffic load plays a pivotal role, and recent advances in deep learning - particularly in computer vision (CV) - have enabled progress toward continuous, automated monitoring. However, CV-based approaches suffer from limitations, including privacy concerns and sensitivity to lighting conditions, while traditional non-vision-based methods often lack flexibility in deployment and validation. To bridge this gap, we propose a fully automated deep-learning pipeline for continuous traffic monitoring using structural health monitoring (SHM) sensor networks. Our approach integrates CV-assisted high-resolution dataset generation with supervised training and inference, leveraging graph neural networks (GNNs) to capture the spatial structure and interdependence of sensor data. By transferring knowledge from CV outputs to SHM sensors, the proposed framework enables sensor networks to achieve comparable accuracy of vision-based systems, with minimal human intervention. Applied to accelerometer and strain gauge data in a real-world case study, the model achieves state-of-the-art performance, with classification accuracies of 99% for light vehicles and 94% for heavy vehicles.
To Trust Or Not To Trust Your Vision-Language Model's Prediction
May 29, 2025Vision-Language Models (VLMs) have demonstrated strong capabilities in aligning visual and textual modalities, enabling a wide range of applications in multimodal understanding and generation. While they excel in zero-shot and transfer learning scenarios, VLMs remain susceptible to misclassification, often yielding confident yet incorrect predictions. This limitation poses a significant risk in safety-critical domains, where erroneous predictions can lead to severe consequences. In this work, we introduce TrustVLM, a training-free framework designed to address the critical challenge of estimating when VLM's predictions can be trusted. Motivated by the observed modality gap in VLMs and the insight that certain concepts are more distinctly represented in the image embedding space, we propose a novel confidence-scoring function that leverages this space to improve misclassification detection. We rigorously evaluate our approach across 17 diverse datasets, employing 4 architectures and 2 VLMs, and demonstrate state-of-the-art performance, with improvements of up to 51.87% in AURC, 9.14% in AUROC, and 32.42% in FPR95 compared to existing baselines. By improving the reliability of the model without requiring retraining, TrustVLM paves the way for safer deployment of VLMs in real-world applications. The code will be available at https://github.com/EPFL-IMOS/TrustVLM.
Modal Decomposition and Identification for a Population of Structures Using Physics-Informed Graph Neural Networks and Transformers
May 06, 2025Modal identification is crucial for structural health monitoring and structural control, providing critical insights into structural dynamics and performance. This study presents a novel deep learning framework that integrates graph neural networks (GNNs), transformers, and a physics-informed loss function to achieve modal decomposition and identification across a population of structures. The transformer module decomposes multi-degrees-of-freedom (MDOF) structural dynamic measurements into single-degree-of-freedom (SDOF) modal responses, facilitating the identification of natural frequencies and damping ratios. Concurrently, the GNN captures the structural configurations and identifies mode shapes corresponding to the decomposed SDOF modal responses. The proposed model is trained in a purely physics-informed and unsupervised manner, leveraging modal decomposition theory and the independence of structural modes to guide learning without the need for labeled data. Validation through numerical simulations and laboratory experiments demonstrates its effectiveness in accurately decomposing dynamic responses and identifying modal properties from sparse structural dynamic measurements, regardless of variations in external loads or structural configurations. Comparative analyses against established modal identification techniques and model variations further underscore its superior performance, positioning it as a favorable approach for population-based structural health monitoring.
Grammar-based Ordinary Differential Equation Discovery
Apr 03, 2025The understanding and modeling of complex physical phenomena through dynamical systems has historically driven scientific progress, as it provides the tools for predicting the behavior of different systems under diverse conditions through time. The discovery of dynamical systems has been indispensable in engineering, as it allows for the analysis and prediction of complex behaviors for computational modeling, diagnostics, prognostics, and control of engineered systems. Joining recent efforts that harness the power of symbolic regression in this domain, we propose a novel framework for the end-to-end discovery of ordinary differential equations (ODEs), termed Grammar-based ODE Discovery Engine (GODE). The proposed methodology combines formal grammars with dimensionality reduction and stochastic search for efficiently navigating high-dimensional combinatorial spaces. Grammars allow us to seed domain knowledge and structure for both constraining, as well as, exploring the space of candidate expressions. GODE proves to be more sample- and parameter-efficient than state-of-the-art transformer-based models and to discover more accurate and parsimonious ODE expressions than both genetic programming- and other grammar-based methods for more complex inference tasks, such as the discovery of structural dynamics. Thus, we introduce a tool that could play a catalytic role in dynamics discovery tasks, including modeling, system identification, and monitoring tasks.