 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgescLLM-DSC: LLM-Knowledge Enhanced Cross-Modal Deep Structural Clustering for Single-Cell RNA Sequencing
Jun 11, 2026Clustering is fundamental to scRNA-seq analysis, serving as a cornerstone for identifying cell populations and resolving tissue heterogeneity. However, existing methods focus on mining numerical statistical patterns, suffering from semantic agnosticism by neglecting the intrinsic biological functions encoded by genes. While Large Language Models (LLMs) offer promising semantic capabilities, their direct adaptation to cell clustering is hindered by the structural mismatch between generative pre-training objectives and discriminative downstream tasks. To bridge this gap, we propose scLLM-DSC, a novel LLM-Knowledge Enhanced Cross-Modal Deep Structural Clustering framework. Diverging from data-driven paradigms, scLLM-DSC establishes a semantically-grounded representation by synergizing two views: a Knowledge-Driven Semantic View derived from NCBI gene priors and contextualized Cell2Sentence embeddings, and a Structure-Aware Topological View extracted via a graph-guided encoder. Crucially, we introduce a cross-modal contrastive alignment mechanism to enforce consistency between biological semantics and transcriptomic features within a unified latent space. Extensive benchmarks demonstrate that scLLM-DSC significantly outperforms eleven state-of-the-art baselines in clustering accuracy.
ClawMark: A Living-World Benchmark for Multi-Turn, Multi-Day, Multimodal Coworker Agents
Apr 26, 2026Language-model agents are increasingly used as persistent coworkers that assist users across multiple working days. During such workflows, the surrounding environment may change independently of the agent: new emails arrive, calendar entries shift, knowledge-base records are updated, and evidence appears across images, scanned PDFs, audio, video, and spreadsheets. Existing benchmarks do not adequately evaluate this setting because they typically run within a single static episode and remain largely text-centric. We introduce \bench{}, a benchmark for coworker agents built around multi-turn multi-day tasks, a stateful sandboxed service environment whose state evolves between turns, and rule-based verification. The current release contains 100 tasks across 13 professional scenarios, executed against five stateful sandboxed services (filesystem, email, calendar, knowledge base, spreadsheet) and scored by 1537 deterministic Python checkers over post-execution service state; no LLM-as-judge is invoked during scoring. We benchmark seven frontier agent systems. The strongest model reaches 75.8 weighted score, but the best strict Task Success is only 20.0\%, indicating that partial progress is common while complete end-to-end workflow completion remains rare. Turn-level analysis shows that performance drops after the first exogenous environment update, highlighting adaptation to changing state as a key open challenge. We release the benchmark, evaluation harness, and construction pipeline to support reproducible coworker-agent evaluation.
Gym-V: A Unified Vision Environment System for Agentic Vision Research
Mar 17, 2026As agentic systems increasingly rely on reinforcement learning from verifiable rewards, standardized ``gym'' infrastructure has become essential for rapid iteration, reproducibility, and fair comparison. Vision agents lack such infrastructure, limiting systematic study of what drives their learning and where current models fall short. We introduce \textbf{Gym-V}, a unified platform of 179 procedurally generated visual environments across 10 domains with controllable difficulty, enabling controlled experiments that were previously infeasible across fragmented toolkits. Using it, we find that observation scaffolding is more decisive for training success than the choice of RL algorithm, with captions and game rules determining whether learning succeeds at all. Cross-domain transfer experiments further show that training on diverse task categories generalizes broadly while narrow training can cause negative transfer, with multi-turn interaction amplifying all of these effects. Gym-V is released as a convenient foundation for training environments and evaluation toolkits, aiming to accelerate future research on agentic VLMs.
AdaReasoner: Dynamic Tool Orchestration for Iterative Visual Reasoning
Jan 26, 2026When humans face problems beyond their immediate capabilities, they rely on tools, providing a promising paradigm for improving visual reasoning in multimodal large language models (MLLMs). Effective reasoning, therefore, hinges on knowing which tools to use, when to invoke them, and how to compose them over multiple steps, even when faced with new tools or new tasks. We introduce \textbf{AdaReasoner}, a family of multimodal models that learn tool use as a general reasoning skill rather than as tool-specific or explicitly supervised behavior. AdaReasoner is enabled by (i) a scalable data curation pipeline exposing models to long-horizon, multi-step tool interactions; (ii) Tool-GRPO, a reinforcement learning algorithm that optimizes tool selection and sequencing based on end-task success; and (iii) an adaptive learning mechanism that dynamically regulates tool usage. Together, these components allow models to infer tool utility from task context and intermediate outcomes, enabling coordination of multiple tools and generalization to unseen tools. Empirically, AdaReasoner exhibits strong tool-adaptive and generalization behaviors: it autonomously adopts beneficial tools, suppresses irrelevant ones, and adjusts tool usage frequency based on task demands, despite never being explicitly trained to do so. These capabilities translate into state-of-the-art performance across challenging benchmarks, improving the 7B base model by +24.9\% on average and surpassing strong proprietary systems such as GPT-5 on multiple tasks, including VSP and Jigsaw.
ThinkMorph: Emergent Properties in Multimodal Interleaved Chain-of-Thought Reasoning
Oct 30, 2025



Multimodal reasoning requires iterative coordination between language and vision, yet it remains unclear what constitutes a meaningful interleaved chain of thought. We posit that text and image thoughts should function as complementary, rather than isomorphic, modalities that mutually advance reasoning. Guided by this principle, we build ThinkMorph, a unified model fine-tuned on 24K high-quality interleaved reasoning traces spanning tasks with varying visual engagement. ThinkMorph learns to generate progressive text-image reasoning steps that concretely manipulate visual content while maintaining coherent verbal logic. It delivers large gains on vision-centric benchmarks (averaging 34.7% over the base model) and generalizes to out-of-domain tasks, matching or surpassing larger and proprietary VLMs. Beyond performance, ThinkMorph exhibits emergent multimodal intelligence, including unseen visual manipulation skills, adaptive switching between reasoning modes, and better test-time scaling through diversified multimodal thoughts.These findings suggest promising directions for characterizing the emergent capabilities of unified models for multimodal reasoning.
Gradient Short-Circuit: Efficient Out-of-Distribution Detection via Feature Intervention
Jul 02, 2025Out-of-Distribution (OOD) detection is critical for safely deploying deep models in open-world environments, where inputs may lie outside the training distribution. During inference on a model trained exclusively with In-Distribution (ID) data, we observe a salient gradient phenomenon: around an ID sample, the local gradient directions for "enhancing" that sample's predicted class remain relatively consistent, whereas OOD samples--unseen in training--exhibit disorganized or conflicting gradient directions in the same neighborhood. Motivated by this observation, we propose an inference-stage technique to short-circuit those feature coordinates that spurious gradients exploit to inflate OOD confidence, while leaving ID classification largely intact. To circumvent the expense of recomputing the logits after this gradient short-circuit, we further introduce a local first-order approximation that accurately captures the post-modification outputs without a second forward pass. Experiments on standard OOD benchmarks show our approach yields substantial improvements. Moreover, the method is lightweight and requires minimal changes to the standard inference pipeline, offering a practical path toward robust OOD detection in real-world applications.
Unfolding Spatial Cognition: Evaluating Multimodal Models on Visual Simulations
Jun 05, 2025Spatial cognition is essential for human intelligence, enabling problem-solving through visual simulations rather than solely relying on verbal reasoning. However, existing AI benchmarks primarily assess verbal reasoning, neglecting the complexities of non-verbal, multi-step visual simulation. We introduce STARE(Spatial Transformations and Reasoning Evaluation), a benchmark designed to rigorously evaluate multimodal large language models on tasks better solved through multi-step visual simulation. STARE features 4K tasks spanning foundational geometric transformations (2D and 3D), integrated spatial reasoning (cube net folding and tangram puzzles), and real-world spatial reasoning (perspective and temporal reasoning), reflecting practical cognitive challenges like object assembly, mechanical diagram interpretation, and everyday spatial navigation. Our evaluations show that models excel at reasoning over simpler 2D transformations, but perform close to random chance on more complex tasks like 3D cube net folding and tangram puzzles that require multi-step visual simulations. Humans achieve near-perfect accuracy but take considerable time (up to 28.9s) on complex tasks, significantly speeding up (down by 7.5 seconds on average) with intermediate visual simulations. In contrast, models exhibit inconsistent performance gains from visual simulations, improving on most tasks but declining in specific cases like tangram puzzles (GPT-4o, o1) and cube net folding (Claude-3.5, Gemini-2.0 Flash), indicating that models may not know how to effectively leverage intermediate visual information.
FullFront: Benchmarking MLLMs Across the Full Front-End Engineering Workflow
May 26, 2025Front-end engineering involves a complex workflow where engineers conceptualize designs, translate them into code, and iteratively refine the implementation. While recent benchmarks primarily focus on converting visual designs to code, we present FullFront, a benchmark designed to evaluate Multimodal Large Language Models (MLLMs) \textbf{across the full front-end development pipeline}. FullFront assesses three fundamental tasks that map directly to the front-end engineering pipeline: Webpage Design (conceptualization phase), Webpage Perception QA (comprehension of visual organization and elements), and Webpage Code Generation (implementation phase). Unlike existing benchmarks that use either scraped websites with bloated code or oversimplified LLM-generated HTML, FullFront employs a novel, two-stage process to transform real-world webpages into clean, standardized HTML while maintaining diverse visual designs and avoiding copyright issues. Extensive testing of state-of-the-art MLLMs reveals significant limitations in page perception, code generation (particularly for image handling and layout), and interaction implementation. Our results quantitatively demonstrate performance disparities across models and tasks, and highlight a substantial gap between current MLLM capabilities and human expert performance in front-end engineering. The FullFront benchmark and code are available in https://github.com/Mikivishy/FullFront.
GCAL: Adapting Graph Models to Evolving Domain Shifts
May 22, 2025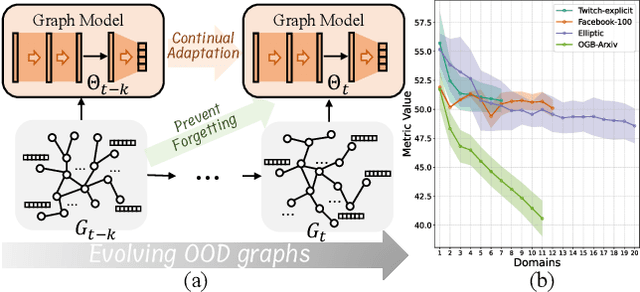
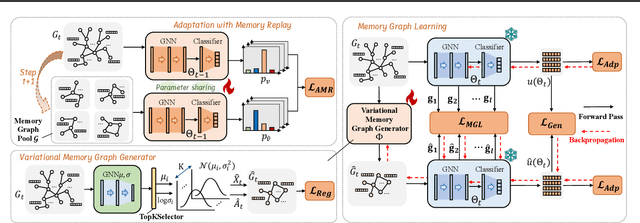
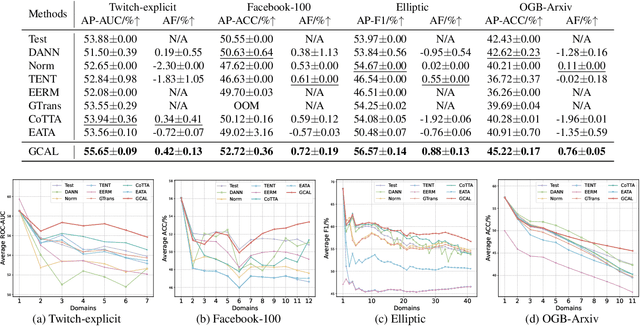
This paper addresses the challenge of graph domain adaptation on evolving, multiple out-of-distribution (OOD) graphs. Conventional graph domain adaptation methods are confined to single-step adaptation, making them ineffective in handling continuous domain shifts and prone to catastrophic forgetting. This paper introduces the Graph Continual Adaptive Learning (GCAL) method, designed to enhance model sustainability and adaptability across various graph domains. GCAL employs a bilevel optimization strategy. The "adapt" phase uses an information maximization approach to fine-tune the model with new graph domains while re-adapting past memories to mitigate forgetting. Concurrently, the "generate memory" phase, guided by a theoretical lower bound derived from information bottleneck theory, involves a variational memory graph generation module to condense original graphs into memories. Extensive experimental evaluations demonstrate that GCAL substantially outperforms existing methods in terms of adaptability and knowledge retention.
FreshRetailNet-50K: A Stockout-Annotated Censored Demand Dataset for Latent Demand Recovery and Forecasting in Fresh Retail
May 22, 2025



Accurate demand estimation is critical for the retail business in guiding the inventory and pricing policies of perishable products. However, it faces fundamental challenges from censored sales data during stockouts, where unobserved demand creates systemic policy biases. Existing datasets lack the temporal resolution and annotations needed to address this censoring effect. To fill this gap, we present FreshRetailNet-50K, the first large-scale benchmark for censored demand estimation. It comprises 50,000 store-product time series of detailed hourly sales data from 898 stores in 18 major cities, encompassing 863 perishable SKUs meticulously annotated for stockout events. The hourly stock status records unique to this dataset, combined with rich contextual covariates, including promotional discounts, precipitation, and temporal features, enable innovative research beyond existing solutions. We demonstrate one such use case of two-stage demand modeling: first, we reconstruct the latent demand during stockouts using precise hourly annotations. We then leverage the recovered demand to train robust demand forecasting models in the second stage. Experimental results show that this approach achieves a 2.73\% improvement in prediction accuracy while reducing the systematic demand underestimation from 7.37\% to near-zero bias. With unprecedented temporal granularity and comprehensive real-world information, FreshRetailNet-50K opens new research directions in demand imputation, perishable inventory optimization, and causal retail analytics. The unique annotation quality and scale of the dataset address long-standing limitations in retail AI, providing immediate solutions and a platform for future methodological innovation. The data (https://huggingface.co/datasets/Dingdong-Inc/FreshRetailNet-50K) and code (https://github.com/Dingdong-Inc/frn-50k-baseline}) are openly released.