 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre We Making Progress in Multimodal Domain Generalization? A Comprehensive Benchmark Study
May 07, 2026Despite the growing popularity of Multimodal Domain Generalization (MMDG) for enhancing model robustness, it remains unclear whether reported performance gains reflect genuine algorithmic progress or are artifacts of inconsistent evaluation protocols. Current research is fragmented, with studies varying significantly across datasets, modality configurations, and experimental settings. Furthermore, existing benchmarks focus predominantly on action recognition, often neglecting critical real-world challenges such as input corruptions, missing modalities, and model trustworthiness. This lack of standardization obscures a reliable assessment of the field's advancement. To address this issue, we introduce MMDG-Bench, the first unified and comprehensive benchmark for MMDG, which standardizes evaluation across six datasets spanning three diverse tasks: action recognition, mechanical fault diagnosis, and sentiment analysis. MMDG-Bench encompasses six modality combinations, nine representative methods, and multiple evaluation settings. Beyond standard accuracy, it systematically assesses corruption robustness, missing-modality generalization, misclassification detection, and out-of-distribution detection. With 7, 402 neural networks trained in total across 95 unique cross-domain tasks, MMDG-Bench yields five key findings: (1) under fair comparisons, recent specialized MMDG methods offer only marginal improvements over ERM baseline; (2) no single method consistently outperforms others across datasets or modality combinations; (3) a substantial gap to upper-bound performance persists, indicating that MMDG remains far from solved; (4) trimodal fusion does not consistently outperform the strongest bimodal configurations; and (5) all evaluated methods exhibit significant degradation under corruption and missing-modality scenarios, with some methods further compromising model trustworthiness.
Complex Equation Learner: Rational Symbolic Regression with Gradient Descent in Complex Domain
May 05, 2026Symbolic regression aims to discover interpretable equations from data, yet modern gradient-based methods fail for operators that introduce singularities or domain constraints, including division, logarithms, and square roots. As a result, Equation Learner-type models typically avoid these operators or impose restrictions, e.g. constraining denominators to prevent poles, which narrows the hypothesis class. We propose a complex weight extension of the Equation Learner that mitigates real-valued optimization pathologies by allowing optimization trajectories to bypass real-axis degeneracies. The proposed approach converges stably even when the target expression has real-domain poles, and it enables unconstrained use of operations such as logarithm and square root. We Validate the method on symbolic regression benchmarks and show it can recover singular behavior from experimental frequency response data.
Graph Signal Separation with Learnable Spectral Filters
Apr 27, 2026Separating multiple graph signals from a single observed mixture is an inherently ill-posed problem that traditionally relies on restrictive and handcrafted priors. This letter addresses this challenge by proposing an unsupervised learnable spectral filtering framework. Our approach reconstructs latent components by passing a fixed random input through learnable spectral filters, operating within the low-frequency eigenspace of each source-specific graph Laplacian. The architecture implicitly biases the recovered signals toward smooth patterns by confining reconstruction to these low-frequency subspaces. This acts as a structural prior, establishing a principled bridge between classical graph spectral analysis and modern neural decomposition. Numerical experiments confirm that this framework successfully isolates individual sources using solely the observed mixture and the underlying graph topology.
Virtual Smart Metering in District Heating Networks via Heterogeneous Spatial-Temporal Graph Neural Networks
Apr 11, 2026Intelligent operation of thermal energy networks aims to improve energy efficiency, reliability, and operational flexibility through data-driven control, predictive optimization, and early fault detection. Achieving these goals relies on sufficient observability, requiring continuous and well-distributed monitoring of thermal and hydraulic states. However, district heating systems are typically sparsely instrumented and frequently affected by sensor faults, limiting monitoring. Virtual sensing offers a cost-effective means to enhance observability, yet its development and validation remain limited in practice. Existing data-driven methods generally assume dense synchronized data, while analytical models rely on simplified hydraulic and thermal assumptions that may not adequately capture the behavior of heterogeneous network topologies. Consequently, modeling the coupled nonlinear dependencies between pressure, flow, and temperature under realistic operating conditions remains challenging. In addition, the lack of publicly available benchmark datasets hinders systematic comparison of virtual sensing approaches. To address these challenges, we propose a heterogeneous spatial-temporal graph neural network (HSTGNN) for constructing virtual smart heat meters. The model incorporates the functional relationships inherent in district heating networks and employs dedicated branches to learn graph structures and temporal dynamics for flow, temperature, and pressure measurements, thereby enabling the joint modeling of cross-variable and spatial correlations. To support further research, we introduce a controlled laboratory dataset collected at the Aalborg Smart Water Infrastructure Laboratory, providing synchronized high-resolution measurements representative of real operating conditions. Extensive experiments demonstrate that the proposed approach significantly outperforms existing baselines.
SEAR: Simple and Efficient Adaptation of Visual Geometric Transformers for RGB+Thermal 3D Reconstruction
Mar 19, 2026Foundational feed-forward visual geometry models enable accurate and efficient camera pose estimation and scene reconstruction by learning strong scene priors from massive RGB datasets. However, their effectiveness drops when applied to mixed sensing modalities, such as RGB-thermal (RGB-T) images. We observe that while a visual geometry grounded transformer pretrained on RGB data generalizes well to thermal-only reconstruction, it struggles to align RGB and thermal modalities when processed jointly. To address this, we propose SEAR, a simple yet efficient fine-tuning strategy that adapts a pretrained geometry transformer to multimodal RGB-T inputs. Despite being trained on a relatively small RGB-T dataset, our approach significantly outperforms state-of-the-art methods for 3D reconstruction and camera pose estimation, achieving significant improvements over all metrics (e.g., over 29\% in AUC@30) and delivering higher detail and consistency between modalities with negligible overhead in inference time compared to the original pretrained model. Notably, SEAR enables reliable multimodal pose estimation and reconstruction even under challenging conditions, such as low lighting and dense smoke. We validate our architecture through extensive ablation studies, demonstrating how the model aligns both modalities. Additionally, we introduce a new dataset featuring RGB and thermal sequences captured at different times, viewpoints, and illumination conditions, providing a robust benchmark for future work in multimodal 3D scene reconstruction. Code and models are publicly available at https://www.github.com/Schindler-EPFL-Lab/SEAR.
Adaptive Confidence Regularization for Multimodal Failure Detection
Mar 02, 2026The deployment of multimodal models in high-stakes domains, such as self-driving vehicles and medical diagnostics, demands not only strong predictive performance but also reliable mechanisms for detecting failures. In this work, we address the largely unexplored problem of failure detection in multimodal contexts. We propose Adaptive Confidence Regularization (ACR), a novel framework specifically designed to detect multimodal failures. Our approach is driven by a key observation: in most failure cases, the confidence of the multimodal prediction is significantly lower than that of at least one unimodal branch, a phenomenon we term confidence degradation. To mitigate this, we introduce an Adaptive Confidence Loss that penalizes such degradations during training. In addition, we propose Multimodal Feature Swapping, a novel outlier synthesis technique that generates challenging, failure-aware training examples. By training with these synthetic failures, ACR learns to more effectively recognize and reject uncertain predictions, thereby improving overall reliability. Extensive experiments across four datasets, three modalities, and multiple evaluation settings demonstrate that ACR achieves consistent and robust gains. The source code will be available at https://github.com/mona4399/ACR.
Multimodal Learning for Arcing Detection in Pantograph-Catenary Systems
Feb 09, 2026The pantograph-catenary interface is essential for ensuring uninterrupted and reliable power delivery in electrified rail systems. However, electrical arcing at this interface poses serious risks, including accelerated wear of contact components, degraded system performance, and potential service disruptions. Detecting arcing events at the pantograph-catenary interface is challenging due to their transient nature, noisy operating environment, data scarcity, and the difficulty of distinguishing arcs from other similar transient phenomena. To address these challenges, we propose a novel multimodal framework that combines high-resolution image data with force measurements to more accurately and robustly detect arcing events. First, we construct two arcing detection datasets comprising synchronized visual and force measurements. One dataset is built from data provided by the Swiss Federal Railways (SBB), and the other is derived from publicly available videos of arcing events in different railway systems and synthetic force data that mimic the characteristics observed in the real dataset. Leveraging these datasets, we propose MultiDeepSAD, an extension of the DeepSAD algorithm for multiple modalities with a new loss formulation. Additionally, we introduce tailored pseudo-anomaly generation techniques specific to each data type, such as synthetic arc-like artifacts in images and simulated force irregularities, to augment training data and improve the discriminative ability of the model. Through extensive experiments and ablation studies, we demonstrate that our framework significantly outperforms baseline approaches, exhibiting enhanced sensitivity to real arcing events even under domain shifts and limited availability of real arcing observations.
Time-Vertex Machine Learning for Optimal Sensor Placement in Temporal Graph Signals: Applications in Structural Health Monitoring
Dec 22, 2025Structural Health Monitoring (SHM) plays a crucial role in maintaining the safety and resilience of infrastructure. As sensor networks grow in scale and complexity, identifying the most informative sensors becomes essential to reduce deployment costs without compromising monitoring quality. While Graph Signal Processing (GSP) has shown promise by leveraging spatial correlations among sensor nodes, conventional approaches often overlook the temporal dynamics of structural behavior. To overcome this limitation, we propose Time-Vertex Machine Learning (TVML), a novel framework that integrates GSP, time-domain analysis, and machine learning to enable interpretable and efficient sensor placement by identifying representative nodes that minimize redundancy while preserving critical information. We evaluate the proposed approach on two bridge datasets for damage detection and time-varying graph signal reconstruction tasks. The results demonstrate the effectiveness of our approach in enhancing SHM systems by providing a robust, adaptive, and efficient solution for sensor placement.
Adapting Vision-Language Models Without Labels: A Comprehensive Survey
Aug 07, 2025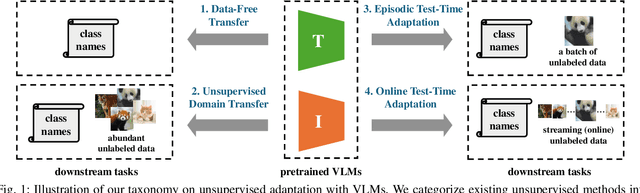
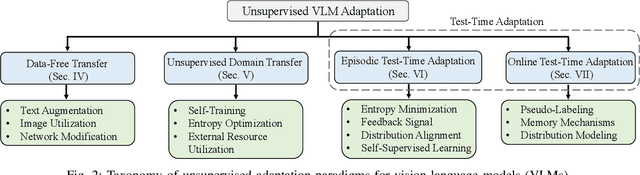
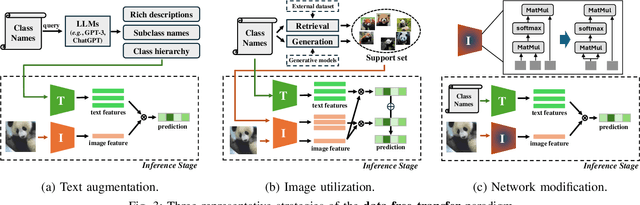
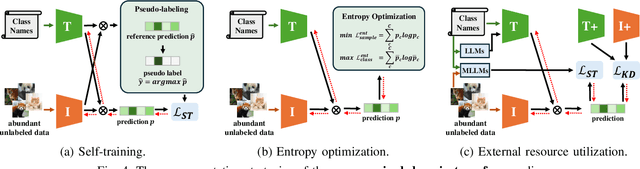
Vision-Language Models (VLMs) have demonstrated remarkable generalization capabilities across a wide range of tasks. However, their performance often remains suboptimal when directly applied to specific downstream scenarios without task-specific adaptation. To enhance their utility while preserving data efficiency, recent research has increasingly focused on unsupervised adaptation methods that do not rely on labeled data. Despite the growing interest in this area, there remains a lack of a unified, task-oriented survey dedicated to unsupervised VLM adaptation. To bridge this gap, we present a comprehensive and structured overview of the field. We propose a taxonomy based on the availability and nature of unlabeled visual data, categorizing existing approaches into four key paradigms: Data-Free Transfer (no data), Unsupervised Domain Transfer (abundant data), Episodic Test-Time Adaptation (batch data), and Online Test-Time Adaptation (streaming data). Within this framework, we analyze core methodologies and adaptation strategies associated with each paradigm, aiming to establish a systematic understanding of the field. Additionally, we review representative benchmarks across diverse applications and highlight open challenges and promising directions for future research. An actively maintained repository of relevant literature is available at https://github.com/tim-learn/Awesome-LabelFree-VLMs.
Integrating Physics-Based and Data-Driven Approaches for Probabilistic Building Energy Modeling
Jul 23, 2025Building energy modeling is a key tool for optimizing the performance of building energy systems. Historically, a wide spectrum of methods has been explored -- ranging from conventional physics-based models to purely data-driven techniques. Recently, hybrid approaches that combine the strengths of both paradigms have gained attention. These include strategies such as learning surrogates for physics-based models, modeling residuals between simulated and observed data, fine-tuning surrogates with real-world measurements, using physics-based outputs as additional inputs for data-driven models, and integrating the physics-based output into the loss function the data-driven model. Despite this progress, two significant research gaps remain. First, most hybrid methods focus on deterministic modeling, often neglecting the inherent uncertainties caused by factors like weather fluctuations and occupant behavior. Second, there has been little systematic comparison within a probabilistic modeling framework. This study addresses these gaps by evaluating five representative hybrid approaches for probabilistic building energy modeling, focusing on quantile predictions of building thermodynamics in a real-world case study. Our results highlight two main findings. First, the performance of hybrid approaches varies across different building room types, but residual learning with a Feedforward Neural Network performs best on average. Notably, the residual approach is the only model that produces physically intuitive predictions when applied to out-of-distribution test data. Second, Quantile Conformal Prediction is an effective procedure for calibrating quantile predictions in case of indoor temperature modeling.