 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep (Predictive) Discounted Counterfactual Regret Minimization
Nov 11, 2025Counterfactual regret minimization (CFR) is a family of algorithms for effectively solving imperfect-information games. To enhance CFR's applicability in large games, researchers use neural networks to approximate its behavior. However, existing methods are mainly based on vanilla CFR and struggle to effectively integrate more advanced CFR variants. In this work, we propose an efficient model-free neural CFR algorithm, overcoming the limitations of existing methods in approximating advanced CFR variants. At each iteration, it collects variance-reduced sampled advantages based on a value network, fits cumulative advantages by bootstrapping, and applies discounting and clipping operations to simulate the update mechanisms of advanced CFR variants. Experimental results show that, compared with model-free neural algorithms, it exhibits faster convergence in typical imperfect-information games and demonstrates stronger adversarial performance in a large poker game.
Towards Proprioception-Aware Embodied Planning for Dual-Arm Humanoid Robots
Oct 09, 2025



In recent years, Multimodal Large Language Models (MLLMs) have demonstrated the ability to serve as high-level planners, enabling robots to follow complex human instructions. However, their effectiveness, especially in long-horizon tasks involving dual-arm humanoid robots, remains limited. This limitation arises from two main challenges: (i) the absence of simulation platforms that systematically support task evaluation and data collection for humanoid robots, and (ii) the insufficient embodiment awareness of current MLLMs, which hinders reasoning about dual-arm selection logic and body positions during planning. To address these issues, we present DualTHOR, a new dual-arm humanoid simulator, with continuous transition and a contingency mechanism. Building on this platform, we propose Proprio-MLLM, a model that enhances embodiment awareness by incorporating proprioceptive information with motion-based position embedding and a cross-spatial encoder. Experiments show that, while existing MLLMs struggle in this environment, Proprio-MLLM achieves an average improvement of 19.75% in planning performance. Our work provides both an essential simulation platform and an effective model to advance embodied intelligence in humanoid robotics. The code is available at https://anonymous.4open.science/r/DualTHOR-5F3B.
Aligning Perception, Reasoning, Modeling and Interaction: A Survey on Physical AI
Oct 06, 2025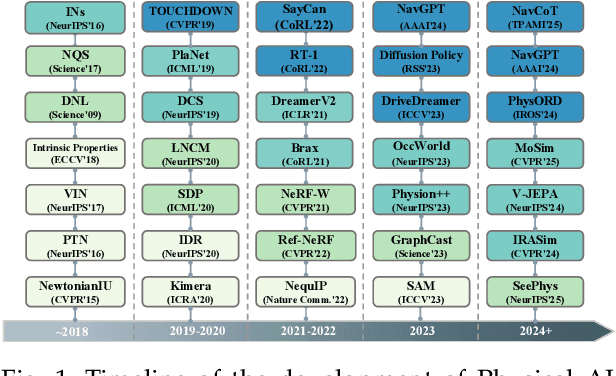
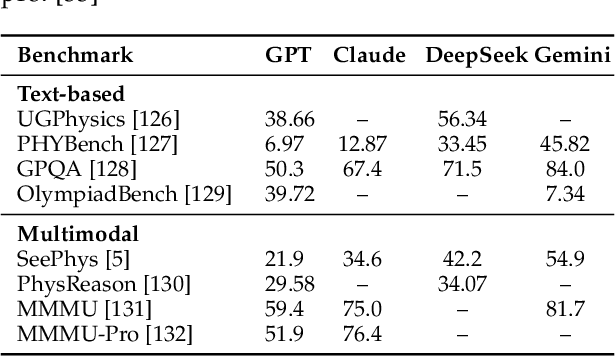
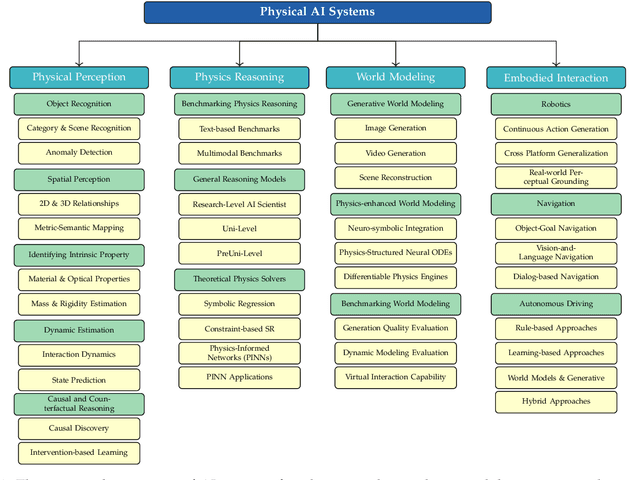
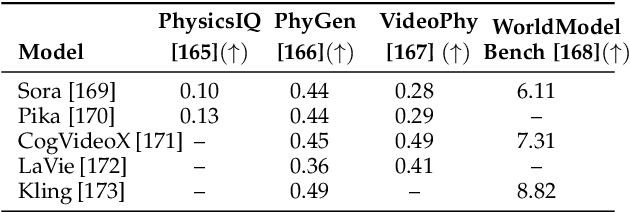
The rapid advancement of embodied intelligence and world models has intensified efforts to integrate physical laws into AI systems, yet physical perception and symbolic physics reasoning have developed along separate trajectories without a unified bridging framework. This work provides a comprehensive overview of physical AI, establishing clear distinctions between theoretical physics reasoning and applied physical understanding while systematically examining how physics-grounded methods enhance AI's real-world comprehension across structured symbolic reasoning, embodied systems, and generative models. Through rigorous analysis of recent advances, we advocate for intelligent systems that ground learning in both physical principles and embodied reasoning processes, transcending pattern recognition toward genuine understanding of physical laws. Our synthesis envisions next-generation world models capable of explaining physical phenomena and predicting future states, advancing safe, generalizable, and interpretable AI systems. We maintain a continuously updated resource at https://github.com/AI4Phys/Awesome-AI-for-Physics.
RTFF: Random-to-Target Fabric Flattening Policy using Dual-Arm Manipulator
Oct 01, 2025Robotic fabric manipulation in garment production for sewing, cutting, and ironing requires reliable flattening and alignment, yet remains challenging due to fabric deformability, effectively infinite degrees of freedom, and frequent occlusions from wrinkles, folds, and the manipulator's End-Effector (EE) and arm. To address these issues, this paper proposes the first Random-to-Target Fabric Flattening (RTFF) policy, which aligns a random wrinkled fabric state to an arbitrary wrinkle-free target state. The proposed policy adopts a hybrid Imitation Learning-Visual Servoing (IL-VS) framework, where IL learns with explicit fabric models for coarse alignment of the wrinkled fabric toward a wrinkle-free state near the target, and VS ensures fine alignment to the target. Central to this framework is a template-based mesh that offers precise target state representation, wrinkle-aware geometry prediction, and consistent vertex correspondence across RTFF manipulation steps, enabling robust manipulation and seamless IL-VS switching. Leveraging the power of mesh, a novel IL solution for RTFF-Mesh Action Chunking Transformer (MACT)-is then proposed by conditioning the mesh information into a Transformer-based policy. The RTFF policy is validated on a real dual-arm tele-operation system, showing zero-shot alignment to different targets, high accuracy, and strong generalization across fabrics and scales. Project website: https://kaitang98.github.io/RTFF_Policy/
Repeating Words for Video-Language Retrieval with Coarse-to-Fine Objectives
Aug 20, 2025The explosive growth of video streaming presents challenges in achieving high accuracy and low training costs for video-language retrieval. However, existing methods rely on large-scale pre-training to improve video retrieval performance, resulting in significant computational demands. Additionally, the fine-grained information in videos and texts remains underexplored. To alleviate these problems, we propose a novel framework to learn fine-grained features for better alignment and introduce an inference pipeline to improve performance without additional training. Specifically, we employ coarse-to-fine objectives to understand the semantic information of video-text pairs, including contrastive and matching learning. The fine-grained data used for training is obtained through the Granularity-Aware Representation module, which is designed based on similarity analysis between video frames and words in captions. Furthermore, we observe that the repetition of keywords in the original captions, referred to as "Repetition", can enhance retrieval performance and improve alignment between video and text. Based on this insight, we propose a novel and effective inference pipeline that incorporates a voting mechanism and a new Matching Entropy metric to achieve better retrieval performance without requiring additional pre-training. Experimental results on four benchmarks demonstrate that the proposed method outperforms previous approaches. Additionally, our inference pipeline achieves significant performance improvements, with a 2.1% increase in Recall@1 on the MSR-VTT dataset and a 1.6% increase on the DiDeMo dataset.
KFFocus: Highlighting Keyframes for Enhanced Video Understanding
Aug 12, 2025



Recently, with the emergence of large language models, multimodal LLMs have demonstrated exceptional capabilities in image and video modalities. Despite advancements in video comprehension, the substantial computational demands of long video sequences lead current video LLMs (Vid-LLMs) to employ compression strategies at both the inter-frame level (e.g., uniform sampling of video frames) and intra-frame level (e.g., condensing all visual tokens of each frame into a limited number). However, this approach often neglects the uneven temporal distribution of critical information across frames, risking the omission of keyframes that contain essential temporal and semantic details. To tackle these challenges, we propose KFFocus, a method designed to efficiently compress video tokens and emphasize the informative context present within video frames. We substitute uniform sampling with a refined approach inspired by classic video compression principles to identify and capture keyframes based on their temporal redundancy. By assigning varying condensation ratios to frames based on their contextual relevance, KFFocus efficiently reduces token redundancy while preserving informative content details. Additionally, we introduce a spatiotemporal modeling module that encodes both the temporal relationships between video frames and the spatial structure within each frame, thus providing Vid-LLMs with a nuanced understanding of spatial-temporal dynamics. Extensive experiments on widely recognized video understanding benchmarks, especially long video scenarios, demonstrate that KFFocus significantly outperforms existing methods, achieving substantial computational efficiency and enhanced accuracy.
Direct Dual-Energy CT Material Decomposition using Model-based Denoising Diffusion Model
Jul 24, 2025



Dual-energy X-ray Computed Tomography (DECT) constitutes an advanced technology which enables automatic decomposition of materials in clinical images without manual segmentation using the dependency of the X-ray linear attenuation with energy. However, most methods perform material decomposition in the image domain as a post-processing step after reconstruction but this procedure does not account for the beam-hardening effect and it results in sub-optimal results. In this work, we propose a deep learning procedure called Dual-Energy Decomposition Model-based Diffusion (DEcomp-MoD) for quantitative material decomposition which directly converts the DECT projection data into material images. The algorithm is based on incorporating the knowledge of the spectral DECT model into the deep learning training loss and combining a score-based denoising diffusion learned prior in the material image domain. Importantly the inference optimization loss takes as inputs directly the sinogram and converts to material images through a model-based conditional diffusion model which guarantees consistency of the results. We evaluate the performance with both quantitative and qualitative estimation of the proposed DEcomp-MoD method on synthetic DECT sinograms from the low-dose AAPM dataset. Finally, we show that DEcomp-MoD outperform state-of-the-art unsupervised score-based model and supervised deep learning networks, with the potential to be deployed for clinical diagnosis.
C2-Evo: Co-Evolving Multimodal Data and Model for Self-Improving Reasoning
Jul 22, 2025



Recent advances in multimodal large language models (MLLMs) have shown impressive reasoning capabilities. However, further enhancing existing MLLMs necessitates high-quality vision-language datasets with carefully curated task complexities, which are both costly and challenging to scale. Although recent self-improving models that iteratively refine themselves offer a feasible solution, they still suffer from two core challenges: (i) most existing methods augment visual or textual data separately, resulting in discrepancies in data complexity (e.g., over-simplified diagrams paired with redundant textual descriptions); and (ii) the evolution of data and models is also separated, leading to scenarios where models are exposed to tasks with mismatched difficulty levels. To address these issues, we propose C2-Evo, an automatic, closed-loop self-improving framework that jointly evolves both training data and model capabilities. Specifically, given a base dataset and a base model, C2-Evo enhances them by a cross-modal data evolution loop and a data-model evolution loop. The former loop expands the base dataset by generating complex multimodal problems that combine structured textual sub-problems with iteratively specified geometric diagrams, while the latter loop adaptively selects the generated problems based on the performance of the base model, to conduct supervised fine-tuning and reinforcement learning alternately. Consequently, our method continuously refines its model and training data, and consistently obtains considerable performance gains across multiple mathematical reasoning benchmarks. Our code, models, and datasets will be released.
ECCV 2024 W-CODA: 1st Workshop on Multimodal Perception and Comprehension of Corner Cases in Autonomous Driving
Jul 02, 2025
In this paper, we present details of the 1st W-CODA workshop, held in conjunction with the ECCV 2024. W-CODA aims to explore next-generation solutions for autonomous driving corner cases, empowered by state-of-the-art multimodal perception and comprehension techniques. 5 Speakers from both academia and industry are invited to share their latest progress and opinions. We collect research papers and hold a dual-track challenge, including both corner case scene understanding and generation. As the pioneering effort, we will continuously bridge the gap between frontier autonomous driving techniques and fully intelligent, reliable self-driving agents robust towards corner cases.
SViP: Sequencing Bimanual Visuomotor Policies with Object-Centric Motion Primitives
Jun 23, 2025Imitation learning (IL), particularly when leveraging high-dimensional visual inputs for policy training, has proven intuitive and effective in complex bimanual manipulation tasks. Nonetheless, the generalization capability of visuomotor policies remains limited, especially when small demonstration datasets are available. Accumulated errors in visuomotor policies significantly hinder their ability to complete long-horizon tasks. To address these limitations, we propose SViP, a framework that seamlessly integrates visuomotor policies into task and motion planning (TAMP). SViP partitions human demonstrations into bimanual and unimanual operations using a semantic scene graph monitor. Continuous decision variables from the key scene graph are employed to train a switching condition generator. This generator produces parameterized scripted primitives that ensure reliable performance even when encountering out-of-the-distribution observations. Using only 20 real-world demonstrations, we show that SViP enables visuomotor policies to generalize across out-of-distribution initial conditions without requiring object pose estimators. For previously unseen tasks, SViP automatically discovers effective solutions to achieve the goal, leveraging constraint modeling in TAMP formulism. In real-world experiments, SViP outperforms state-of-the-art generative IL methods, indicating wider applicability for more complex tasks. Project website: https://sites.google.com/view/svip-bimanual