 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECCV 2024 W-CODA: 1st Workshop on Multimodal Perception and Comprehension of Corner Cases in Autonomous Driving
Jul 02, 2025
In this paper, we present details of the 1st W-CODA workshop, held in conjunction with the ECCV 2024. W-CODA aims to explore next-generation solutions for autonomous driving corner cases, empowered by state-of-the-art multimodal perception and comprehension techniques. 5 Speakers from both academia and industry are invited to share their latest progress and opinions. We collect research papers and hold a dual-track challenge, including both corner case scene understanding and generation. As the pioneering effort, we will continuously bridge the gap between frontier autonomous driving techniques and fully intelligent, reliable self-driving agents robust towards corner cases.
Beyond Calibration: Physically Informed Learning for Raw-to-Raw Mapping
Jun 11, 2025


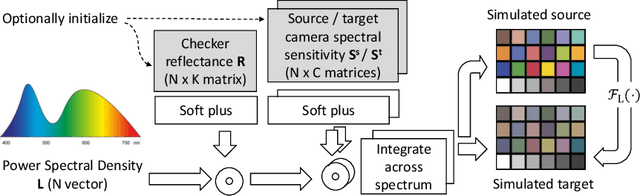
Achieving consistent color reproduction across multiple cameras is essential for seamless image fusion and Image Processing Pipeline (ISP) compatibility in modern devices, but it is a challenging task due to variations in sensors and optics. Existing raw-to-raw conversion methods face limitations such as poor adaptability to changing illumination, high computational costs, or impractical requirements such as simultaneous camera operation and overlapping fields-of-view. We introduce the Neural Physical Model (NPM), a lightweight, physically-informed approach that simulates raw images under specified illumination to estimate transformations between devices. The NPM effectively adapts to varying illumination conditions, can be initialized with physical measurements, and supports training with or without paired data. Experiments on public datasets like NUS and BeyondRGB demonstrate that NPM outperforms recent state-of-the-art methods, providing robust chromatic consistency across different sensors and optical systems.
Burst Image Super-Resolution with Mamba
Mar 25, 2025



Burst image super-resolution (BISR) aims to enhance the resolution of a keyframe by leveraging information from multiple low-resolution images captured in quick succession. In the deep learning era, BISR methods have evolved from fully convolutional networks to transformer-based architectures, which, despite their effectiveness, suffer from the quadratic complexity of self-attention. We see Mamba as the next natural step in the evolution of this field, offering a comparable global receptive field and selective information routing with only linear time complexity. In this work, we introduce BurstMamba, a Mamba-based architecture for BISR. Our approach decouples the task into two specialized branches: a spatial module for keyframe super-resolution and a temporal module for subpixel prior extraction, striking a balance between computational efficiency and burst information integration. To further enhance burst processing with Mamba, we propose two novel strategies: (i) optical flow-based serialization, which aligns burst sequences only during state updates to preserve subpixel details, and (ii) a wavelet-based reparameterization of the state-space update rules, prioritizing high-frequency features for improved burst-to-keyframe information passing. Our framework achieves SOTA performance on public benchmarks of SyntheticSR, RealBSR-RGB, and RealBSR-RAW.
Test-time Training for Hyperspectral Image Super-resolution
Sep 13, 2024



The progress on Hyperspectral image (HSI) super-resolution (SR) is still lagging behind the research of RGB image SR. HSIs usually have a high number of spectral bands, so accurately modeling spectral band interaction for HSI SR is hard. Also, training data for HSI SR is hard to obtain so the dataset is usually rather small. In this work, we propose a new test-time training method to tackle this problem. Specifically, a novel self-training framework is developed, where more accurate pseudo-labels and more accurate LR-HR relationships are generated so that the model can be further trained with them to improve performance. In order to better support our test-time training method, we also propose a new network architecture to learn HSI SR without modeling spectral band interaction and propose a new data augmentation method Spectral Mixup to increase the diversity of the training data at test time. We also collect a new HSI dataset with a diverse set of images of interesting objects ranging from food to vegetation, to materials, and to general scenes. Extensive experiments on multiple datasets show that our method can improve the performance of pre-trained models significantly after test-time training and outperform competing methods significantly for HSI SR.
MICDrop: Masking Image and Depth Features via Complementary Dropout for Domain-Adaptive Semantic Segmentation
Aug 29, 2024



Unsupervised Domain Adaptation (UDA) is the task of bridging the domain gap between a labeled source domain, e.g., synthetic data, and an unlabeled target domain. We observe that current UDA methods show inferior results on fine structures and tend to oversegment objects with ambiguous appearance. To address these shortcomings, we propose to leverage geometric information, i.e., depth predictions, as depth discontinuities often coincide with segmentation boundaries. We show that naively incorporating depth into current UDA methods does not fully exploit the potential of this complementary information. To this end, we present MICDrop, which learns a joint feature representation by masking image encoder features while inversely masking depth encoder features. With this simple yet effective complementary masking strategy, we enforce the use of both modalities when learning the joint feature representation. To aid this process, we propose a feature fusion module to improve both global as well as local information sharing while being robust to errors in the depth predictions. We show that our method can be plugged into various recent UDA methods and consistently improve results across standard UDA benchmarks, obtaining new state-of-the-art performances.
Forging Vision Foundation Models for Autonomous Driving: Challenges, Methodologies, and Opportunities
Jan 16, 2024



The rise of large foundation models, trained on extensive datasets, is revolutionizing the field of AI. Models such as SAM, DALL-E2, and GPT-4 showcase their adaptability by extracting intricate patterns and performing effectively across diverse tasks, thereby serving as potent building blocks for a wide range of AI applications. Autonomous driving, a vibrant front in AI applications, remains challenged by the lack of dedicated vision foundation models (VFMs). The scarcity of comprehensive training data, the need for multi-sensor integration, and the diverse task-specific architectures pose significant obstacles to the development of VFMs in this field. This paper delves into the critical challenge of forging VFMs tailored specifically for autonomous driving, while also outlining future directions. Through a systematic analysis of over 250 papers, we dissect essential techniques for VFM development, including data preparation, pre-training strategies, and downstream task adaptation. Moreover, we explore key advancements such as NeRF, diffusion models, 3D Gaussian Splatting, and world models, presenting a comprehensive roadmap for future research. To empower researchers, we have built and maintained https://github.com/zhanghm1995/Forge_VFM4AD, an open-access repository constantly updated with the latest advancements in forging VFMs for autonomous driving.
2D Feature Distillation for Weakly- and Semi-Supervised 3D Semantic Segmentation
Nov 27, 2023



As 3D perception problems grow in popularity and the need for large-scale labeled datasets for LiDAR semantic segmentation increase, new methods arise that aim to reduce the necessity for dense annotations by employing weakly-supervised training. However these methods continue to show weak boundary estimation and high false negative rates for small objects and distant sparse regions. We argue that such weaknesses can be compensated by using RGB images which provide a denser representation of the scene. We propose an image-guidance network (IGNet) which builds upon the idea of distilling high level feature information from a domain adapted synthetically trained 2D semantic segmentation network. We further utilize a one-way contrastive learning scheme alongside a novel mixing strategy called FOVMix, to combat the horizontal field-of-view mismatch between the two sensors and enhance the effects of image guidance. IGNet achieves state-of-the-art results for weakly-supervised LiDAR semantic segmentation on ScribbleKITTI, boasting up to 98% relative performance to fully supervised training with only 8% labeled points, while introducing no additional annotation burden or computational/memory cost during inference. Furthermore, we show that our contributions also prove effective for semi-supervised training, where IGNet claims state-of-the-art results on both ScribbleKITTI and SemanticKITTI.
SSB: Simple but Strong Baseline for Boosting Performance of Open-Set Semi-Supervised Learning
Nov 17, 2023



Semi-supervised learning (SSL) methods effectively leverage unlabeled data to improve model generalization. However, SSL models often underperform in open-set scenarios, where unlabeled data contain outliers from novel categories that do not appear in the labeled set. In this paper, we study the challenging and realistic open-set SSL setting, where the goal is to both correctly classify inliers and to detect outliers. Intuitively, the inlier classifier should be trained on inlier data only. However, we find that inlier classification performance can be largely improved by incorporating high-confidence pseudo-labeled data, regardless of whether they are inliers or outliers. Also, we propose to utilize non-linear transformations to separate the features used for inlier classification and outlier detection in the multi-task learning framework, preventing adverse effects between them. Additionally, we introduce pseudo-negative mining, which further boosts outlier detection performance. The three ingredients lead to what we call Simple but Strong Baseline (SSB) for open-set SSL. In experiments, SSB greatly improves both inlier classification and outlier detection performance, outperforming existing methods by a large margin. Our code will be released at https://github.com/YUE-FAN/SSB.
Object-centric Cross-modal Feature Distillation for Event-based Object Detection
Nov 09, 2023Event cameras are gaining popularity due to their unique properties, such as their low latency and high dynamic range. One task where these benefits can be crucial is real-time object detection. However, RGB detectors still outperform event-based detectors due to the sparsity of the event data and missing visual details. In this paper, we develop a novel knowledge distillation approach to shrink the performance gap between these two modalities. To this end, we propose a cross-modality object detection distillation method that by design can focus on regions where the knowledge distillation works best. We achieve this by using an object-centric slot attention mechanism that can iteratively decouple features maps into object-centric features and corresponding pixel-features used for distillation. We evaluate our novel distillation approach on a synthetic and a real event dataset with aligned grayscale images as a teacher modality. We show that object-centric distillation allows to significantly improve the performance of the event-based student object detector, nearly halving the performance gap with respect to the teacher.
U-BEV: Height-aware Bird's-Eye-View Segmentation and Neural Map-based Relocalization
Oct 20, 2023



Efficient relocalization is essential for intelligent vehicles when GPS reception is insufficient or sensor-based localization fails. Recent advances in Bird's-Eye-View (BEV) segmentation allow for accurate estimation of local scene appearance and in turn, can benefit the relocalization of the vehicle. However, one downside of BEV methods is the heavy computation required to leverage the geometric constraints. This paper presents U-BEV, a U-Net inspired architecture that extends the current state-of-the-art by allowing the BEV to reason about the scene on multiple height layers before flattening the BEV features. We show that this extension boosts the performance of the U-BEV by up to 4.11 IoU. Additionally, we combine the encoded neural BEV with a differentiable template matcher to perform relocalization on neural SD-map data. The model is fully end-to-end trainable and outperforms transformer-based BEV methods of similar computational complexity by 1.7 to 2.8 mIoU and BEV-based relocalization by over 26% Recall Accuracy on the nuScenes dataset.