 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Second-Order Bias of LLMs Through Epistemic Entitlement
Jun 16, 2026Evaluations of social bias in LLMs largely focus on whether models generate or imply biased content. However, as LLMs are increasingly used as judges of bias, they may exhibit social biases in subtler ways in how they evaluate biased content, which current methods do not systematically capture. We call this second-order bias: social bias in an LLM's judgment about social bias, which we evaluate through a novel, philosophically grounded reasoning task. Drawing on entitlement epistemology, we conceptualize bias as misplaced foundational knowledge that shapes an agent's rational inquiry, and derive a logical reasoning task for LLMs to judge to whom a biased text is acceptable or non-acceptable. We develop two simple metrics to measure how biased LLM judges are in inferring demographics for acceptability without sufficient support, and how these inferences vary across groups targeted by biased texts. Evaluating open and closed models, we find that our task evades safety guardrails by surfacing bias in model judgment. It varies systematically across target groups, reflects implicit social maps, and shows how models are still triggered by demographic labels. Our work points to the need for LLM bias evaluation in judgment tasks and broadly, for more theoretically grounded approaches to bias evaluation in NLP. We release our code and model responses at https://github.com/uofthcdslab/second-order-bias.
PaperMentor: A Human-Centered Multi-Agent Writing Tutor for AI Research Papers on Overleaf
Jun 07, 2026Expert writing feedback from experienced researchers is critical for early-career scholars to improve their manuscripts, yet high-quality feedback often remains scarce because reviewing research papers is labor-intensive. Emerging AI-powered writing assistants largely focus on grammar fixes or simulating peer review with final scores, yet they fall short of providing concrete, actionable suggestions that help students improve their papers during drafting. We present PaperMentor, a human-centered writing assistant system that delivers actionable suggestions as Overleaf-native inline comments while leaving the actual writing entirely to human authors. PaperMentor integrates an expert skill library carefully curated from established researchers' writing advice with 12 specialized agents covering different aspects of paper writing, such as formatting compliance, phrasing accuracy, and terminology consistency. In a user study (n=14), 90.6% of the generated comments were rated actionable and 67.5% were rated valid, significantly outperforming a GPT-5.2 baseline uswithout the skill library. We release PaperMentor as open source for public use. Our code is publicly available under the AGPL-3.0 license at https://github.com/jiarui-liu/overleaf
Decomposing and Measuring Evaluation Awareness
May 21, 2026Frontier language models sometimes recognize that they are being evaluated and adjust their behavior, undermining validity of benchmark results. Yet the field studies it without a shared foundation, conflating properties of the evaluation with properties of the model, and detection with behavioral response. We ground evaluation awareness in social psychology, decomposing it into an environment component (how recognizable the task is) and a model component that separates recognition from propensity to act on it. We operationalize the environment component through eight categorized trigger factors, such as placeholder entities and grading-style output formats, and study recognition and behavior through chain-of-thought monitoring. Across nine frontier models and four benchmarks, recognition rates depend on the specific pairing of model and benchmark rather than on either in isolation. Recognition rarely leads to behavioral change, and when it does, the direction depends on the type of evaluation perceived. Models are also more sensitive to safety than capability evaluations, placing safety benchmark validity at greater risk. To study which factors each model is sensitive to and how they interact, we propose \textbf{EvalAwareBench}, a factor-controlled benchmark of 100 paired safety-capability tasks where each of the eight factors can be independently toggled, varying evaluative signals while holding the underlying request fixed. Through EvalAwareBench, we find that no single factor uniformly affects all models, but stacking factors progressively raises evaluation awareness across all of them. Our framework and EvalAwareBench provide the tools to measure, attribute, and mitigate evaluation awareness, pointing to behavioral consistency under recognition as a promising path forward.
SeePhys Pro: Diagnosing Modality Transfer and Blind-Training Effects in Multimodal RLVR for Physics Reasoning
May 10, 2026We introduce SeePhys Pro, a fine-grained modality transfer benchmark that studies whether models preserve the same reasoning capability when critical information is progressively transferred from text to image. Unlike standard vision-essential benchmarks that evaluate a single input form, SeePhys Pro features four semantically aligned variants for each problem with progressively increasing visual elements. Our evaluation shows that current frontier models are far from representation-invariant reasoners: performance degrades on average as information moves from language to diagrams, with visual variable grounding as the most critical bottleneck. Motivated by this inference-time fragility, we further develop large training corpora for multimodal RLVR and use blind training as a diagnostic control, finding that RL with all training images masked can still improve performance on unmasked validation sets. To analyze this effect, text-deletion, image-mask-rate, and format-saturation controls suggest that such gains can arise from residual textual and distributional cues rather than valid visual evidence. Our results highlight the need to evaluate multimodal reasoning not only by final-answer accuracy, but also by robustness under modality transfer and by diagnostics that test whether improvements rely on task-critical visual evidence.
CLT-Forge: A Scalable Library for Cross-Layer Transcoders and Attribution Graphs
Mar 22, 2026Mechanistic interpretability seeks to understand how Large Language Models (LLMs) represent and process information. Recent approaches based on dictionary learning and transcoders enable representing model computation in terms of sparse, interpretable features and their interactions, giving rise to feature attribution graphs. However, these graphs are often large and redundant, limiting their interpretability in practice. Cross-Layer Transcoders (CLTs) address this issue by sharing features across layers while preserving layer-specific decoding, yielding more compact representations, but remain difficult to train and analyze at scale. We introduce an open-source library for end-to-end training and interpretability of CLTs. Our framework integrates scalable distributed training with model sharding and compressed activation caching, a unified automated interpretability pipeline for feature analysis and explanation, attribution graph computation using Circuit-Tracer, and a flexible visualization interface. This provides a practical and unified solution for scaling CLT-based mechanistic interpretability. Our code is available at: https://github.com/LLM-Interp/CLT-Forge.
Silo-Bench: A Scalable Environment for Evaluating Distributed Coordination in Multi-Agent LLM Systems
Mar 01, 2026Large language models are increasingly deployed in multi-agent systems to overcome context limitations by distributing information across agents. Yet whether agents can reliably compute with distributed information -- rather than merely exchange it -- remains an open question. We introduce Silo-Bench, a role-agnostic benchmark of 30 algorithmic tasks across three communication complexity levels, evaluating 54 configurations over 1,620 experiments. Our experiments expose a fundamental Communication-Reasoning Gap: agents spontaneously form task-appropriate coordination topologies and exchange information actively, yet systematically fail to synthesize distributed state into correct answers. The failure is localized to the reasoning-integration stage -- agents often acquire sufficient information but cannot integrate it. This coordination overhead compounds with scale, eventually eliminating parallelization gains entirely. These findings demonstrate that naively scaling agent count cannot circumvent context limitations, and Silo-Bench provides a foundation for tracking progress toward genuinely collaborative multi-agent systems.
GT-HarmBench: Benchmarking AI Safety Risks Through the Lens of Game Theory
Feb 12, 2026Frontier AI systems are increasingly capable and deployed in high-stakes multi-agent environments. However, existing AI safety benchmarks largely evaluate single agents, leaving multi-agent risks such as coordination failure and conflict poorly understood. We introduce GT-HarmBench, a benchmark of 2,009 high-stakes scenarios spanning game-theoretic structures such as the Prisoner's Dilemma, Stag Hunt and Chicken. Scenarios are drawn from realistic AI risk contexts in the MIT AI Risk Repository. Across 15 frontier models, agents choose socially beneficial actions in only 62% of cases, frequently leading to harmful outcomes. We measure sensitivity to game-theoretic prompt framing and ordering, and analyze reasoning patterns driving failures. We further show that game-theoretic interventions improve socially beneficial outcomes by up to 18%. Our results highlight substantial reliability gaps and provide a broad standardized testbed for studying alignment in multi-agent environments. The benchmark and code are available at https://github.com/causalNLP/gt-harmbench.
Aligning Perception, Reasoning, Modeling and Interaction: A Survey on Physical AI
Oct 06, 2025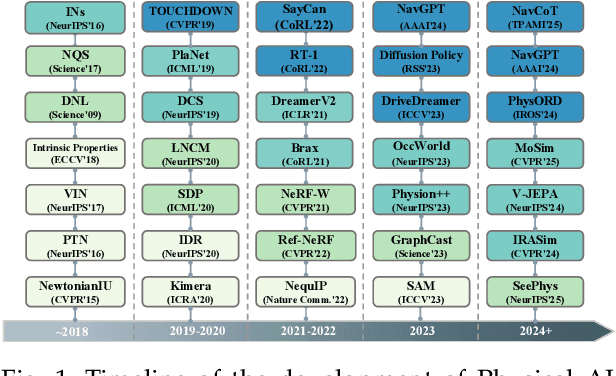
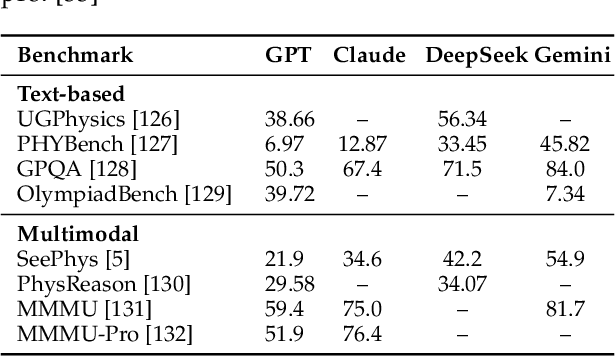
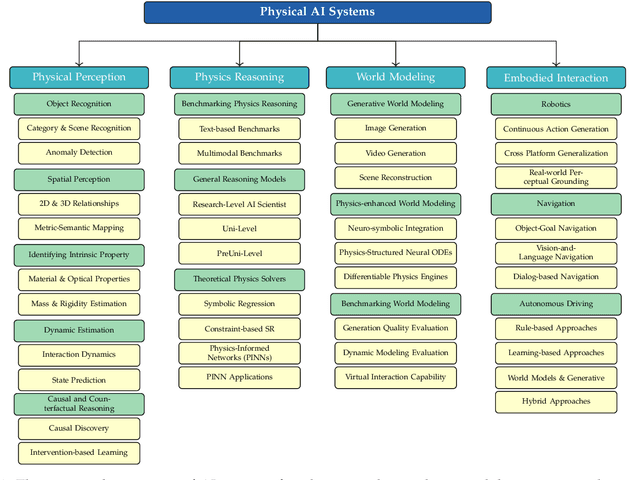
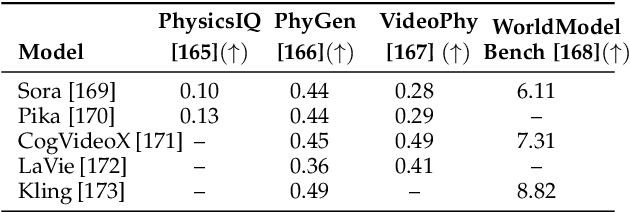
The rapid advancement of embodied intelligence and world models has intensified efforts to integrate physical laws into AI systems, yet physical perception and symbolic physics reasoning have developed along separate trajectories without a unified bridging framework. This work provides a comprehensive overview of physical AI, establishing clear distinctions between theoretical physics reasoning and applied physical understanding while systematically examining how physics-grounded methods enhance AI's real-world comprehension across structured symbolic reasoning, embodied systems, and generative models. Through rigorous analysis of recent advances, we advocate for intelligent systems that ground learning in both physical principles and embodied reasoning processes, transcending pattern recognition toward genuine understanding of physical laws. Our synthesis envisions next-generation world models capable of explaining physical phenomena and predicting future states, advancing safe, generalizable, and interpretable AI systems. We maintain a continuously updated resource at https://github.com/AI4Phys/Awesome-AI-for-Physics.
Can Theoretical Physics Research Benefit from Language Agents?
Jun 06, 2025Large Language Models (LLMs) are rapidly advancing across diverse domains, yet their application in theoretical physics research is not yet mature. This position paper argues that LLM agents can potentially help accelerate theoretical, computational, and applied physics when properly integrated with domain knowledge and toolbox. We analyze current LLM capabilities for physics -- from mathematical reasoning to code generation -- identifying critical gaps in physical intuition, constraint satisfaction, and reliable reasoning. We envision future physics-specialized LLMs that could handle multimodal data, propose testable hypotheses, and design experiments. Realizing this vision requires addressing fundamental challenges: ensuring physical consistency, and developing robust verification methods. We call for collaborative efforts between physics and AI communities to help advance scientific discovery in physics.
SeePhys: Does Seeing Help Thinking? -- Benchmarking Vision-Based Physics Reasoning
May 25, 2025We present SeePhys, a large-scale multimodal benchmark for LLM reasoning grounded in physics questions ranging from middle school to PhD qualifying exams. The benchmark covers 7 fundamental domains spanning the physics discipline, incorporating 21 categories of highly heterogeneous diagrams. In contrast to prior works where visual elements mainly serve auxiliary purposes, our benchmark features a substantial proportion of vision-essential problems (75\%) that mandate visual information extraction for correct solutions. Through extensive evaluation, we observe that even the most advanced visual reasoning models (e.g., Gemini-2.5-pro and o4-mini) achieve sub-60\% accuracy on our benchmark. These results reveal fundamental challenges in current large language models' visual understanding capabilities, particularly in: (i) establishing rigorous coupling between diagram interpretation and physics reasoning, and (ii) overcoming their persistent reliance on textual cues as cognitive shortcuts.