 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeePhys Pro: Diagnosing Modality Transfer and Blind-Training Effects in Multimodal RLVR for Physics Reasoning
May 10, 2026We introduce SeePhys Pro, a fine-grained modality transfer benchmark that studies whether models preserve the same reasoning capability when critical information is progressively transferred from text to image. Unlike standard vision-essential benchmarks that evaluate a single input form, SeePhys Pro features four semantically aligned variants for each problem with progressively increasing visual elements. Our evaluation shows that current frontier models are far from representation-invariant reasoners: performance degrades on average as information moves from language to diagrams, with visual variable grounding as the most critical bottleneck. Motivated by this inference-time fragility, we further develop large training corpora for multimodal RLVR and use blind training as a diagnostic control, finding that RL with all training images masked can still improve performance on unmasked validation sets. To analyze this effect, text-deletion, image-mask-rate, and format-saturation controls suggest that such gains can arise from residual textual and distributional cues rather than valid visual evidence. Our results highlight the need to evaluate multimodal reasoning not only by final-answer accuracy, but also by robustness under modality transfer and by diagnostics that test whether improvements rely on task-critical visual evidence.
Aligning Perception, Reasoning, Modeling and Interaction: A Survey on Physical AI
Oct 06, 2025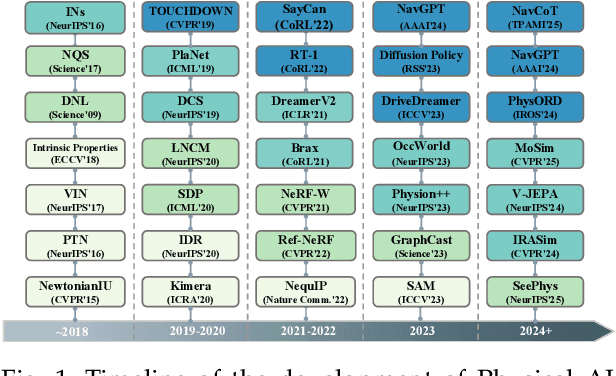
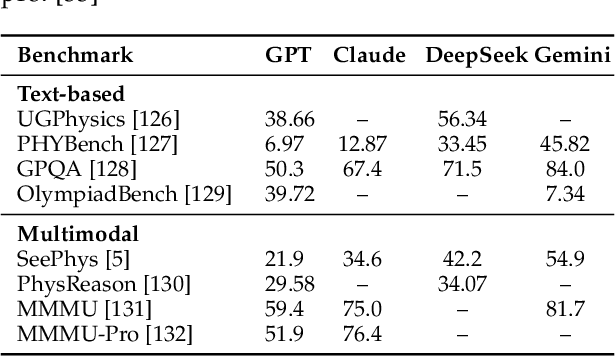
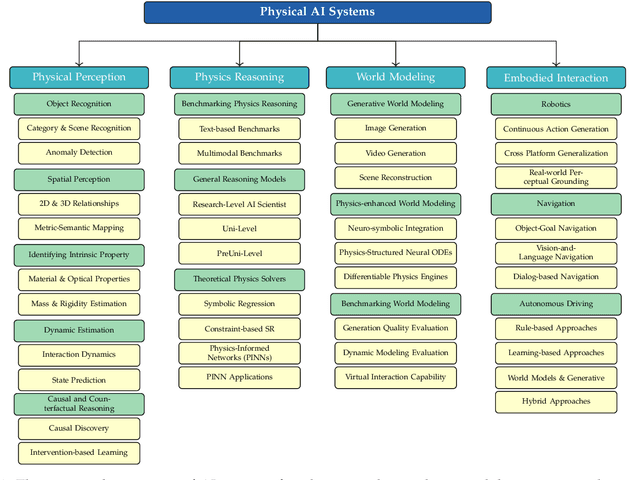
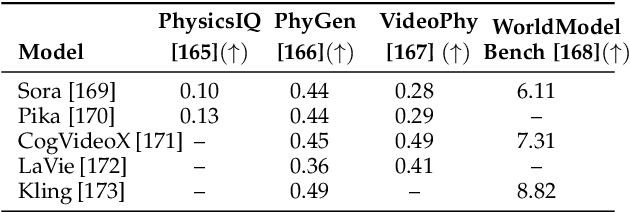
The rapid advancement of embodied intelligence and world models has intensified efforts to integrate physical laws into AI systems, yet physical perception and symbolic physics reasoning have developed along separate trajectories without a unified bridging framework. This work provides a comprehensive overview of physical AI, establishing clear distinctions between theoretical physics reasoning and applied physical understanding while systematically examining how physics-grounded methods enhance AI's real-world comprehension across structured symbolic reasoning, embodied systems, and generative models. Through rigorous analysis of recent advances, we advocate for intelligent systems that ground learning in both physical principles and embodied reasoning processes, transcending pattern recognition toward genuine understanding of physical laws. Our synthesis envisions next-generation world models capable of explaining physical phenomena and predicting future states, advancing safe, generalizable, and interpretable AI systems. We maintain a continuously updated resource at https://github.com/AI4Phys/Awesome-AI-for-Physics.
SeePhys: Does Seeing Help Thinking? -- Benchmarking Vision-Based Physics Reasoning
May 25, 2025We present SeePhys, a large-scale multimodal benchmark for LLM reasoning grounded in physics questions ranging from middle school to PhD qualifying exams. The benchmark covers 7 fundamental domains spanning the physics discipline, incorporating 21 categories of highly heterogeneous diagrams. In contrast to prior works where visual elements mainly serve auxiliary purposes, our benchmark features a substantial proportion of vision-essential problems (75\%) that mandate visual information extraction for correct solutions. Through extensive evaluation, we observe that even the most advanced visual reasoning models (e.g., Gemini-2.5-pro and o4-mini) achieve sub-60\% accuracy on our benchmark. These results reveal fundamental challenges in current large language models' visual understanding capabilities, particularly in: (i) establishing rigorous coupling between diagram interpretation and physics reasoning, and (ii) overcoming their persistent reliance on textual cues as cognitive shortcuts.
GlanceSeg: Real-time microaneurysm lesion segmentation with gaze-map-guided foundation model for early detection of diabetic retinopathy
Nov 14, 2023



Early-stage diabetic retinopathy (DR) presents challenges in clinical diagnosis due to inconspicuous and minute microangioma lesions, resulting in limited research in this area. Additionally, the potential of emerging foundation models, such as the segment anything model (SAM), in medical scenarios remains rarely explored. In this work, we propose a human-in-the-loop, label-free early DR diagnosis framework called GlanceSeg, based on SAM. GlanceSeg enables real-time segmentation of microangioma lesions as ophthalmologists review fundus images. Our human-in-the-loop framework integrates the ophthalmologist's gaze map, allowing for rough localization of minute lesions in fundus images. Subsequently, a saliency map is generated based on the located region of interest, which provides prompt points to assist the foundation model in efficiently segmenting microangioma lesions. Finally, a domain knowledge filter refines the segmentation of minute lesions. We conducted experiments on two newly-built public datasets, i.e., IDRiD and Retinal-Lesions, and validated the feasibility and superiority of GlanceSeg through visualized illustrations and quantitative measures. Additionally, we demonstrated that GlanceSeg improves annotation efficiency for clinicians and enhances segmentation performance through fine-tuning using annotations. This study highlights the potential of GlanceSeg-based annotations for self-model optimization, leading to enduring performance advancements through continual learning.