 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Multi-Turn Empathetic Dialogs with Positive Emotion Elicitation
Apr 22, 2022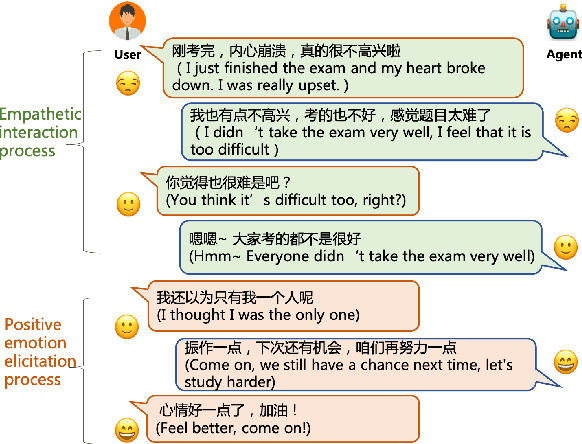
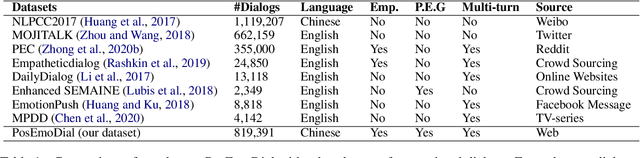

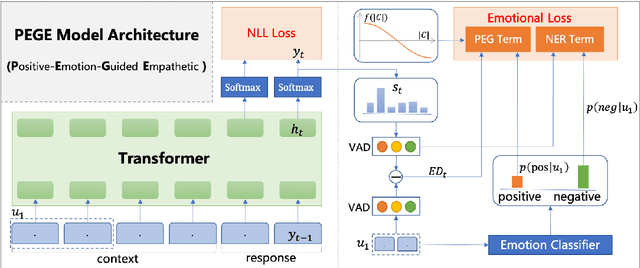
Emotional support is a crucial skill for many real-world scenarios, including caring for the elderly, mental health support, and customer service chats. This paper presents a novel task of empathetic dialog generation with positive emotion elicitation to promote users' positive emotions, similar to that of emotional support between humans. In this task, the agent conducts empathetic responses along with the target of eliciting the user's positive emotions in the multi-turn dialog. To facilitate the study of this task, we collect a large-scale emotional dialog dataset with positive emotion elicitation, called PosEmoDial (about 820k dialogs, 3M utterances). In these dialogs, the agent tries to guide the user from any possible initial emotional state, e.g., sadness, to a positive emotional state. Then we present a positive-emotion-guided dialog generation model with a novel loss function design. This loss function encourages the dialog model to not only elicit positive emotions from users but also ensure smooth emotional transitions along with the whole dialog. Finally, we establish benchmark results on PosEmoDial, and we will release this dataset and related source code to facilitate future studies.
Where to Go for the Holidays: Towards Mixed-Type Dialogs for Clarification of User Goals
Apr 15, 2022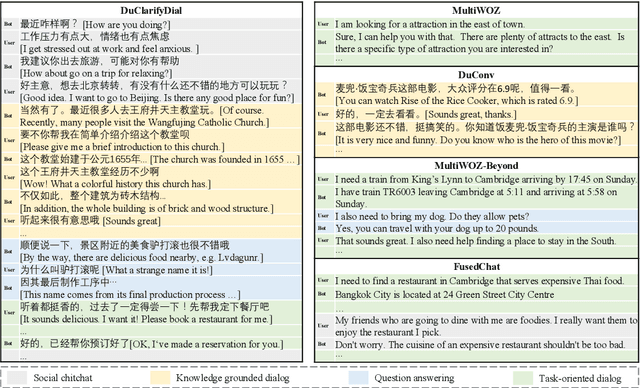

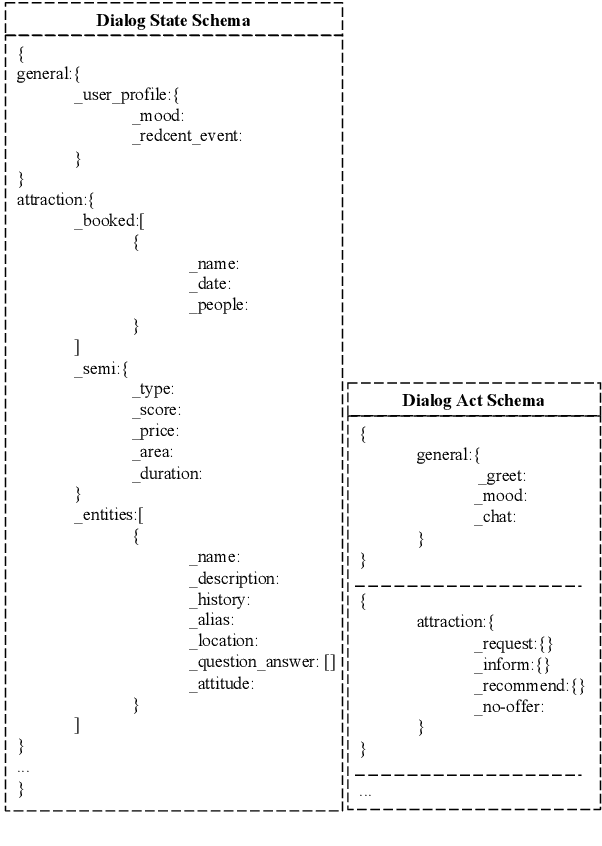
Most dialog systems posit that users have figured out clear and specific goals before starting an interaction. For example, users have determined the departure, the destination, and the travel time for booking a flight. However, in many scenarios, limited by experience and knowledge, users may know what they need, but still struggle to figure out clear and specific goals by determining all the necessary slots. In this paper, we identify this challenge and make a step forward by collecting a new human-to-human mixed-type dialog corpus. It contains 5k dialog sessions and 168k utterances for 4 dialog types and 5 domains. Within each session, an agent first provides user-goal-related knowledge to help figure out clear and specific goals, and then help achieve them. Furthermore, we propose a mixed-type dialog model with a novel Prompt-based continual learning mechanism. Specifically, the mechanism enables the model to continually strengthen its ability on any specific type by utilizing existing dialog corpora effectively.
ERNIE-GeoL: A Geography-and-Language Pre-trained Model and its Applications in Baidu Maps
Apr 06, 2022

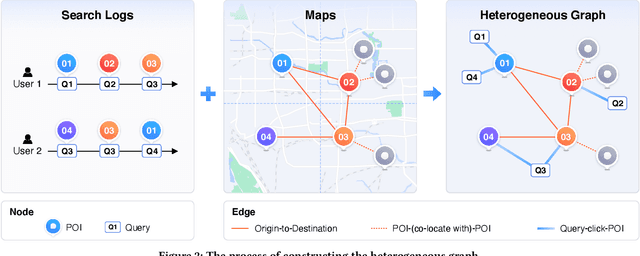
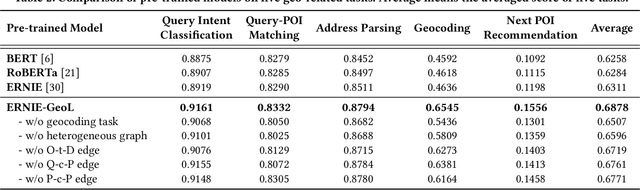
Pre-trained models (PTMs) have become a fundamental backbone for downstream tasks in natural language processing and computer vision. Despite initial gains that were obtained by applying generic PTMs to geo-related tasks at Baidu Maps, a clear performance plateau over time was observed. One of the main reasons for this plateau is the lack of readily available geographic knowledge in generic PTMs. To address this problem, in this paper, we present ERNIE-GeoL, which is a geography-and-language pre-trained model designed and developed for improving the geo-related tasks at Baidu Maps. ERNIE-GeoL is elaborately designed to learn a universal representation of geography-language by pre-training on large-scale data generated from a heterogeneous graph that contains abundant geographic knowledge. Extensive quantitative and qualitative experiments conducted on large-scale real-world datasets demonstrate the superiority and effectiveness of ERNIE-GeoL. ERNIE-GeoL has already been deployed in production at Baidu Maps since April 2021, which significantly benefits the performance of a wide range of downstream tasks. This demonstrates that ERNIE-GeoL can serve as a fundamental backbone for geo-related tasks.
Multi-Weight Respecification of Scan-specific Learning for Parallel Imaging
Apr 05, 2022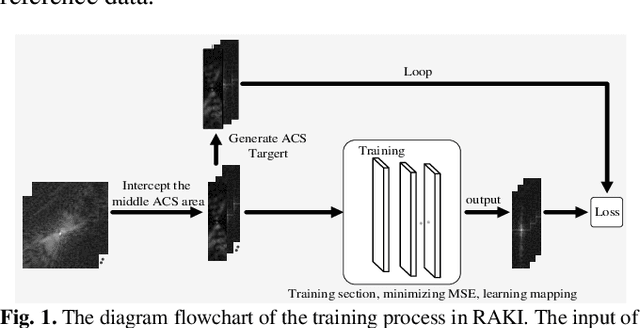
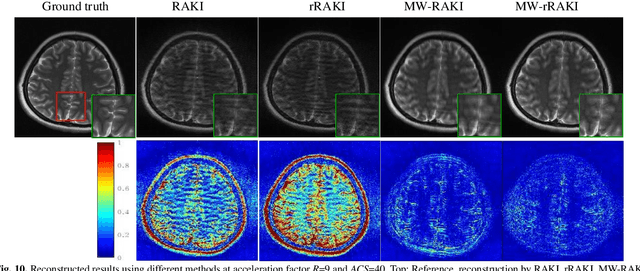
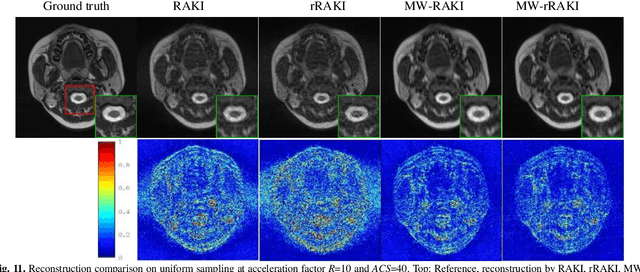
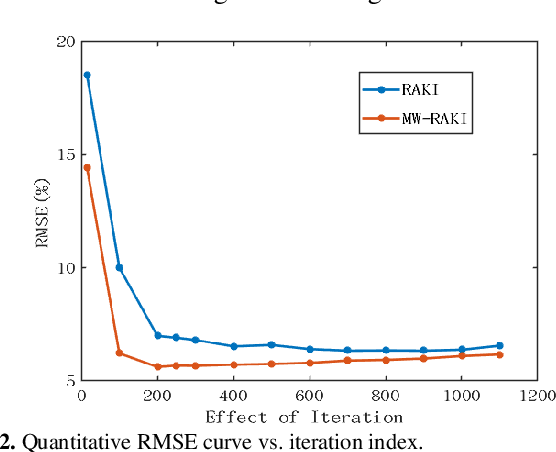
Parallel imaging is widely used in magnetic resonance imaging as an acceleration technology. Traditional linear reconstruction methods in parallel imaging often suffer from noise amplification. Recently, a non-linear robust artificial-neural-network for k-space interpolation (RAKI) exhibits superior noise resilience over other linear methods. However, RAKI performs poorly at high acceleration rates, and needs a large amount of autocalibration signals as the training samples. In order to tackle these issues, we propose a multi-weight method that implements multiple weighting matrices on the undersampled data, named as MW-RAKI. Enforcing multiple weighted matrices on the measurements can effectively reduce the influence of noise and increase the data constraints. Furthermore, we incorporate the strategy of multiple weighting matrixes into a residual version of RAKI, and form MW-rRAKI.Experimental compari-sons with the alternative methods demonstrated noticeably better reconstruction performances, particularly at high acceleration rates.
ERNIE-SPARSE: Learning Hierarchical Efficient Transformer Through Regularized Self-Attention
Mar 23, 2022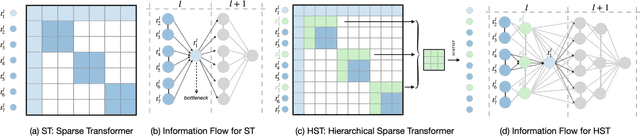
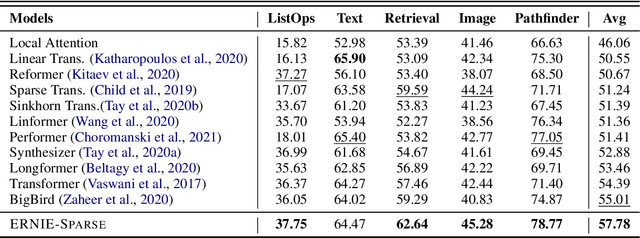
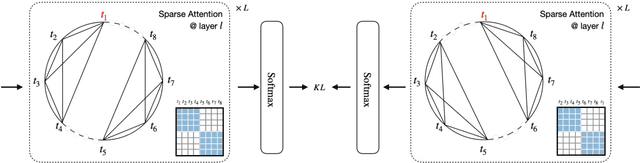
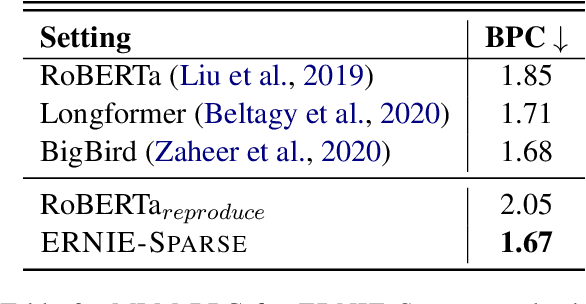
Sparse Transformer has recently attracted a lot of attention since the ability for reducing the quadratic dependency on the sequence length. We argue that two factors, information bottleneck sensitivity and inconsistency between different attention topologies, could affect the performance of the Sparse Transformer. This paper proposes a well-designed model named ERNIE-Sparse. It consists of two distinctive parts: (i) Hierarchical Sparse Transformer (HST) to sequentially unify local and global information. (ii) Self-Attention Regularization (SAR) method, a novel regularization designed to minimize the distance for transformers with different attention topologies. To evaluate the effectiveness of ERNIE-Sparse, we perform extensive evaluations. Firstly, we perform experiments on a multi-modal long sequence modeling task benchmark, Long Range Arena (LRA). Experimental results demonstrate that ERNIE-Sparse significantly outperforms a variety of strong baseline methods including the dense attention and other efficient sparse attention methods and achieves improvements by 2.77% (57.78% vs. 55.01%). Secondly, to further show the effectiveness of our method, we pretrain ERNIE-Sparse and verified it on 3 text classification and 2 QA downstream tasks, achieve improvements on classification benchmark by 0.83% (92.46% vs. 91.63%), on QA benchmark by 3.24% (74.67% vs. 71.43%). Experimental results continue to demonstrate its superior performance.
DuReader_retrieval: A Large-scale Chinese Benchmark for Passage Retrieval from Web Search Engine
Mar 19, 2022
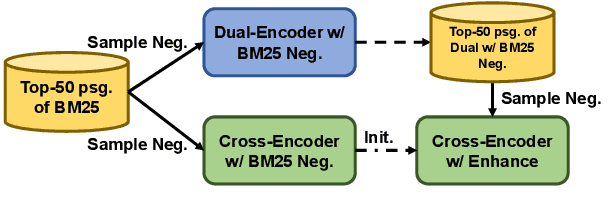
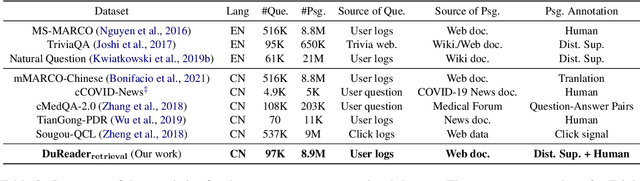
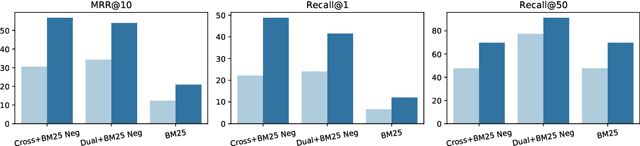
In this paper, we present DuReader_retrieval, a large-scale Chinese dataset for passage retrieval. DuReader_retrieval contains more than 90K queries and over 8M unique passages from Baidu search. To ensure the quality of our benchmark and address the shortcomings in other existing datasets, we (1) reduce the false negatives in development and testing sets by pooling the results from multiple retrievers with human annotations, (2) and remove the semantically similar questions between training with development and testing sets. We further introduce two extra out-of-domain testing sets for benchmarking the domain generalization capability. Our experiment results demonstrate that DuReader_retrieval is challenging and there is still plenty of room for the community to improve, e.g. the generalization across domains, salient phrase and syntax mismatch between query and paragraph and robustness. DuReader_retrieval will be publicly available at https://github.com/baidu/DuReader/tree/master/DuReader-Retrieval
UNIMO-2: End-to-End Unified Vision-Language Grounded Learning
Mar 17, 2022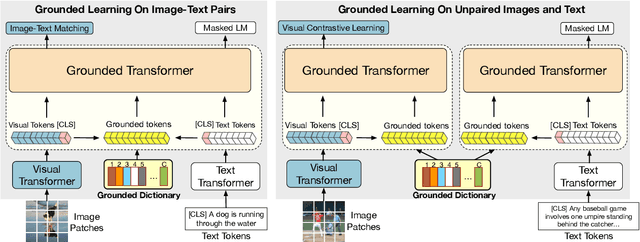
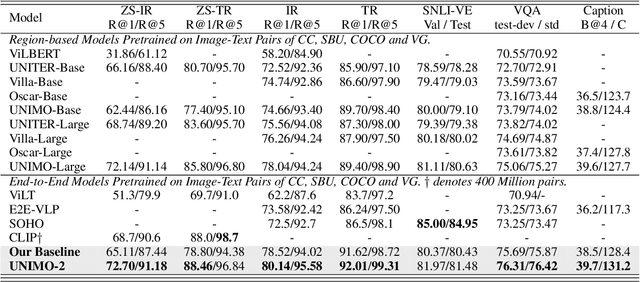
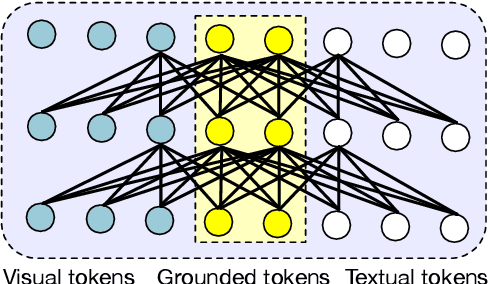

Vision-Language Pre-training (VLP) has achieved impressive performance on various cross-modal downstream tasks. However, most existing methods can only learn from aligned image-caption data and rely heavily on expensive regional features, which greatly limits their scalability and performance. In this paper, we propose an end-to-end unified-modal pre-training framework, namely UNIMO-2, for joint learning on both aligned image-caption data and unaligned image-only and text-only corpus. We build a unified Transformer model to jointly learn visual representations, textual representations and semantic alignment between images and texts. In particular, we propose to conduct grounded learning on both images and texts via a sharing grounded space, which helps bridge unaligned images and texts, and align the visual and textual semantic spaces on different types of corpora. The experiments show that our grounded learning method can improve textual and visual semantic alignment for improving performance on various cross-modal tasks. Moreover, benefiting from effective joint modeling of different types of corpora, our model also achieves impressive performance on single-modal visual and textual tasks. Our code and models are public at the UNIMO project page https://unimo-ptm.github.io/.
Long Time No See! Open-Domain Conversation with Long-Term Persona Memory
Mar 14, 2022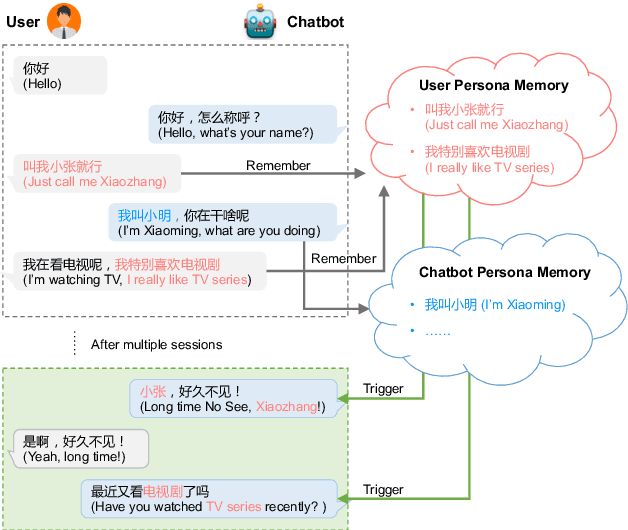
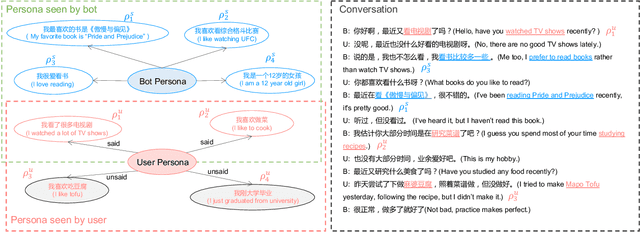
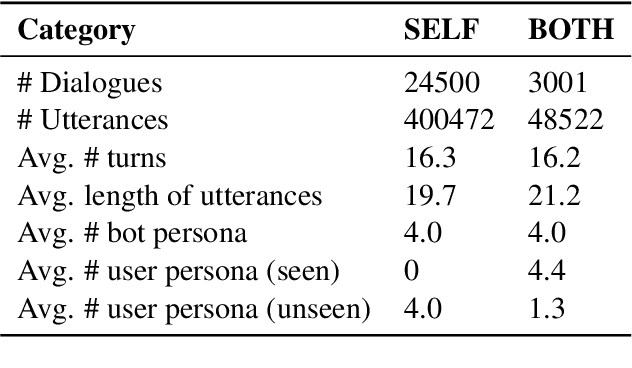
Most of the open-domain dialogue models tend to perform poorly in the setting of long-term human-bot conversations. The possible reason is that they lack the capability of understanding and memorizing long-term dialogue history information. To address this issue, we present a novel task of Long-term Memory Conversation (LeMon) and then build a new dialogue dataset DuLeMon and a dialogue generation framework with Long-Term Memory (LTM) mechanism (called PLATO-LTM). This LTM mechanism enables our system to accurately extract and continuously update long-term persona memory without requiring multiple-session dialogue datasets for model training. To our knowledge, this is the first attempt to conduct real-time dynamic management of persona information of both parties, including the user and the bot. Results on DuLeMon indicate that PLATO-LTM can significantly outperform baselines in terms of long-term dialogue consistency, leading to better dialogue engagingness.
Semantic Similarity Computing Model Based on Multi Model Fine-Grained Nonlinear Fusion
Feb 05, 2022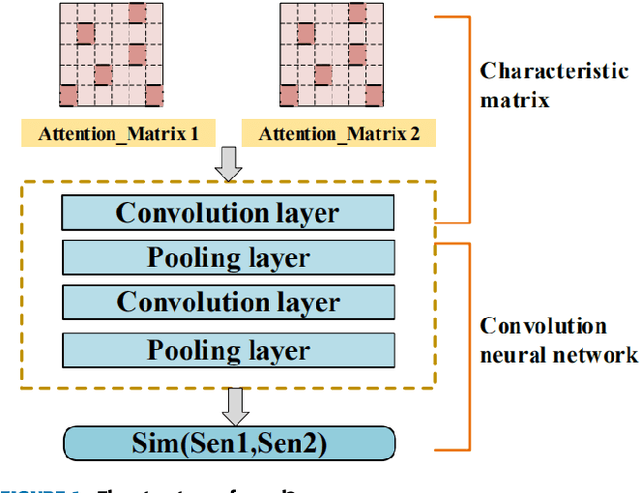

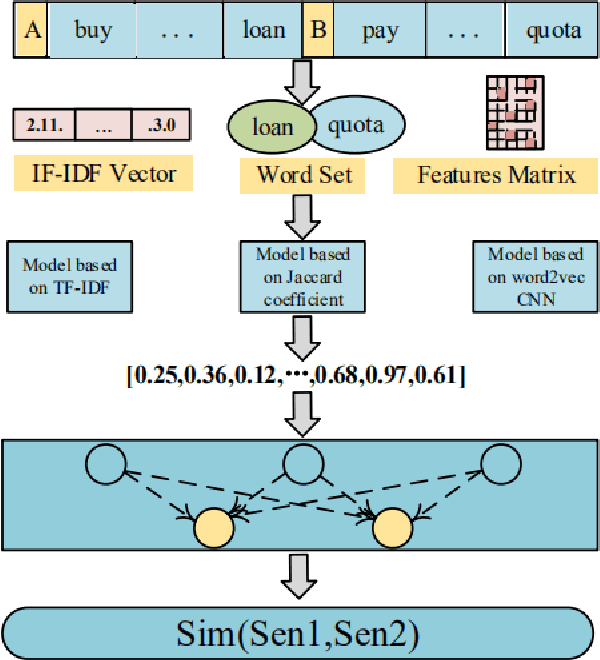
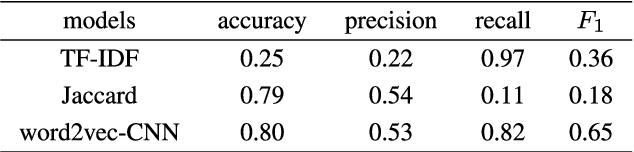
Natural language processing (NLP) task has achieved excellent performance in many fields, including semantic understanding, automatic summarization, image recognition and so on. However, most of the neural network models for NLP extract the text in a fine-grained way, which is not conducive to grasp the meaning of the text from a global perspective. To alleviate the problem, the combination of the traditional statistical method and deep learning model as well as a novel model based on multi model nonlinear fusion are proposed in this paper. The model uses the Jaccard coefficient based on part of speech, Term Frequency-Inverse Document Frequency (TF-IDF) and word2vec-CNN algorithm to measure the similarity of sentences respectively. According to the calculation accuracy of each model, the normalized weight coefficient is obtained and the calculation results are compared. The weighted vector is input into the fully connected neural network to give the final classification results. As a result, the statistical sentence similarity evaluation algorithm reduces the granularity of feature extraction, so it can grasp the sentence features globally. Experimental results show that the matching of sentence similarity calculation method based on multi model nonlinear fusion is 84%, and the F1 value of the model is 75%.
A Gradient Mapping Guided Explainable Deep Neural Network for Extracapsular Extension Identification in 3D Head and Neck Cancer Computed Tomography Images
Jan 03, 2022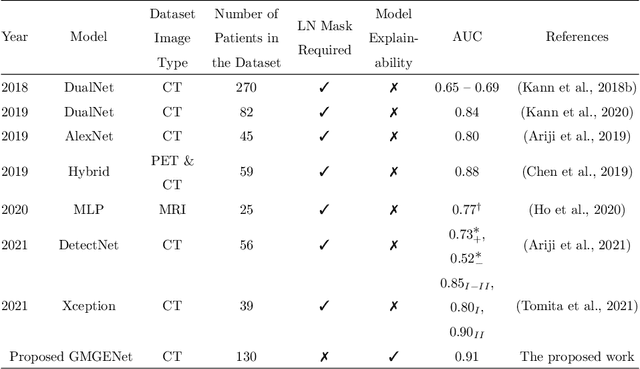
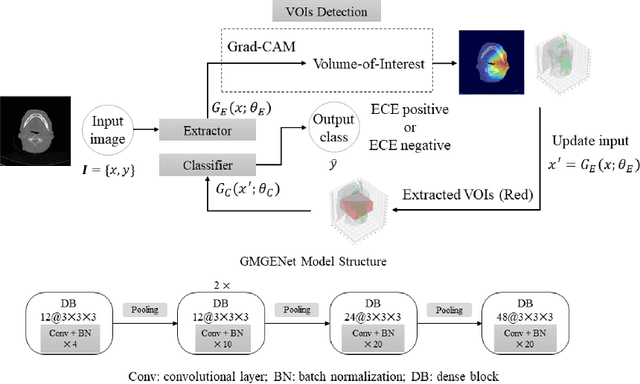
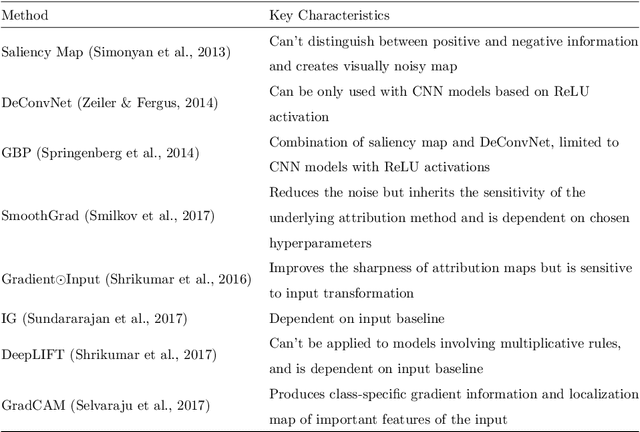
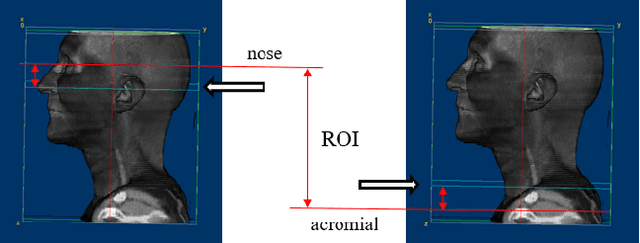
Diagnosis and treatment management for head and neck squamous cell carcinoma (HNSCC) is guided by routine diagnostic head and neck computed tomography (CT) scans to identify tumor and lymph node features. Extracapsular extension (ECE) is a strong predictor of patients' survival outcomes with HNSCC. It is essential to detect the occurrence of ECE as it changes staging and management for the patients. Current clinical ECE detection relies on visual identification and pathologic confirmation conducted by radiologists. Machine learning (ML)-based ECE diagnosis has shown high potential in the recent years. However, manual annotation of lymph node region is a required data preprocessing step in most of the current ML-based ECE diagnosis studies. In addition, this manual annotation process is time-consuming, labor-intensive, and error-prone. Therefore, in this paper, we propose a Gradient Mapping Guided Explainable Network (GMGENet) framework to perform ECE identification automatically without requiring annotated lymph node region information. The gradient-weighted class activation mapping (Grad-CAM) technique is proposed to guide the deep learning algorithm to focus on the regions that are highly related to ECE. Informative volumes of interest (VOIs) are extracted without labeled lymph node region information. In evaluation, the proposed method is well-trained and tested using cross validation, achieving test accuracy and AUC of 90.2% and 91.1%, respectively. The presence or absence of ECE has been analyzed and correlated with gold standard histopathological findings.