 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLOP: Video-and-Language Pre-Training with Knowledge Regularizations
Nov 07, 2022Video-and-language pre-training has shown promising results for learning generalizable representations. Most existing approaches usually model video and text in an implicit manner, without considering explicit structural representations of the multi-modal content. We denote such form of representations as structural knowledge, which express rich semantics of multiple granularities. There are related works that propose object-aware approaches to inject similar knowledge as inputs. However, the existing methods usually fail to effectively utilize such knowledge as regularizations to shape a superior cross-modal representation space. To this end, we propose a Cross-modaL knOwledge-enhanced Pre-training (CLOP) method with Knowledge Regularizations. There are two key designs of ours: 1) a simple yet effective Structural Knowledge Prediction (SKP) task to pull together the latent representations of similar videos; and 2) a novel Knowledge-guided sampling approach for Contrastive Learning (KCL) to push apart cross-modal hard negative samples. We evaluate our method on four text-video retrieval tasks and one multi-choice QA task. The experiments show clear improvements, outperforming prior works by a substantial margin. Besides, we provide ablations and insights of how our methods affect the latent representation space, demonstrating the value of incorporating knowledge regularizations into video-and-language pre-training.
PLATO-K: Internal and External Knowledge Enhanced Dialogue Generation
Nov 02, 2022



Recently, the practical deployment of open-domain dialogue systems has been plagued by the knowledge issue of information deficiency and factual inaccuracy. To this end, we introduce PLATO-K based on two-stage dialogic learning to strengthen internal knowledge memorization and external knowledge exploitation. In the first stage, PLATO-K learns through massive dialogue corpora and memorizes essential knowledge into model parameters. In the second stage, PLATO-K mimics human beings to search for external information and to leverage the knowledge in response generation. Extensive experiments reveal that the knowledge issue is alleviated significantly in PLATO-K with such comprehensive internal and external knowledge enhancement. Compared to the existing state-of-the-art Chinese dialogue model, the overall engagingness of PLATO-K is improved remarkably by 36.2% and 49.2% on chit-chat and knowledge-intensive conversations.
ERNIE-ViLG 2.0: Improving Text-to-Image Diffusion Model with Knowledge-Enhanced Mixture-of-Denoising-Experts
Oct 27, 2022



Recent progress in diffusion models has revolutionized the popular technology of text-to-image generation. While existing approaches could produce photorealistic high-resolution images with text conditions, there are still several open problems to be solved, which limits the further improvement of image fidelity and text relevancy. In this paper, we propose ERNIE-ViLG 2.0, a large-scale Chinese text-to-image diffusion model, which progressively upgrades the quality of generated images~by: (1) incorporating fine-grained textual and visual knowledge of key elements in the scene, and (2) utilizing different denoising experts at different denoising stages. With the proposed mechanisms, ERNIE-ViLG 2.0 not only achieves the state-of-the-art on MS-COCO with zero-shot FID score of 6.75, but also significantly outperforms recent models in terms of image fidelity and image-text alignment, with side-by-side human evaluation on the bilingual prompt set ViLG-300.
A Novel Adaptive Causal Sampling Method for Physics-Informed Neural Networks
Oct 24, 2022



Physics-Informed Neural Networks (PINNs) have become a kind of attractive machine learning method for obtaining solutions of partial differential equations (PDEs). Training PINNs can be seen as a semi-supervised learning task, in which only exact values of initial and boundary points can be obtained in solving forward problems, and in the whole spatio-temporal domain collocation points are sampled without exact labels, which brings training difficulties. Thus the selection of collocation points and sampling methods are quite crucial in training PINNs. Existing sampling methods include fixed and dynamic types, and in the more popular latter one, sampling is usually controlled by PDE residual loss. We point out that it is not sufficient to only consider the residual loss in adaptive sampling and sampling should obey temporal causality. We further introduce temporal causality into adaptive sampling and propose a novel adaptive causal sampling method to improve the performance and efficiency of PINNs. Numerical experiments of several PDEs with high-order derivatives and strong nonlinearity, including Cahn Hilliard and KdV equations, show that the proposed sampling method can improve the performance of PINNs with few collocation points. We demonstrate that by utilizing such a relatively simple sampling method, prediction performance can be improved up to two orders of magnitude compared with state-of-the-art results with almost no extra computation cost, especially when points are limited.
ERNIE-Layout: Layout Knowledge Enhanced Pre-training for Visually-rich Document Understanding
Oct 14, 2022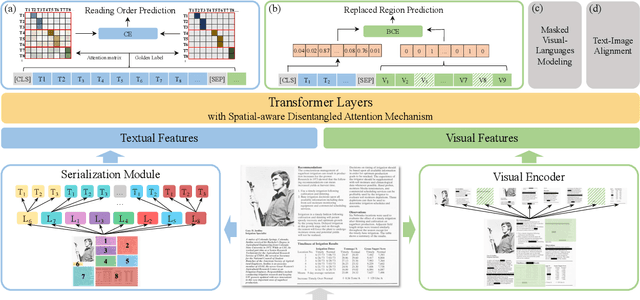
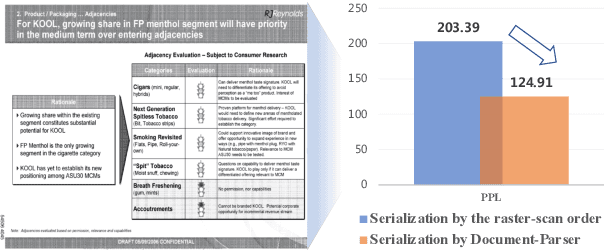
Recent years have witnessed the rise and success of pre-training techniques in visually-rich document understanding. However, most existing methods lack the systematic mining and utilization of layout-centered knowledge, leading to sub-optimal performances. In this paper, we propose ERNIE-Layout, a novel document pre-training solution with layout knowledge enhancement in the whole workflow, to learn better representations that combine the features from text, layout, and image. Specifically, we first rearrange input sequences in the serialization stage, and then present a correlative pre-training task, reading order prediction, to learn the proper reading order of documents. To improve the layout awareness of the model, we integrate a spatial-aware disentangled attention into the multi-modal transformer and a replaced regions prediction task into the pre-training phase. Experimental results show that ERNIE-Layout achieves superior performance on various downstream tasks, setting new state-of-the-art on key information extraction, document image classification, and document question answering datasets. The code and models are publicly available at http://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-layout.
ERNIE-ViL 2.0: Multi-view Contrastive Learning for Image-Text Pre-training
Sep 30, 2022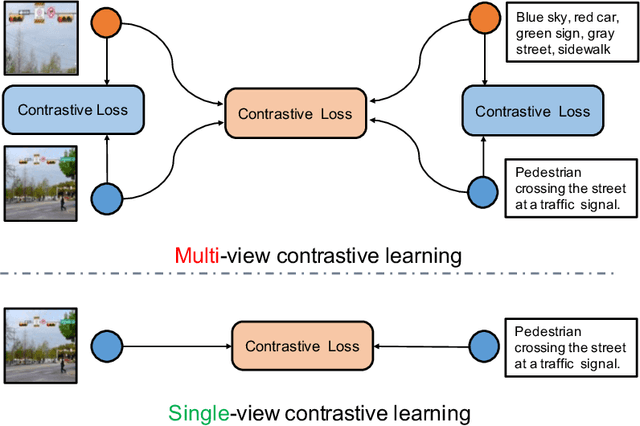
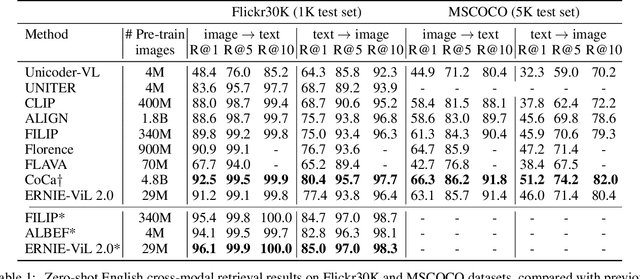
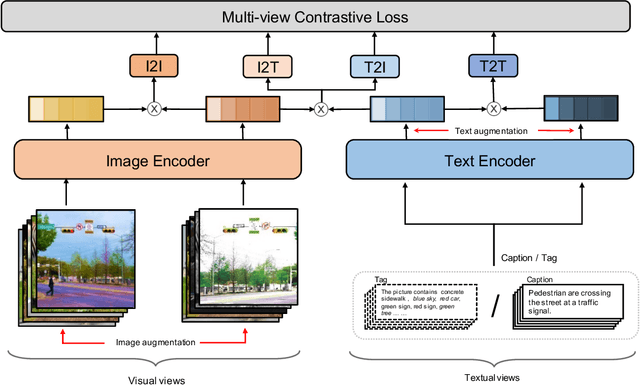
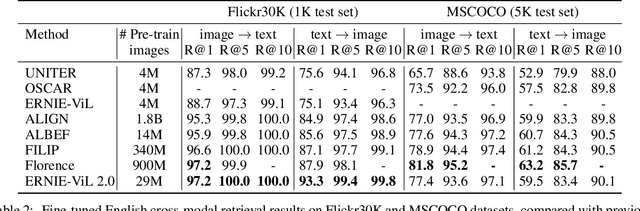
Recent Vision-Language Pre-trained (VLP) models based on dual encoder have attracted extensive attention from academia and industry due to their superior performance on various cross-modal tasks and high computational efficiency. They attempt to learn cross-modal representation using contrastive learning on image-text pairs, however, the built inter-modal correlations only rely on a single view for each modality. Actually, an image or a text contains various potential views, just as humans could capture a real-world scene via diverse descriptions or photos. In this paper, we propose ERNIE-ViL 2.0, a Multi-View Contrastive learning framework to build intra-modal and inter-modal correlations between diverse views simultaneously, aiming at learning a more robust cross-modal representation. Specifically, we construct multiple views within each modality to learn the intra-modal correlation for enhancing the single-modal representation. Besides the inherent visual/textual views, we construct sequences of object tags as a special textual view to narrow the cross-modal semantic gap on noisy image-text pairs. Pre-trained with 29M publicly available datasets, ERNIE-ViL 2.0 achieves competitive results on English cross-modal retrieval. Additionally, to generalize our method to Chinese cross-modal tasks, we train ERNIE-ViL 2.0 through scaling up the pre-training datasets to 1.5B Chinese image-text pairs, resulting in significant improvements compared to previous SOTA results on Chinese cross-modal retrieval. We release our pre-trained models in https://github.com/PaddlePaddle/ERNIE.
Self-Score: Self-Supervised Learning on Score-Based Models for MRI Reconstruction
Sep 02, 2022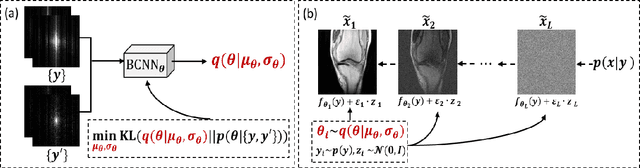
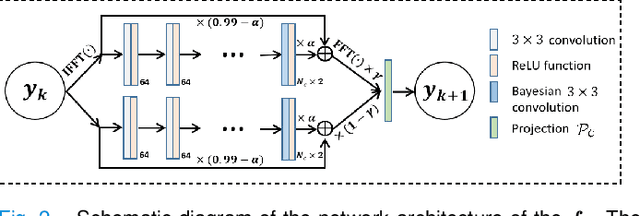

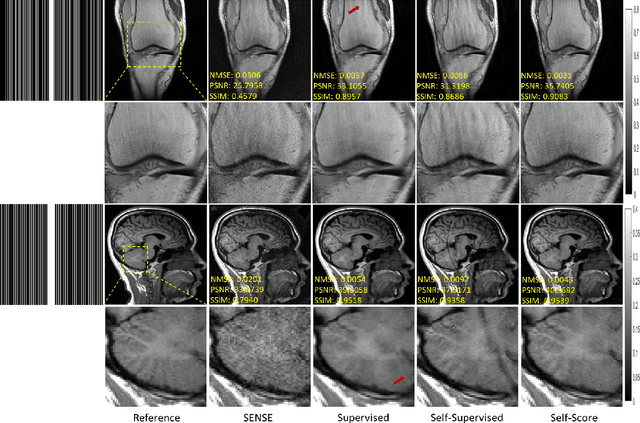
Recently, score-based diffusion models have shown satisfactory performance in MRI reconstruction. Most of these methods require a large amount of fully sampled MRI data as a training set, which, sometimes, is difficult to acquire in practice. This paper proposes a fully-sampled-data-free score-based diffusion model for MRI reconstruction, which learns the fully sampled MR image prior in a self-supervised manner on undersampled data. Specifically, we first infer the fully sampled MR image distribution from the undersampled data by Bayesian deep learning, then perturb the data distribution and approximate their probability density gradient by training a score function. Leveraging the learned score function as a prior, we can reconstruct the MR image by performing conditioned Langevin Markov chain Monte Carlo (MCMC) sampling. Experiments on the public dataset show that the proposed method outperforms existing self-supervised MRI reconstruction methods and achieves comparable performances with the conventional (fully sampled data trained) score-based diffusion methods.
Towards Boosting the Open-Domain Chatbot with Human Feedback
Aug 30, 2022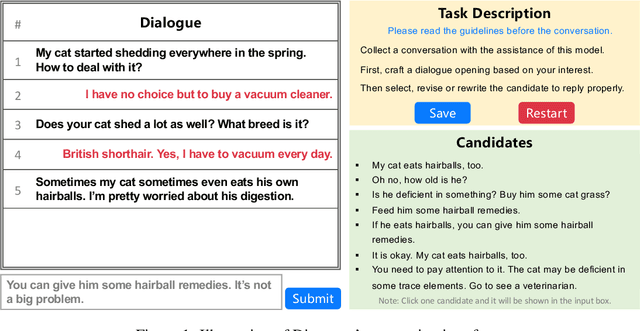
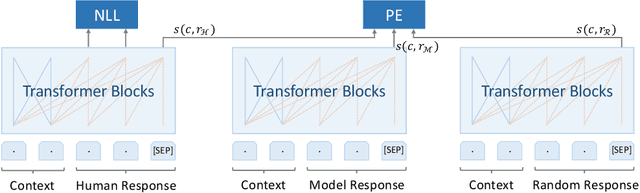

Many open-domain dialogue models pre-trained with social media comments can generate coherent replies but have difficulties producing engaging responses when interacting with real users. This phenomenon might mainly result from the deficiency of annotated human-human conversations and the misalignment with human preference. In this paper, we propose a novel and efficient approach Diamante to boost the open-domain chatbot, where two kinds of human feedback (including explicit demonstration and implicit preference) are collected and leveraged. By asking annotators to select or amend the model-generated candidate responses, Diamante efficiently collects the human demonstrated responses and constructs a Chinese chit-chat dataset. To enhance the alignment with human preference, Diamante leverages the implicit preference in the data collection process and introduces the generation-evaluation joint training. Comprehensive experiments indicate that the Diamante dataset and joint training paradigm can significantly boost the performance of Chinese pre-trained dialogue models.
DuETA: Traffic Congestion Propagation Pattern Modeling via Efficient Graph Learning for ETA Prediction at Baidu Maps
Aug 15, 2022
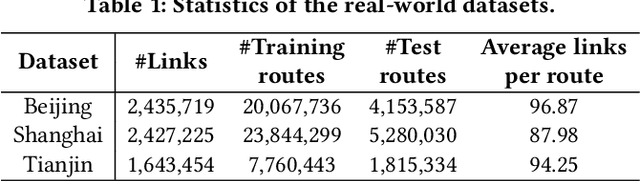
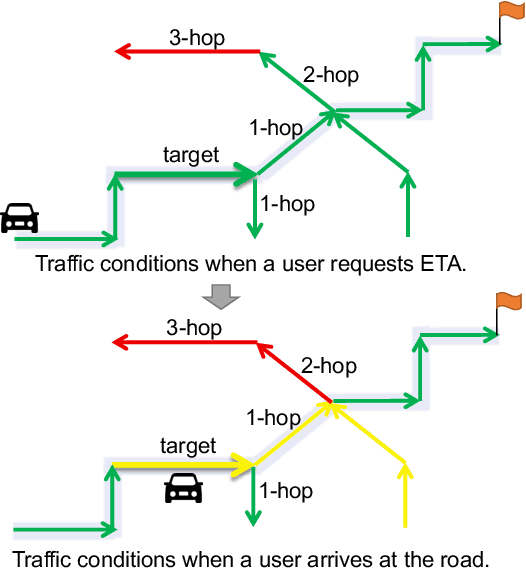
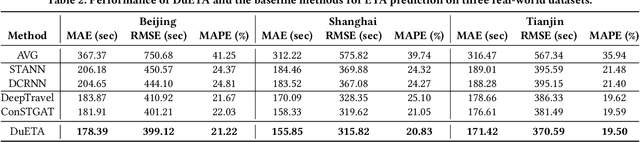
Estimated time of arrival (ETA) prediction, also known as travel time estimation, is a fundamental task for a wide range of intelligent transportation applications, such as navigation, route planning, and ride-hailing services. To accurately predict the travel time of a route, it is essential to take into account both contextual and predictive factors, such as spatial-temporal interaction, driving behavior, and traffic congestion propagation inference. The ETA prediction models previously deployed at Baidu Maps have addressed the factors of spatial-temporal interaction (ConSTGAT) and driving behavior (SSML). In this work, we focus on modeling traffic congestion propagation patterns to improve ETA performance. Traffic congestion propagation pattern modeling is challenging, and it requires accounting for impact regions over time and cumulative effect of delay variations over time caused by traffic events on the road network. In this paper, we present a practical industrial-grade ETA prediction framework named DuETA. Specifically, we construct a congestion-sensitive graph based on the correlations of traffic patterns, and we develop a route-aware graph transformer to directly learn the long-distance correlations of the road segments. This design enables DuETA to capture the interactions between the road segment pairs that are spatially distant but highly correlated with traffic conditions. Extensive experiments are conducted on large-scale, real-world datasets collected from Baidu Maps. Experimental results show that ETA prediction can significantly benefit from the learned traffic congestion propagation patterns. In addition, DuETA has already been deployed in production at Baidu Maps, serving billions of requests every day. This demonstrates that DuETA is an industrial-grade and robust solution for large-scale ETA prediction services.
K-UNN: k-Space Interpolation With Untrained Neural Network
Aug 11, 2022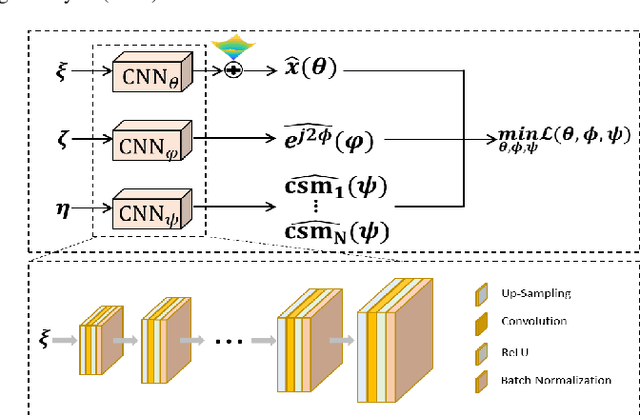
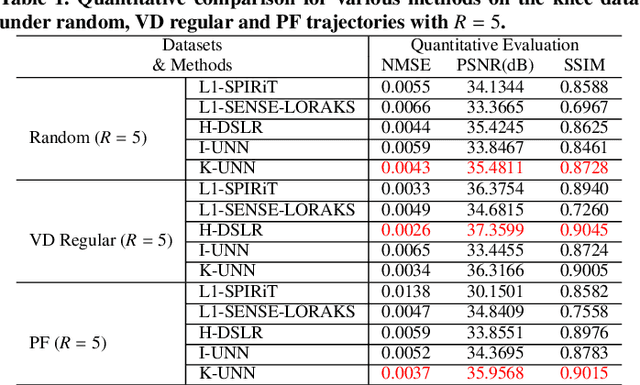

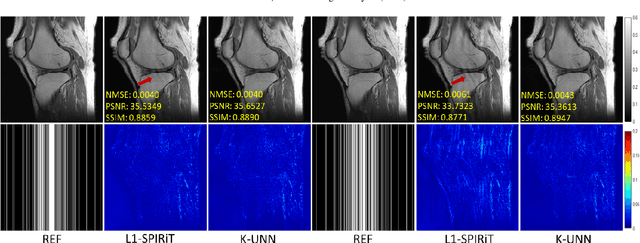
Recently, untrained neural networks (UNNs) have shown satisfactory performances for MR image reconstruction on random sampling trajectories without using additional full-sampled training data. However, the existing UNN-based approach does not fully use the MR image physical priors, resulting in poor performance in some common scenarios (e.g., partial Fourier, regular sampling, etc.) and the lack of theoretical guarantees for reconstruction accuracy. To bridge this gap, we propose a safeguarded k-space interpolation method for MRI using a specially designed UNN with a tripled architecture driven by three physical priors of the MR images (or k-space data), including sparsity, coil sensitivity smoothness, and phase smoothness. We also prove that the proposed method guarantees tight bounds for interpolated k-space data accuracy. Finally, ablation experiments show that the proposed method can more accurately characterize the physical priors of MR images than existing traditional methods. Additionally, under a series of commonly used sampling trajectories, experiments also show that the proposed method consistently outperforms traditional parallel imaging methods and existing UNNs, and even outperforms the state-of-the-art supervised-trained k-space deep learning methods in some cases.