 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Constraint Satisfaction: Hierarchical Abstraction for Combinatorial Generalization in Object Rearrangement
Mar 20, 2023Object rearrangement is a challenge for embodied agents because solving these tasks requires generalizing across a combinatorially large set of configurations of entities and their locations. Worse, the representations of these entities are unknown and must be inferred from sensory percepts. We present a hierarchical abstraction approach to uncover these underlying entities and achieve combinatorial generalization from unstructured visual inputs. By constructing a factorized transition graph over clusters of entity representations inferred from pixels, we show how to learn a correspondence between intervening on states of entities in the agent's model and acting on objects in the environment. We use this correspondence to develop a method for control that generalizes to different numbers and configurations of objects, which outperforms current offline deep RL methods when evaluated on simulated rearrangement tasks.
Cross-Domain Transfer via Semantic Skill Imitation
Dec 14, 2022



We propose an approach for semantic imitation, which uses demonstrations from a source domain, e.g. human videos, to accelerate reinforcement learning (RL) in a different target domain, e.g. a robotic manipulator in a simulated kitchen. Instead of imitating low-level actions like joint velocities, our approach imitates the sequence of demonstrated semantic skills like "opening the microwave" or "turning on the stove". This allows us to transfer demonstrations across environments (e.g. real-world to simulated kitchen) and agent embodiments (e.g. bimanual human demonstration to robotic arm). We evaluate on three challenging cross-domain learning problems and match the performance of demonstration-accelerated RL approaches that require in-domain demonstrations. In a simulated kitchen environment, our approach learns long-horizon robot manipulation tasks, using less than 3 minutes of human video demonstrations from a real-world kitchen. This enables scaling robot learning via the reuse of demonstrations, e.g. collected as human videos, for learning in any number of target domains.
* Project website: https://kpertsch.github.io/star
Neural Grasp Distance Fields for Robot Manipulation
Nov 04, 2022We formulate grasp learning as a neural field and present Neural Grasp Distance Fields (NGDF). Here, the input is a 6D pose of a robot end effector and output is a distance to a continuous manifold of valid grasps for an object. In contrast to current approaches that predict a set of discrete candidate grasps, the distance-based NGDF representation is easily interpreted as a cost, and minimizing this cost produces a successful grasp pose. This grasp distance cost can be incorporated directly into a trajectory optimizer for joint optimization with other costs such as trajectory smoothness and collision avoidance. During optimization, as the various costs are balanced and minimized, the grasp target is allowed to smoothly vary, as the learned grasp field is continuous. In simulation benchmarks with a Franka arm, we find that joint grasping and planning with NGDF outperforms baselines by 63% execution success while generalizing to unseen query poses and unseen object shapes. Project page: https://sites.google.com/view/neural-grasp-distance-fields.
Model Based Meta Learning of Critics for Policy Gradients
Apr 05, 2022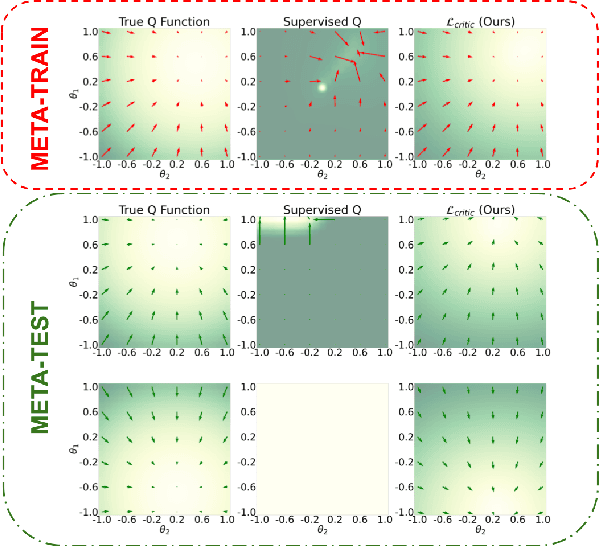
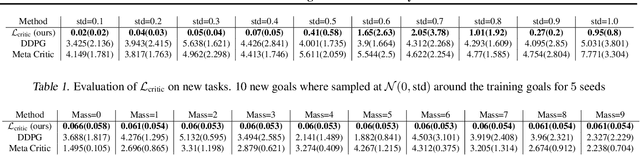
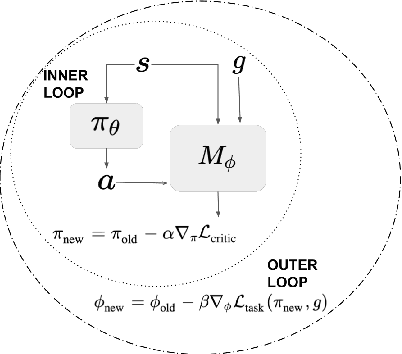
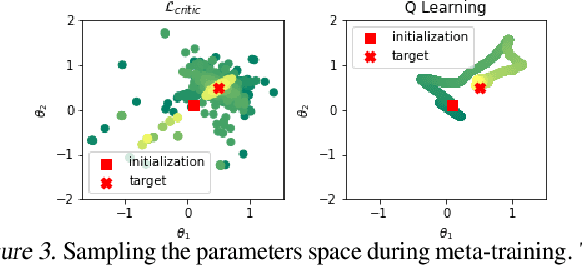
Being able to seamlessly generalize across different tasks is fundamental for robots to act in our world. However, learning representations that generalize quickly to new scenarios is still an open research problem in reinforcement learning. In this paper we present a framework to meta-learn the critic for gradient-based policy learning. Concretely, we propose a model-based bi-level optimization algorithm that updates the critics parameters such that the policy that is learned with the updated critic gets closer to solving the meta-training tasks. We illustrate that our algorithm leads to learned critics that resemble the ground truth Q function for a given task. Finally, after meta-training, the learned critic can be used to learn new policies for new unseen task and environment settings via model-free policy gradient optimization, without requiring a model. We present results that show the generalization capabilities of our learned critic to new tasks and dynamics when used to learn a new policy in a new scenario.
Differentiable and Learnable Robot Models
Feb 22, 2022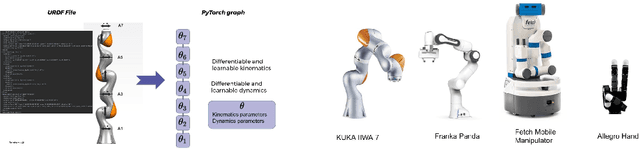
Building differentiable simulations of physical processes has recently received an increasing amount of attention. Specifically, some efforts develop differentiable robotic physics engines motivated by the computational benefits of merging rigid body simulations with modern differentiable machine learning libraries. Here, we present a library that focuses on the ability to combine data driven methods with analytical rigid body computations. More concretely, our library \emph{Differentiable Robot Models} implements both \emph{differentiable} and \emph{learnable} models of the kinematics and dynamics of robots in Pytorch. The source-code is available at \url{https://github.com/facebookresearch/differentiable-robot-model}
Block Contextual MDPs for Continual Learning
Oct 13, 2021
In reinforcement learning (RL), when defining a Markov Decision Process (MDP), the environment dynamics is implicitly assumed to be stationary. This assumption of stationarity, while simplifying, can be unrealistic in many scenarios. In the continual reinforcement learning scenario, the sequence of tasks is another source of nonstationarity. In this work, we propose to examine this continual reinforcement learning setting through the block contextual MDP (BC-MDP) framework, which enables us to relax the assumption of stationarity. This framework challenges RL algorithms to handle both nonstationarity and rich observation settings and, by additionally leveraging smoothness properties, enables us to study generalization bounds for this setting. Finally, we take inspiration from adaptive control to propose a novel algorithm that addresses the challenges introduced by this more realistic BC-MDP setting, allows for zero-shot adaptation at evaluation time, and achieves strong performance on several nonstationary environments.
Learning Time-Invariant Reward Functions through Model-Based Inverse Reinforcement Learning
Jul 07, 2021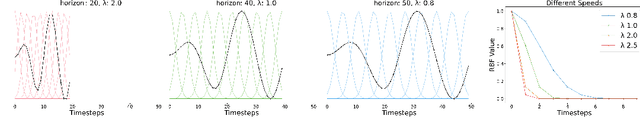
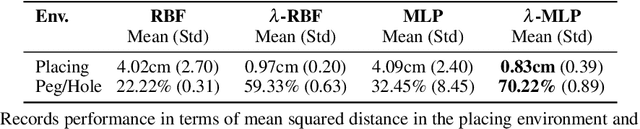

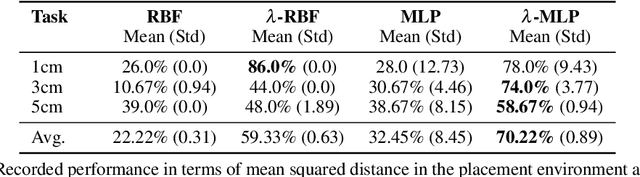
Inverse reinforcement learning is a paradigm motivated by the goal of learning general reward functions from demonstrated behaviours. Yet the notion of generality for learnt costs is often evaluated in terms of robustness to various spatial perturbations only, assuming deployment at fixed speeds of execution. However, this is impractical in the context of robotics and building time-invariant solutions is of crucial importance. In this work, we propose a formulation that allows us to 1) vary the length of execution by learning time-invariant costs, and 2) relax the temporal alignment requirements for learning from demonstration. We apply our method to two different types of cost formulations and evaluate their performance in the context of learning reward functions for simulated placement and peg in hole tasks. Our results show that our approach enables learning temporally invariant rewards from misaligned demonstration that can also generalise spatially to out of distribution tasks.
Habitat 2.0: Training Home Assistants to Rearrange their Habitat
Jun 28, 2021


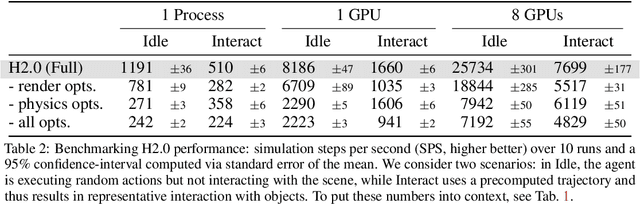
We introduce Habitat 2.0 (H2.0), a simulation platform for training virtual robots in interactive 3D environments and complex physics-enabled scenarios. We make comprehensive contributions to all levels of the embodied AI stack - data, simulation, and benchmark tasks. Specifically, we present: (i) ReplicaCAD: an artist-authored, annotated, reconfigurable 3D dataset of apartments (matching real spaces) with articulated objects (e.g. cabinets and drawers that can open/close); (ii) H2.0: a high-performance physics-enabled 3D simulator with speeds exceeding 25,000 simulation steps per second (850x real-time) on an 8-GPU node, representing 100x speed-ups over prior work; and, (iii) Home Assistant Benchmark (HAB): a suite of common tasks for assistive robots (tidy the house, prepare groceries, set the table) that test a range of mobile manipulation capabilities. These large-scale engineering contributions allow us to systematically compare deep reinforcement learning (RL) at scale and classical sense-plan-act (SPA) pipelines in long-horizon structured tasks, with an emphasis on generalization to new objects, receptacles, and layouts. We find that (1) flat RL policies struggle on HAB compared to hierarchical ones; (2) a hierarchy with independent skills suffers from 'hand-off problems', and (3) SPA pipelines are more brittle than RL policies.
Learning Navigation Skills for Legged Robots with Learned Robot Embeddings
Nov 24, 2020

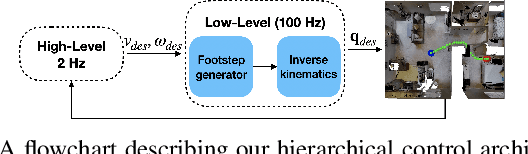
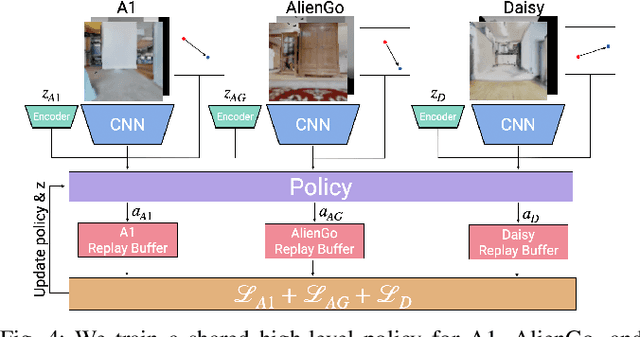
Navigation policies are commonly learned on idealized cylinder agents in simulation, without modelling complex dynamics, like contact dynamics, arising from the interaction between the robot and the environment. Such policies perform poorly when deployed on complex and dynamic robots, such as legged robots. In this work, we learn hierarchical navigation policies that account for the low-level dynamics of legged robots, such as maximum speed, slipping, and achieve good performance at navigating cluttered indoor environments. Once such a policy is learned on one legged robot, it does not directly generalize to a different robot due to dynamical differences, which increases the cost of learning such a policy on new robots. To overcome this challenge, we learn dynamics-aware navigation policies across multiple robots with robot-specific embeddings, which enable generalization to new unseen robots. We train our policies across three legged robots - 2 quadrupeds (A1, AlienGo) and a hexapod (Daisy). At test time, we study the performance of our learned policy on two new legged robots (Laikago, 4-legged Daisy) and show that our learned policy can sample-efficiently generalize to previously unseen robots.
Learning Extended Body Schemas from Visual Keypoints for Object Manipulation
Nov 08, 2020
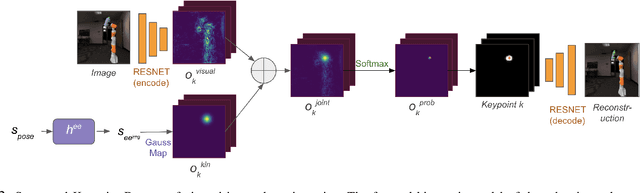
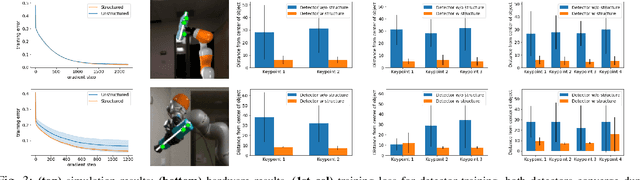

Humans have impressive generalization capabilities when it comes to manipulating objects and tools in completely novel environments. These capabilities are, at least partially, a result of humans having internal models of their bodies and any grasped object. How to learn such body schemas for robots remains an open problem. In this work, we develop an approach that can extend a robot's kinematic model when grasping an object from visual latent representations. Our framework comprises two components: 1) a structured keypoint detector, which fuses proprioception and vision to predict visual key points on an object; 2) Learning an adaptation of the kinematic chain by regressing virtual joints from the predicted key points. Our evaluation shows that our approach learns to consistently predict visual keypoints on objects, and can easily adapt a kinematic chain to the object grasped in various configurations, from a few seconds of data. Finally we show that this extended kinematic chain lends itself for object manipulation tasks such as placing a grasped object.