 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
Device-Directed Speech Detection for Follow-up Conversations Using Large Language Models
Nov 04, 2024Follow-up conversations with virtual assistants (VAs) enable a user to seamlessly interact with a VA without the need to repeatedly invoke it using a keyword (after the first query). Therefore, accurate Device-directed Speech Detection (DDSD) from the follow-up queries is critical for enabling naturalistic user experience. To this end, we explore the notion of Large Language Models (LLMs) and model the first query when making inference about the follow-ups (based on the ASR-decoded text), via prompting of a pretrained LLM, or by adapting a binary classifier on top of the LLM. In doing so, we also exploit the ASR uncertainty when designing the LLM prompts. We show on the real-world dataset of follow-up conversations that this approach yields large gains (20-40% reduction in false alarms at 10% fixed false rejects) due to the joint modeling of the previous speech context and ASR uncertainty, compared to when follow-ups are modeled alone.
Multimodal Large Language Models with Fusion Low Rank Adaptation for Device Directed Speech Detection
Jun 13, 2024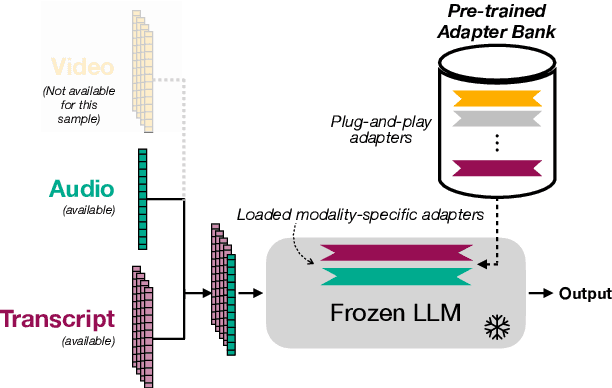



Although Large Language Models (LLMs) have shown promise for human-like conversations, they are primarily pre-trained on text data. Incorporating audio or video improves performance, but collecting large-scale multimodal data and pre-training multimodal LLMs is challenging. To this end, we propose a Fusion Low Rank Adaptation (FLoRA) technique that efficiently adapts a pre-trained unimodal LLM to consume new, previously unseen modalities via low rank adaptation. For device-directed speech detection, using FLoRA, the multimodal LLM achieves 22% relative reduction in equal error rate (EER) over the text-only approach and attains performance parity with its full fine-tuning (FFT) counterpart while needing to tune only a fraction of its parameters. Furthermore, with the newly introduced adapter dropout, FLoRA is robust to missing data, improving over FFT by 20% lower EER and 56% lower false accept rate. The proposed approach scales well for model sizes from 16M to 3B parameters.
Modality Dropout for Multimodal Device Directed Speech Detection using Verbal and Non-Verbal Features
Oct 23, 2023Device-directed speech detection (DDSD) is the binary classification task of distinguishing between queries directed at a voice assistant versus side conversation or background speech. State-of-the-art DDSD systems use verbal cues, e.g acoustic, text and/or automatic speech recognition system (ASR) features, to classify speech as device-directed or otherwise, and often have to contend with one or more of these modalities being unavailable when deployed in real-world settings. In this paper, we investigate fusion schemes for DDSD systems that can be made more robust to missing modalities. Concurrently, we study the use of non-verbal cues, specifically prosody features, in addition to verbal cues for DDSD. We present different approaches to combine scores and embeddings from prosody with the corresponding verbal cues, finding that prosody improves DDSD performance by upto 8.5% in terms of false acceptance rate (FA) at a given fixed operating point via non-linear intermediate fusion, while our use of modality dropout techniques improves the performance of these models by 7.4% in terms of FA when evaluated with missing modalities during inference time.
Episodic Memory Question Answering
May 03, 2022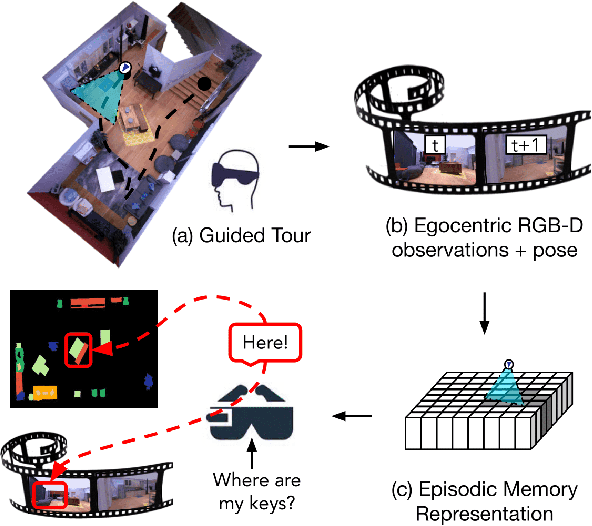
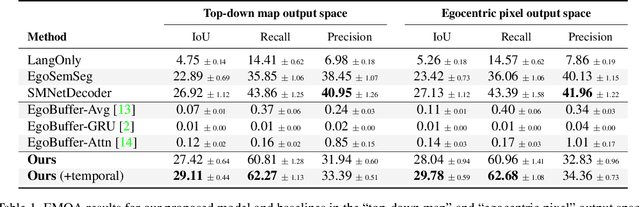
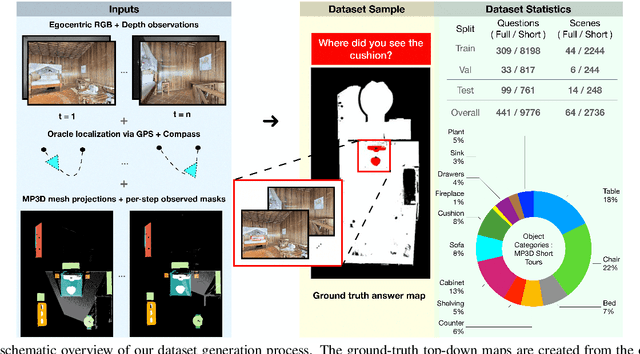
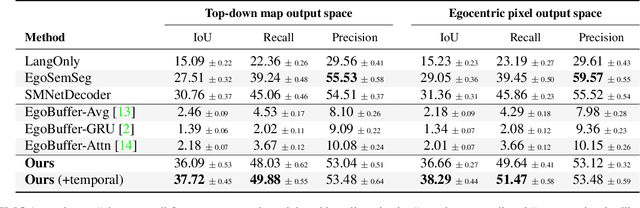
Egocentric augmented reality devices such as wearable glasses passively capture visual data as a human wearer tours a home environment. We envision a scenario wherein the human communicates with an AI agent powering such a device by asking questions (e.g., where did you last see my keys?). In order to succeed at this task, the egocentric AI assistant must (1) construct semantically rich and efficient scene memories that encode spatio-temporal information about objects seen during the tour and (2) possess the ability to understand the question and ground its answer into the semantic memory representation. Towards that end, we introduce (1) a new task - Episodic Memory Question Answering (EMQA) wherein an egocentric AI assistant is provided with a video sequence (the tour) and a question as an input and is asked to localize its answer to the question within the tour, (2) a dataset of grounded questions designed to probe the agent's spatio-temporal understanding of the tour, and (3) a model for the task that encodes the scene as an allocentric, top-down semantic feature map and grounds the question into the map to localize the answer. We show that our choice of episodic scene memory outperforms naive, off-the-shelf solutions for the task as well as a host of very competitive baselines and is robust to noise in depth, pose as well as camera jitter. The project page can be found at: https://samyak-268.github.io/emqa .
Habitat 2.0: Training Home Assistants to Rearrange their Habitat
Jun 28, 2021


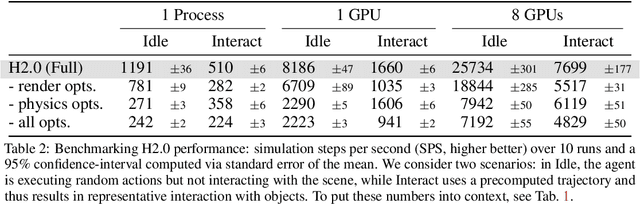
We introduce Habitat 2.0 (H2.0), a simulation platform for training virtual robots in interactive 3D environments and complex physics-enabled scenarios. We make comprehensive contributions to all levels of the embodied AI stack - data, simulation, and benchmark tasks. Specifically, we present: (i) ReplicaCAD: an artist-authored, annotated, reconfigurable 3D dataset of apartments (matching real spaces) with articulated objects (e.g. cabinets and drawers that can open/close); (ii) H2.0: a high-performance physics-enabled 3D simulator with speeds exceeding 25,000 simulation steps per second (850x real-time) on an 8-GPU node, representing 100x speed-ups over prior work; and, (iii) Home Assistant Benchmark (HAB): a suite of common tasks for assistive robots (tidy the house, prepare groceries, set the table) that test a range of mobile manipulation capabilities. These large-scale engineering contributions allow us to systematically compare deep reinforcement learning (RL) at scale and classical sense-plan-act (SPA) pipelines in long-horizon structured tasks, with an emphasis on generalization to new objects, receptacles, and layouts. We find that (1) flat RL policies struggle on HAB compared to hierarchical ones; (2) a hierarchy with independent skills suffers from 'hand-off problems', and (3) SPA pipelines are more brittle than RL policies.
SOrT-ing VQA Models : Contrastive Gradient Learning for Improved Consistency
Oct 20, 2020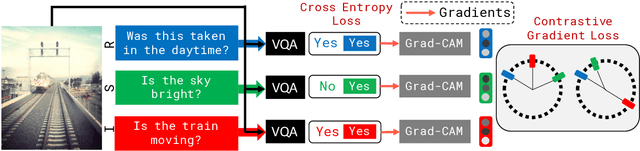



Recent research in Visual Question Answering (VQA) has revealed state-of-the-art models to be inconsistent in their understanding of the world -- they answer seemingly difficult questions requiring reasoning correctly but get simpler associated sub-questions wrong. These sub-questions pertain to lower level visual concepts in the image that models ideally should understand to be able to answer the higher level question correctly. To address this, we first present a gradient-based interpretability approach to determine the questions most strongly correlated with the reasoning question on an image, and use this to evaluate VQA models on their ability to identify the relevant sub-questions needed to answer a reasoning question. Next, we propose a contrastive gradient learning based approach called Sub-question Oriented Tuning (SOrT) which encourages models to rank relevant sub-questions higher than irrelevant questions for an <$image, reasoning-question$> pair. We show that SOrT improves model consistency by upto 6.5% points over existing baselines, while also improving visual grounding.