 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Efficient GANs using Differentiable Masks and co-Attention Distillation
Nov 21, 2020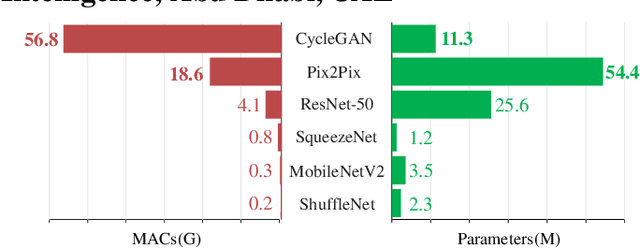
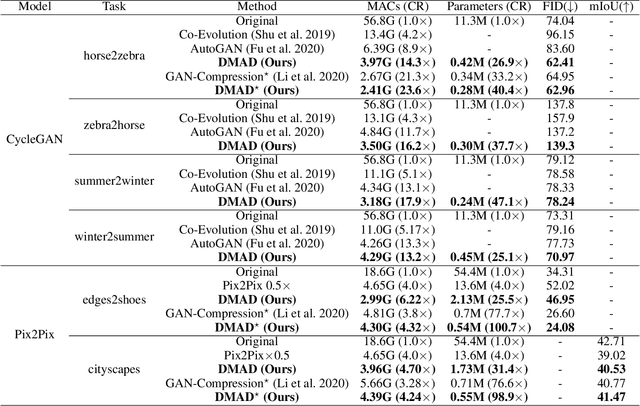
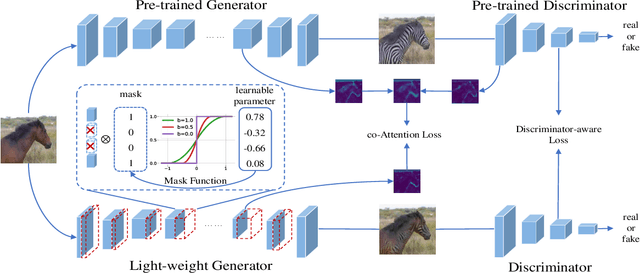
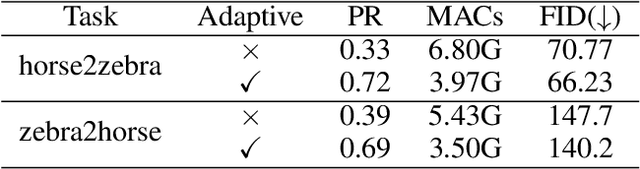
Generative Adversarial Networks (GANs) have been widely-used in image translation, but their high computational and storage costs impede the deployment on mobile devices. Prevalent methods for CNN compression cannot be directly applied to GANs due to the complicated generator architecture and the unstable adversarial training. To solve these, in this paper, we introduce a novel GAN compression method, termed DMAD, by proposing a Differentiable Mask and a co-Attention Distillation. The former searches for a light-weight generator architecture in a training-adaptive manner. To overcome channel inconsistency when pruning the residual connections, an adaptive cross-block group sparsity is further incorporated. The latter simultaneously distills informative attention maps from both the generator and discriminator of a pre-trained model to the searched generator, effectively stabilizing the adversarial training of our light-weight model. Experiments show that DMAD can reduce the Multiply Accumulate Operations (MACs) of CycleGAN by 13x and that of Pix2Pix by 4x while retaining a comparable performance against the full model. Code is available at https://github.com/SJLeo/DMAD.
Rotated Binary Neural Network
Oct 22, 2020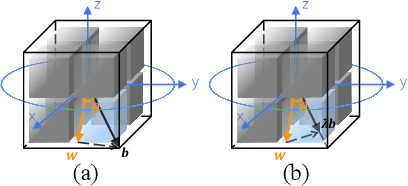
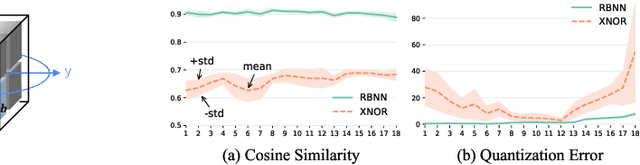
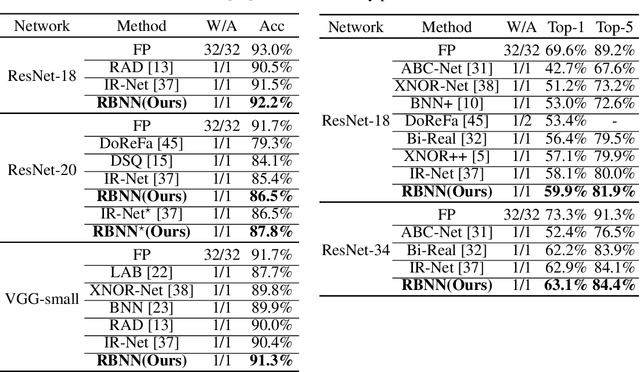
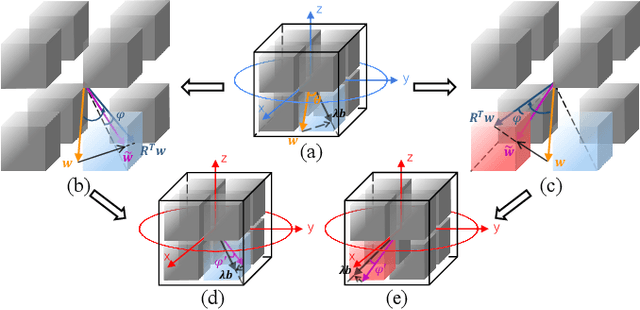
Binary Neural Network (BNN) shows its predominance in reducing the complexity of deep neural networks. However, it suffers severe performance degradation. One of the major impediments is the large quantization error between the full-precision weight vector and its binary vector. Previous works focus on compensating for the norm gap while leaving the angular bias hardly touched. In this paper, for the first time, we explore the influence of angular bias on the quantization error and then introduce a Rotated Binary Neural Network (RBNN), which considers the angle alignment between the full-precision weight vector and its binarized version. At the beginning of each training epoch, we propose to rotate the full-precision weight vector to its binary vector to reduce the angular bias. To avoid the high complexity of learning a large rotation matrix, we further introduce a bi-rotation formulation that learns two smaller rotation matrices. In the training stage, we devise an adjustable rotated weight vector for binarization to escape the potential local optimum. Our rotation leads to around 50% weight flips which maximize the information gain. Finally, we propose a training-aware approximation of the sign function for the gradient backward. Experiments on CIFAR-10 and ImageNet demonstrate the superiorities of RBNN over many state-of-the-arts. Our source code, experimental settings, training logs and binary models are available at https://github.com/lmbxmu/RBNN.
Devil's in the Detail: Graph-based Key-point Alignment and Embedding for Person Re-ID
Sep 11, 2020

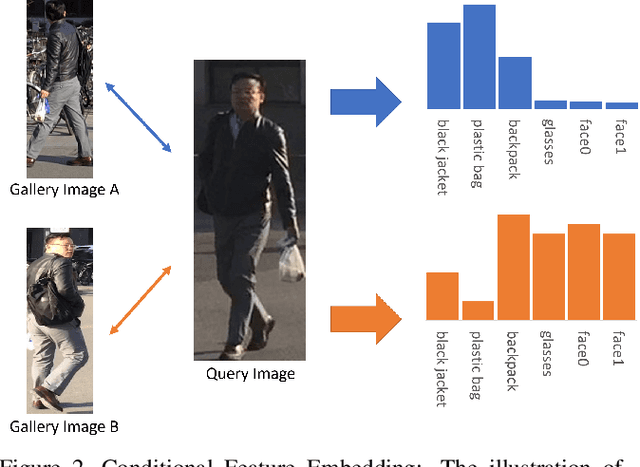
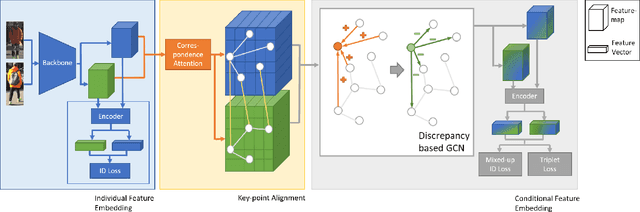
Although Person Re-Identification has made impressive progress, difficult cases like occlusion, change of view-point and similar clothing still bring great challenges. Besides overall visual features, matching and comparing detailed local information is also essential for tackling these challenges. This paper proposes two key recognition patterns to better utilize the local information of pedestrian images. From the spatial perspective, the model should be able to select and align key-points from the image pairs for comparison (i.e. key-points alignment). From the perspective of feature channels, the feature of a query image should be dynamically adjusted based on the gallery image it needs to match (i.e. conditional feature embedding). Most of the existing methods are unable to satisfy both key-point alignment and conditional feature embedding. By introducing novel techniques including correspondence attention module and discrepancy-based GCN, we propose an end-to-end ReID method that integrates both patterns into a unified framework, called Siamese-GCN. The experiments show that Siamese-GCN achieves state-of-the-art performance on three public datasets.
Face Anti-Spoofing Via Disentangled Representation Learning
Aug 19, 2020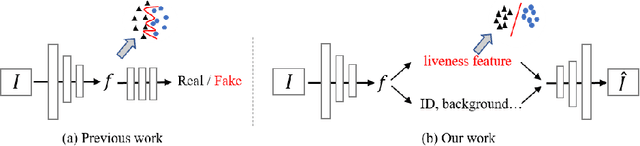
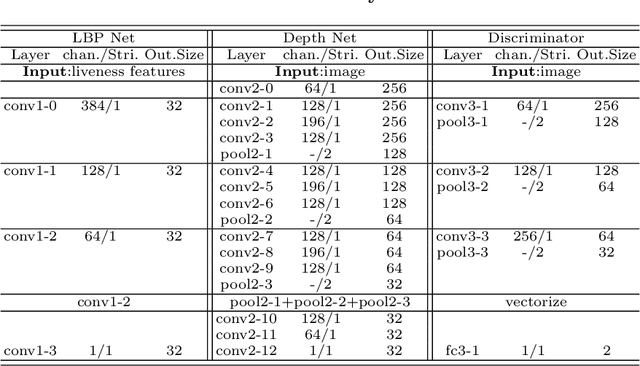
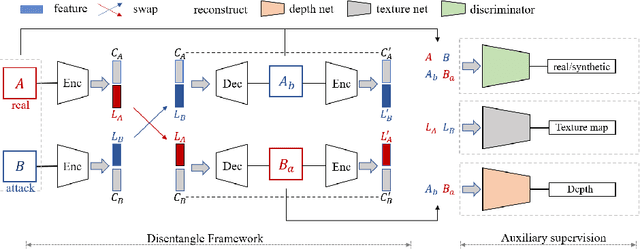
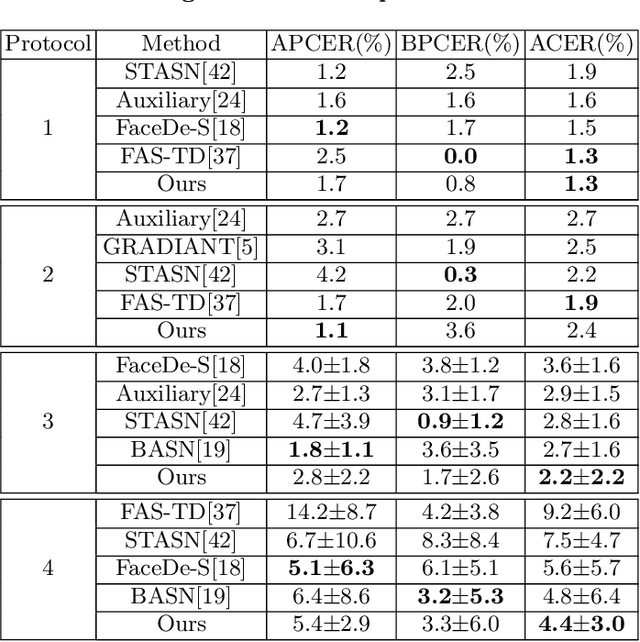
Face anti-spoofing is crucial to security of face recognition systems. Previous approaches focus on developing discriminative models based on the features extracted from images, which may be still entangled between spoof patterns and real persons. In this paper, motivated by the disentangled representation learning, we propose a novel perspective of face anti-spoofing that disentangles the liveness features and content features from images, and the liveness features is further used for classification. We also put forward a Convolutional Neural Network (CNN) architecture with the process of disentanglement and combination of low-level and high-level supervision to improve the generalization capabilities. We evaluate our method on public benchmark datasets and extensive experimental results demonstrate the effectiveness of our method against the state-of-the-art competitors. Finally, we further visualize some results to help understand the effect and advantage of disentanglement.
Adversarial Semantic Data Augmentation for Human Pose Estimation
Aug 03, 2020
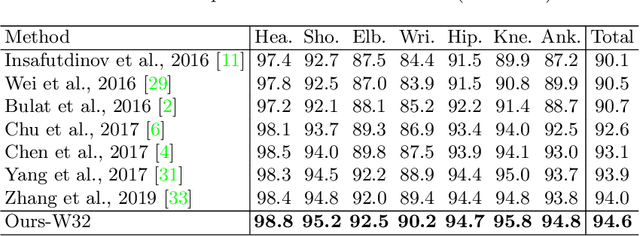
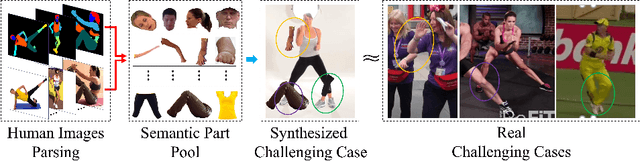
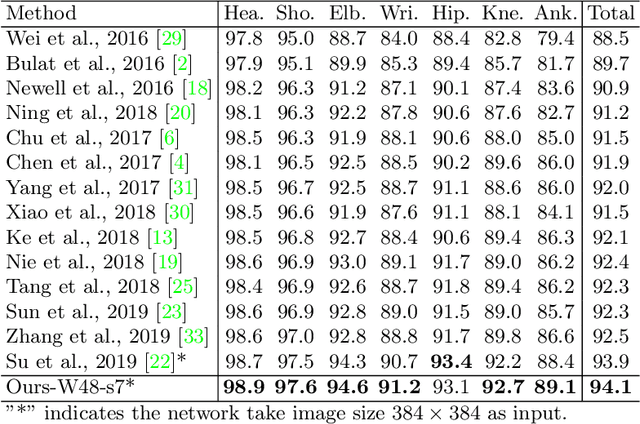
Human pose estimation is the task of localizing body keypoints from still images. The state-of-the-art methods suffer from insufficient examples of challenging cases such as symmetric appearance, heavy occlusion and nearby person. To enlarge the amounts of challenging cases, previous methods augmented images by cropping and pasting image patches with weak semantics, which leads to unrealistic appearance and limited diversity. We instead propose Semantic Data Augmentation (SDA), a method that augments images by pasting segmented body parts with various semantic granularity. Furthermore, we propose Adversarial Semantic Data Augmentation (ASDA), which exploits a generative network to dynamiclly predict tailored pasting configuration. Given off-the-shelf pose estimation network as discriminator, the generator seeks the most confusing transformation to increase the loss of the discriminator while the discriminator takes the generated sample as input and learns from it. The whole pipeline is optimized in an adversarial manner. State-of-the-art results are achieved on challenging benchmarks.
Dense Scene Multiple Object Tracking with Box-Plane Matching
Jul 30, 2020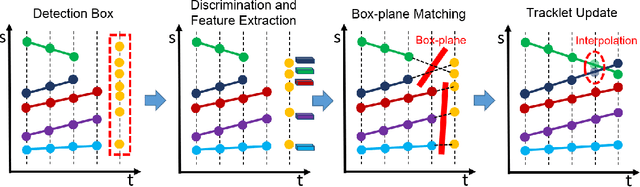
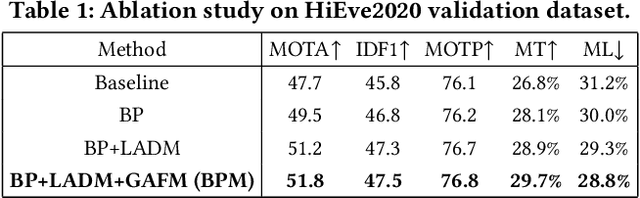
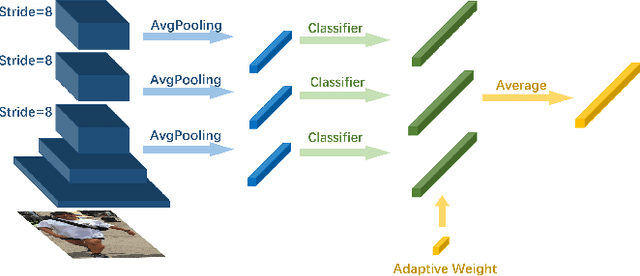
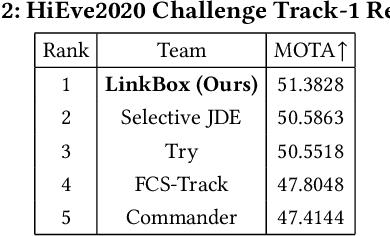
Multiple Object Tracking (MOT) is an important task in computer vision. MOT is still challenging due to the occlusion problem, especially in dense scenes. Following the tracking-by-detection framework, we propose the Box-Plane Matching (BPM) method to improve the MOT performacne in dense scenes. First, we design the Layer-wise Aggregation Discriminative Model (LADM) to filter the noisy detections. Then, to associate remaining detections correctly, we introduce the Global Attention Feature Model (GAFM) to extract appearance feature and use it to calculate the appearance similarity between history tracklets and current detections. Finally, we propose the Box-Plane Matching strategy to achieve data association according to the motion similarity and appearance similarity between tracklets and detections. With the effectiveness of the three modules, our team achieves the 1st place on the Track-1 leaderboard in the ACM MM Grand Challenge HiEve 2020.
Chained-Tracker: Chaining Paired Attentive Regression Results for End-to-End Joint Multiple-Object Detection and Tracking
Jul 29, 2020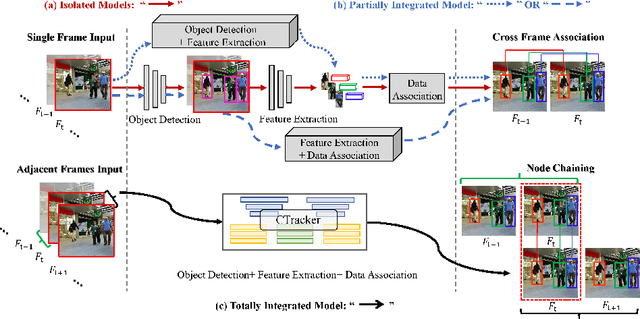

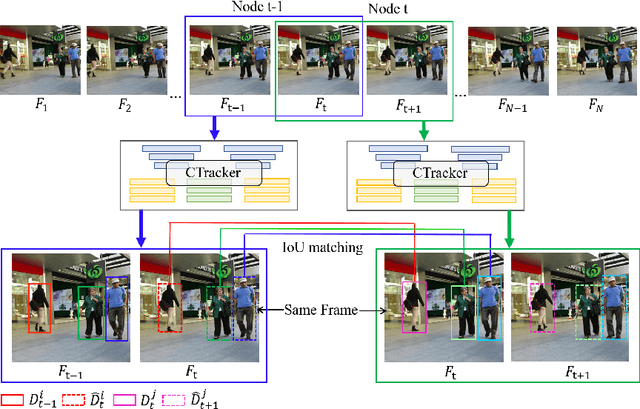
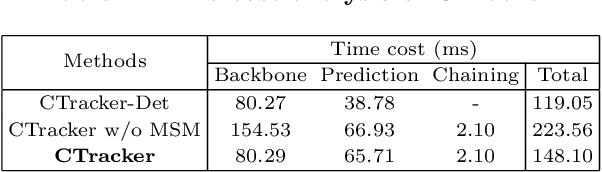
Existing Multiple-Object Tracking (MOT) methods either follow the tracking-by-detection paradigm to conduct object detection, feature extraction and data association separately, or have two of the three subtasks integrated to form a partially end-to-end solution. Going beyond these sub-optimal frameworks, we propose a simple online model named Chained-Tracker (CTracker), which naturally integrates all the three subtasks into an end-to-end solution (the first as far as we know). It chains paired bounding boxes regression results estimated from overlapping nodes, of which each node covers two adjacent frames. The paired regression is made attentive by object-attention (brought by a detection module) and identity-attention (ensured by an ID verification module). The two major novelties: chained structure and paired attentive regression, make CTracker simple, fast and effective, setting new MOTA records on MOT16 and MOT17 challenge datasets (67.6 and 66.6, respectively), without relying on any extra training data. The source code of CTracker can be found at: github.com/pjl1995/CTracker.
NOH-NMS: Improving Pedestrian Detection by Nearby Objects Hallucination
Jul 27, 2020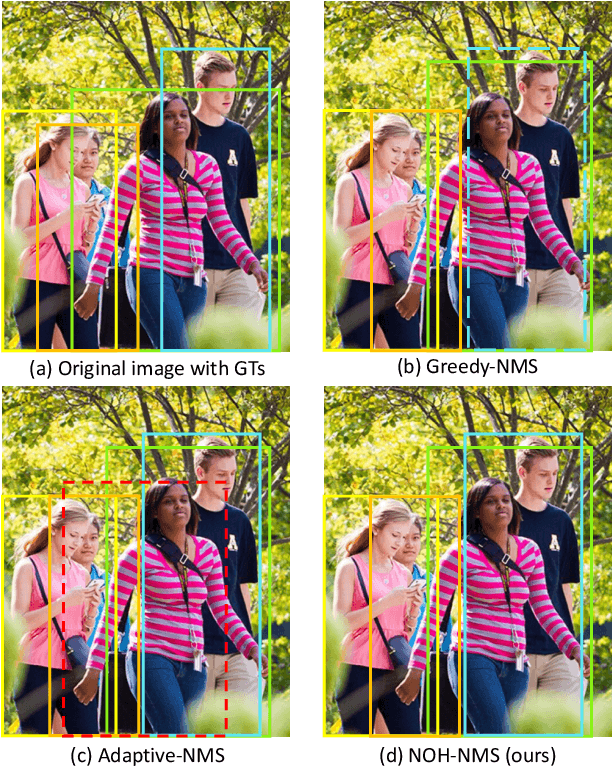
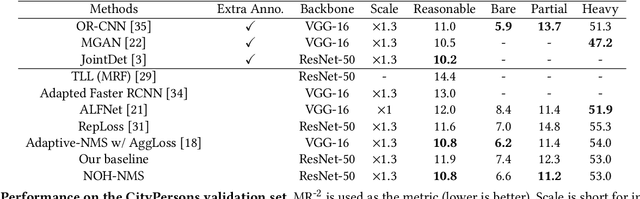

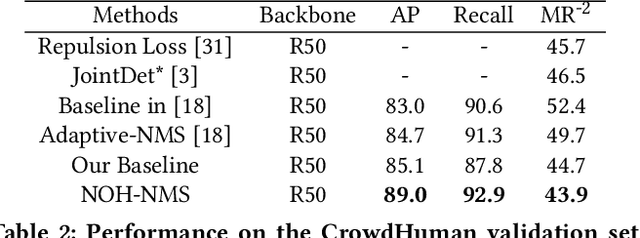
Greedy-NMS inherently raises a dilemma, where a lower NMS threshold will potentially lead to a lower recall rate and a higher threshold introduces more false positives. This problem is more severe in pedestrian detection because the instance density varies more intensively. However, previous works on NMS don't consider or vaguely consider the factor of the existent of nearby pedestrians. Thus, we propose Nearby Objects Hallucinator (NOH), which pinpoints the objects nearby each proposal with a Gaussian distribution, together with NOH-NMS, which dynamically eases the suppression for the space that might contain other objects with a high likelihood. Compared to Greedy-NMS, our method, as the state-of-the-art, improves by $3.9\%$ AP, $5.1\%$ Recall, and $0.8\%$ $\text{MR}^{-2}$ on CrowdHuman to $89.0\%$ AP and $92.9\%$ Recall, and $43.9\%$ $\text{MR}^{-2}$ respectively.
Temporal Distinct Representation Learning for Action Recognition
Jul 15, 2020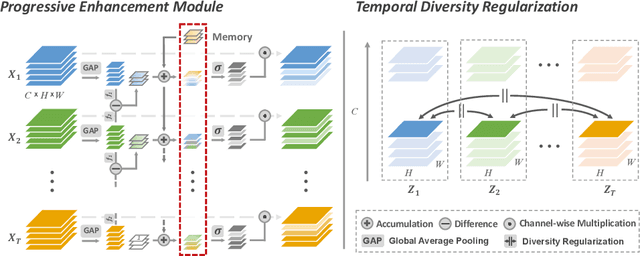
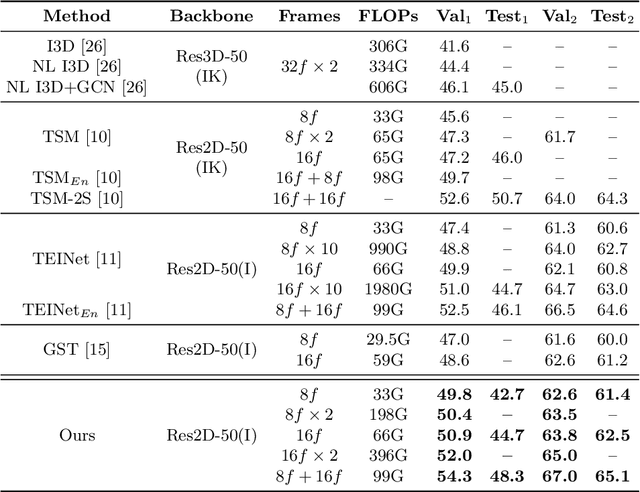
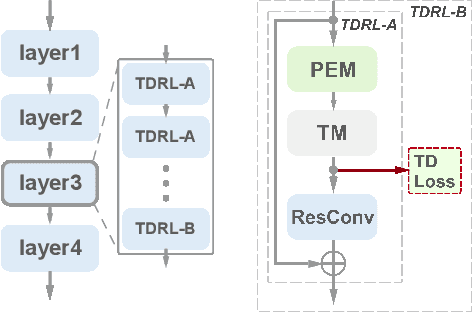
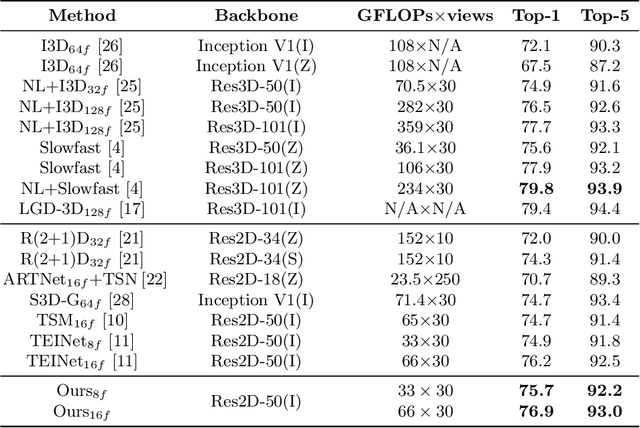
Motivated by the previous success of Two-Dimensional Convolutional Neural Network (2D CNN) on image recognition, researchers endeavor to leverage it to characterize videos. However, one limitation of applying 2D CNN to analyze videos is that different frames of a video share the same 2D CNN kernels, which may result in repeated and redundant information utilization, especially in the spatial semantics extraction process, hence neglecting the critical variations among frames. In this paper, we attempt to tackle this issue through two ways. 1) Design a sequential channel filtering mechanism, i.e., Progressive Enhancement Module (PEM), to excite the discriminative channels of features from different frames step by step, and thus avoid repeated information extraction. 2) Create a Temporal Diversity Loss (TD Loss) to force the kernels to concentrate on and capture the variations among frames rather than the image regions with similar appearance. Our method is evaluated on benchmark temporal reasoning datasets Something-Something V1 and V2, and it achieves visible improvements over the best competitor by 2.4% and 1.3%, respectively. Besides, performance improvements over the 2D-CNN-based state-of-the-arts on the large-scale dataset Kinetics are also witnessed.
Collaborative Learning for Faster StyleGAN Embedding
Jul 03, 2020
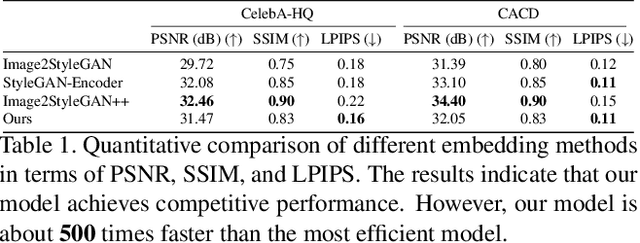
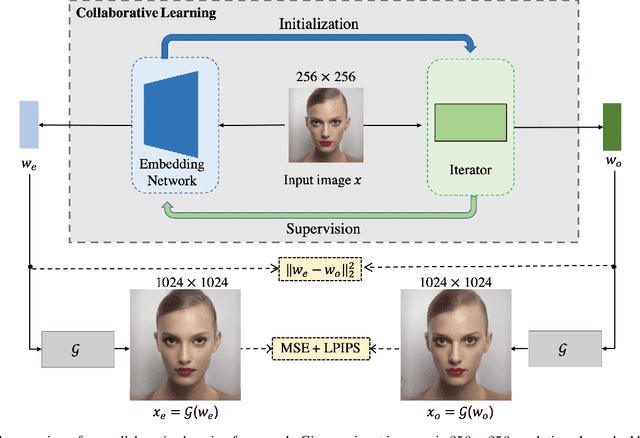
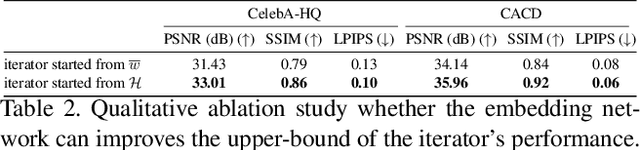
The latent code of the recent popular model StyleGAN has learned disentangled representations thanks to the multi-layer style-based generator. Embedding a given image back to the latent space of StyleGAN enables wide interesting semantic image editing applications. Although previous works are able to yield impressive inversion results based on an optimization framework, which however suffers from the efficiency issue. In this work, we propose a novel collaborative learning framework that consists of an efficient embedding network and an optimization-based iterator. On one hand, with the progress of training, the embedding network gives a reasonable latent code initialization for the iterator. On the other hand, the updated latent code from the iterator in turn supervises the embedding network. In the end, high-quality latent code can be obtained efficiently with a single forward pass through our embedding network. Extensive experiments demonstrate the effectiveness and efficiency of our work.