 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall Vision-Language Models are Smart Compressors for Long Video Understanding
Apr 09, 2026Adapting Multimodal Large Language Models (MLLMs) for hour-long videos is bottlenecked by context limits. Dense visual streams saturate token budgets and exacerbate the lost-in-the-middle phenomenon. Existing heuristics, like sparse sampling or uniform pooling, blindly sacrifice fidelity by discarding decisive moments and wasting bandwidth on irrelevant backgrounds. We propose Tempo, an efficient query-aware framework compressing long videos for downstream understanding. Tempo leverages a Small Vision-Language Model (SVLM) as a local temporal compressor, casting token reduction as an early cross-modal distillation process to generate compact, intent-aligned representations in a single forward pass. To enforce strict budgets without breaking causality, we introduce Adaptive Token Allocation (ATA). Exploiting the SVLM's zero-shot relevance prior and semantic front-loading, ATA acts as a training-free $O(1)$ dynamic router. It allocates dense bandwidth to query-critical segments while compressing redundancies into minimal temporal anchors to maintain the global storyline. Extensive experiments show our 6B architecture achieves state-of-the-art performance with aggressive dynamic compression (0.5-16 tokens/frame). On the extreme-long LVBench (4101s), Tempo scores 52.3 under a strict 8K visual budget, outperforming GPT-4o and Gemini 1.5 Pro. Scaling to 2048 frames reaches 53.7. Crucially, Tempo compresses hour-long videos substantially below theoretical limits, proving true long-form video understanding relies on intent-driven efficiency rather than greedily padded context windows.
dTRPO: Trajectory Reduction in Policy Optimization of Diffusion Large Language Models
Mar 19, 2026Diffusion Large Language Models (dLLMs) introduce a new paradigm for language generation, which in turn presents new challenges for aligning them with human preferences. In this work, we aim to improve the policy optimization for dLLMs by reducing the cost of the trajectory probability calculation, thereby enabling scaled-up offline policy training. We prove that: (i) under reference policy regularization, the probability ratio of the newly unmasked tokens is an unbiased estimate of that of intermediate diffusion states, and (ii) the probability of the full trajectory can be effectively estimated with a single forward pass of a re-masked final state. By integrating these two trajectory reduction strategies into a policy optimization objective, we propose Trajectory Reduction Policy Optimization (dTRPO). We evaluate dTRPO on 7B dLLMs across instruction-following and reasoning benchmarks. Results show that it substantially improves the core performance of state-of-the-art dLLMs, achieving gains of up to 9.6% on STEM tasks, up to 4.3% on coding tasks, and up to 3.0% on instruction-following tasks. Moreover, dTRPO exhibits strong training efficiency due to its offline, single-forward nature, and achieves improved generation efficiency through high-quality outputs.
VideoAuto-R1: Video Auto Reasoning via Thinking Once, Answering Twice
Jan 08, 2026Chain-of-thought (CoT) reasoning has emerged as a powerful tool for multimodal large language models on video understanding tasks. However, its necessity and advantages over direct answering remain underexplored. In this paper, we first demonstrate that for RL-trained video models, direct answering often matches or even surpasses CoT performance, despite CoT producing step-by-step analyses at a higher computational cost. Motivated by this, we propose VideoAuto-R1, a video understanding framework that adopts a reason-when-necessary strategy. During training, our approach follows a Thinking Once, Answering Twice paradigm: the model first generates an initial answer, then performs reasoning, and finally outputs a reviewed answer. Both answers are supervised via verifiable rewards. During inference, the model uses the confidence score of the initial answer to determine whether to proceed with reasoning. Across video QA and grounding benchmarks, VideoAuto-R1 achieves state-of-the-art accuracy with significantly improved efficiency, reducing the average response length by ~3.3x, e.g., from 149 to just 44 tokens. Moreover, we observe a low rate of thinking-mode activation on perception-oriented tasks, but a higher rate on reasoning-intensive tasks. This suggests that explicit language-based reasoning is generally beneficial but not always necessary.
Vision Transformers with Self-Distilled Registers
May 27, 2025Vision Transformers (ViTs) have emerged as the dominant architecture for visual processing tasks, demonstrating excellent scalability with increased training data and model size. However, recent work has identified the emergence of artifact tokens in ViTs that are incongruous with the local semantics. These anomalous tokens degrade ViT performance in tasks that require fine-grained localization or structural coherence. An effective mitigation of this issue is to the addition of register tokens to ViTs, which implicitly "absorb" the artifact term during training. Given the availability of various large-scale pre-trained ViTs, in this paper we aim at equipping them with such register tokens without the need of re-training them from scratch, which is infeasible considering their size. Specifically, we propose Post Hoc Registers (PH-Reg), an efficient self-distillation method that integrates registers into an existing ViT without requiring additional labeled data and full retraining. PH-Reg initializes both teacher and student networks from the same pre-trained ViT. The teacher remains frozen and unmodified, while the student is augmented with randomly initialized register tokens. By applying test-time augmentation to the teacher's inputs, we generate denoised dense embeddings free of artifacts, which are then used to optimize only a small subset of unlocked student weights. We show that our approach can effectively reduce the number of artifact tokens, improving the segmentation and depth prediction of the student ViT under zero-shot and linear probing.
EdgeTAM: On-Device Track Anything Model
Jan 13, 2025On top of Segment Anything Model (SAM), SAM 2 further extends its capability from image to video inputs through a memory bank mechanism and obtains a remarkable performance compared with previous methods, making it a foundation model for video segmentation task. In this paper, we aim at making SAM 2 much more efficient so that it even runs on mobile devices while maintaining a comparable performance. Despite several works optimizing SAM for better efficiency, we find they are not sufficient for SAM 2 because they all focus on compressing the image encoder, while our benchmark shows that the newly introduced memory attention blocks are also the latency bottleneck. Given this observation, we propose EdgeTAM, which leverages a novel 2D Spatial Perceiver to reduce the computational cost. In particular, the proposed 2D Spatial Perceiver encodes the densely stored frame-level memories with a lightweight Transformer that contains a fixed set of learnable queries. Given that video segmentation is a dense prediction task, we find preserving the spatial structure of the memories is essential so that the queries are split into global-level and patch-level groups. We also propose a distillation pipeline that further improves the performance without inference overhead. As a result, EdgeTAM achieves 87.7, 70.0, 72.3, and 71.7 J&F on DAVIS 2017, MOSE, SA-V val, and SA-V test, while running at 16 FPS on iPhone 15 Pro Max.
Efficient Track Anything
Nov 28, 2024Segment Anything Model 2 (SAM 2) has emerged as a powerful tool for video object segmentation and tracking anything. Key components of SAM 2 that drive the impressive video object segmentation performance include a large multistage image encoder for frame feature extraction and a memory mechanism that stores memory contexts from past frames to help current frame segmentation. The high computation complexity of multistage image encoder and memory module has limited its applications in real-world tasks, e.g., video object segmentation on mobile devices. To address this limitation, we propose EfficientTAMs, lightweight track anything models that produce high-quality results with low latency and model size. Our idea is based on revisiting the plain, nonhierarchical Vision Transformer (ViT) as an image encoder for video object segmentation, and introducing an efficient memory module, which reduces the complexity for both frame feature extraction and memory computation for current frame segmentation. We take vanilla lightweight ViTs and efficient memory module to build EfficientTAMs, and train the models on SA-1B and SA-V datasets for video object segmentation and track anything tasks. We evaluate on multiple video segmentation benchmarks including semi-supervised VOS and promptable video segmentation, and find that our proposed EfficientTAM with vanilla ViT perform comparably to SAM 2 model (HieraB+SAM 2) with ~2x speedup on A100 and ~2.4x parameter reduction. On segment anything image tasks, our EfficientTAMs also perform favorably over original SAM with ~20x speedup on A100 and ~20x parameter reduction. On mobile devices such as iPhone 15 Pro Max, our EfficientTAMs can run at ~10 FPS for performing video object segmentation with reasonable quality, highlighting the capability of small models for on-device video object segmentation applications.
Open-Vocabulary SAM: Segment and Recognize Twenty-thousand Classes Interactively
Jan 05, 2024The CLIP and Segment Anything Model (SAM) are remarkable vision foundation models (VFMs). SAM excels in segmentation tasks across diverse domains, while CLIP is renowned for its zero-shot recognition capabilities. This paper presents an in-depth exploration of integrating these two models into a unified framework. Specifically, we introduce the Open-Vocabulary SAM, a SAM-inspired model designed for simultaneous interactive segmentation and recognition, leveraging two unique knowledge transfer modules: SAM2CLIP and CLIP2SAM. The former adapts SAM's knowledge into the CLIP via distillation and learnable transformer adapters, while the latter transfers CLIP knowledge into SAM, enhancing its recognition capabilities. Extensive experiments on various datasets and detectors show the effectiveness of Open-Vocabulary SAM in both segmentation and recognition tasks, significantly outperforming the naive baselines of simply combining SAM and CLIP. Furthermore, aided with image classification data training, our method can segment and recognize approximately 22,000 classes.
EdgeSAM: Prompt-In-the-Loop Distillation for On-Device Deployment of SAM
Dec 11, 2023This paper presents EdgeSAM, an accelerated variant of the Segment Anything Model (SAM), optimized for efficient execution on edge devices with minimal compromise in performance. Our approach involves distilling the original ViT-based SAM image encoder into a purely CNN-based architecture, better suited for edge devices. We carefully benchmark various distillation strategies and demonstrate that task-agnostic encoder distillation fails to capture the full knowledge embodied in SAM. To overcome this bottleneck, we include both the prompt encoder and mask decoder in the distillation process, with box and point prompts in the loop, so that the distilled model can accurately capture the intricate dynamics between user input and mask generation. To mitigate dataset bias issues stemming from point prompt distillation, we incorporate a lightweight module within the encoder. EdgeSAM achieves a 40-fold speed increase compared to the original SAM, and it also outperforms MobileSAM, being 14 times as fast when deployed on edge devices while enhancing the mIoUs on COCO and LVIS by 2.3 and 3.2 respectively. It is also the first SAM variant that can run at over 30 FPS on an iPhone 14. Code and models are available at https://github.com/chongzhou96/EdgeSAM.
Interpret Vision Transformers as ConvNets with Dynamic Convolutions
Sep 19, 2023There has been a debate about the superiority between vision Transformers and ConvNets, serving as the backbone of computer vision models. Although they are usually considered as two completely different architectures, in this paper, we interpret vision Transformers as ConvNets with dynamic convolutions, which enables us to characterize existing Transformers and dynamic ConvNets in a unified framework and compare their design choices side by side. In addition, our interpretation can also guide the network design as researchers now can consider vision Transformers from the design space of ConvNets and vice versa. We demonstrate such potential through two specific studies. First, we inspect the role of softmax in vision Transformers as the activation function and find it can be replaced by commonly used ConvNets modules, such as ReLU and Layer Normalization, which results in a faster convergence rate and better performance. Second, following the design of depth-wise convolution, we create a corresponding depth-wise vision Transformer that is more efficient with comparable performance. The potential of the proposed unified interpretation is not limited to the given examples and we hope it can inspire the community and give rise to more advanced network architectures.
DenseCLIP: Extract Free Dense Labels from CLIP
Dec 02, 2021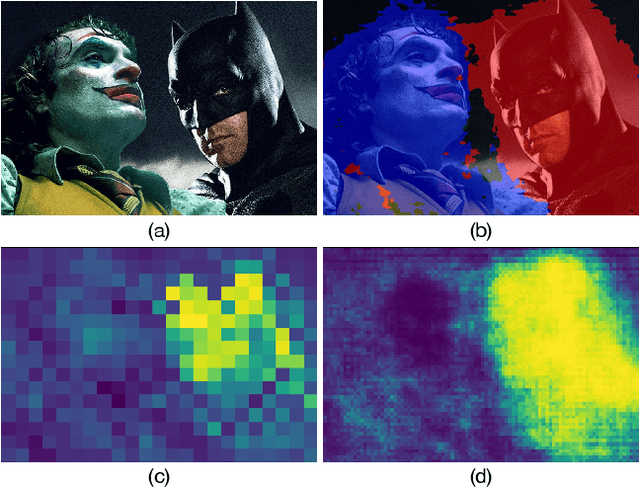
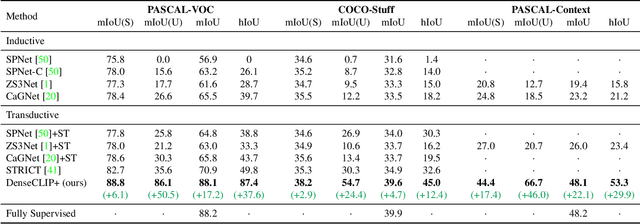
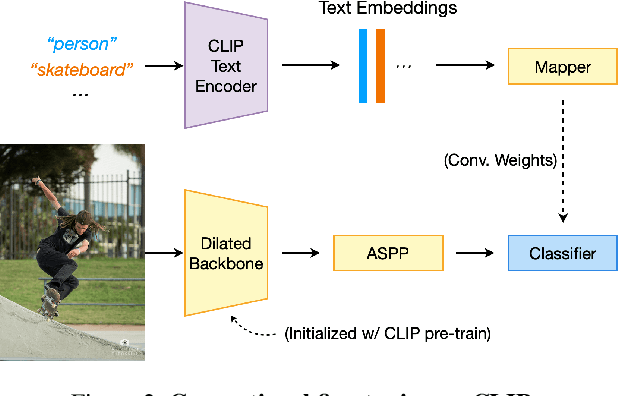

Contrastive Language-Image Pre-training (CLIP) has made a remarkable breakthrough in open-vocabulary zero-shot image recognition. Many recent studies leverage the pre-trained CLIP models for image-level classification and manipulation. In this paper, we further explore the potentials of CLIP for pixel-level dense prediction, specifically in semantic segmentation. Our method, DenseCLIP, in the absence of annotations and fine-tuning, yields reasonable segmentation results on open concepts across various datasets. By adding pseudo labeling and self-training, DenseCLIP+ surpasses SOTA transductive zero-shot semantic segmentation methods by large margins, e.g., mIoUs of unseen classes on PASCAL VOC/PASCAL Context/COCO Stuff are improved from 35.6/20.7/30.3 to 86.1/66.7/54.7. We also test the robustness of DenseCLIP under input corruption and evaluate its capability in discriminating fine-grained objects and novel concepts. Our finding suggests that DenseCLIP can serve as a new reliable source of supervision for dense prediction tasks to achieve annotation-free segmentation.