 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVINS-120K: Ultra High-Resolution Image Editing with A Large-Scale Dataset
May 22, 2026Directly editing ultra-high-resolution (UHR) images is valuable but underexplored, primarily due to the lack of high-quality data and the challenge in modeling high-frequency texture details. We introduce VINS-120K, the first large-scale dataset for instruction-based UHR image editing, comprising 120K carefully curated triplets of instruction, input image, and edited image. Each image exceeds 4K resolution ($\geq$4096 $\times$ 4096) and is filtered through a rigorous multi-stage pipeline to ensure visual quality, instruction alignment, and aesthetic fidelity. Built on VINS-120K, we further develop a high-frequency-aware post-adaptation strategy to extend pretrained non-high-resolution models to the UHR regime. We also present VINS-4KEval, a benchmark covering diverse editing types, to facilitate consistent evaluation in UHR settings. Experiments confirm that our work improves fine-grained detail synthesis and texture realism in UHR image editing.
Octopus: History-Free Gradient Orthogonalization for Continual Learning in Multimodal Large Language Models
May 14, 2026Continual learning in multimodal large language models (MLLMs) aims to sequentially acquire knowledge while mitigating catastrophic forgetting, yet existing methods face inherent limitations: architecture-based approaches incur additional computational overhead and often generalize poorly to new tasks, rehearsal-based methods rely on storing historical data, raising privacy and storage concerns, and conventional regularization-based strategies alone are insufficient to fully prevent parameter interference. We propose Octopus, a two-stage continual learning framework based on History-Free Gradient Orthogonalization (HiFGO), which enforces gradient-level orthogonality without historical task data. Our proposed two-stage finetuning strategy decouples task adaptation from regularization, achieving a principled balance between plasticity and stability. Experiments on UCIT show that Octopus establishes state-of-the-art performance, surpassing prior SOTA by 2.14% and 6.82% in terms of Avg and Last.
ACE-LoRA: Adaptive Orthogonal Decoupling for Continual Image Editing
May 14, 2026State-of-the-art diffusion models often rely on parameter-efficient fine-tuning to perform specialized image editing tasks. However, real-world applications require continual adaptation to new tasks while preserving previously learned knowledge. Despite the practical necessity, continual learning for image editing remains largely underexplored. We propose ACE-LoRA, a dynamic regularization framework for continual image editing that effectively mitigates catastrophic forgetting. ACE-LoRA leverages Adaptive Orthogonal Decoupling to identify and orthogonalize task interference, and introduces a Rank-Invariant Historical Information Compression strategy to address scalability issues in continual updates. To facilitate continual learning in image editing and provide a standardized evaluation protocol, we introduce CIE-Bench, the first comprehensive benchmark in this domain. CIE-Bench encompasses diverse and practically relevant image editing scenarios with a balanced level of difficulty to effectively expose limitations of existing models while remaining compatible with parameter-efficient fine-tuning. Extensive experiments demonstrate that our method consistently outperforms existing baselines in terms of instruction fidelity, visual realism, and robustness to forgetting, establishing a strong foundation for continual learning in image editing.
Guiding a Diffusion Model by Swapping Its Tokens
Apr 09, 2026Classifier-Free Guidance (CFG) is a widely used inference-time technique to boost the image quality of diffusion models. Yet, its reliance on text conditions prevents its use in unconditional generation. We propose a simple method to enable CFG-like guidance for both conditional and unconditional generation. The key idea is to generate a perturbed prediction via simple token swap operations, and use the direction between it and the clean prediction to steer sampling towards higher-fidelity distributions. In practice, we swap pairs of most semantically dissimilar token latents in either spatial or channel dimensions. Unlike existing methods that apply perturbation in a global or less constrained manner, our approach selectively exchanges and recomposes token latents, allowing finer control over perturbation and its influence on generated samples. Experiments on MS-COCO 2014, MS-COCO 2017, and ImageNet datasets demonstrate that the proposed Self-Swap Guidance (SSG), when applied to popular diffusion models, outperforms previous condition-free methods in image fidelity and prompt alignment under different set-ups. Its fine-grained perturbation granularity also improves robustness, reducing side-effects across a wider range of perturbation strengths. Overall, SSG extends CFG to a broader scope of applications including both conditional and unconditional generation, and can be readily inserted into any diffusion model as a plug-in to gain immediate improvements.
UltraHR-100K: Enhancing UHR Image Synthesis with A Large-Scale High-Quality Dataset
Oct 23, 2025



Ultra-high-resolution (UHR) text-to-image (T2I) generation has seen notable progress. However, two key challenges remain : 1) the absence of a large-scale high-quality UHR T2I dataset, and (2) the neglect of tailored training strategies for fine-grained detail synthesis in UHR scenarios. To tackle the first challenge, we introduce \textbf{UltraHR-100K}, a high-quality dataset of 100K UHR images with rich captions, offering diverse content and strong visual fidelity. Each image exceeds 3K resolution and is rigorously curated based on detail richness, content complexity, and aesthetic quality. To tackle the second challenge, we propose a frequency-aware post-training method that enhances fine-detail generation in T2I diffusion models. Specifically, we design (i) \textit{Detail-Oriented Timestep Sampling (DOTS)} to focus learning on detail-critical denoising steps, and (ii) \textit{Soft-Weighting Frequency Regularization (SWFR)}, which leverages Discrete Fourier Transform (DFT) to softly constrain frequency components, encouraging high-frequency detail preservation. Extensive experiments on our proposed UltraHR-eval4K benchmarks demonstrate that our approach significantly improves the fine-grained detail quality and overall fidelity of UHR image generation. The code is available at \href{https://github.com/NJU-PCALab/UltraHR-100k}{here}.
Neural Material Adaptor for Visual Grounding of Intrinsic Dynamics
Oct 10, 2024



While humans effortlessly discern intrinsic dynamics and adapt to new scenarios, modern AI systems often struggle. Current methods for visual grounding of dynamics either use pure neural-network-based simulators (black box), which may violate physical laws, or traditional physical simulators (white box), which rely on expert-defined equations that may not fully capture actual dynamics. We propose the Neural Material Adaptor (NeuMA), which integrates existing physical laws with learned corrections, facilitating accurate learning of actual dynamics while maintaining the generalizability and interpretability of physical priors. Additionally, we propose Particle-GS, a particle-driven 3D Gaussian Splatting variant that bridges simulation and observed images, allowing back-propagate image gradients to optimize the simulator. Comprehensive experiments on various dynamics in terms of grounded particle accuracy, dynamic rendering quality, and generalization ability demonstrate that NeuMA can accurately capture intrinsic dynamics.
HybridBooth: Hybrid Prompt Inversion for Efficient Subject-Driven Generation
Oct 10, 2024



Recent advancements in text-to-image diffusion models have shown remarkable creative capabilities with textual prompts, but generating personalized instances based on specific subjects, known as subject-driven generation, remains challenging. To tackle this issue, we present a new hybrid framework called HybridBooth, which merges the benefits of optimization-based and direct-regression methods. HybridBooth operates in two stages: the Word Embedding Probe, which generates a robust initial word embedding using a fine-tuned encoder, and the Word Embedding Refinement, which further adapts the encoder to specific subject images by optimizing key parameters. This approach allows for effective and fast inversion of visual concepts into textual embedding, even from a single image, while maintaining the model's generalization capabilities.
PostEdit: Posterior Sampling for Efficient Zero-Shot Image Editing
Oct 07, 2024



In the field of image editing, three core challenges persist: controllability, background preservation, and efficiency. Inversion-based methods rely on time-consuming optimization to preserve the features of the initial images, which results in low efficiency due to the requirement for extensive network inference. Conversely, inversion-free methods lack theoretical support for background similarity, as they circumvent the issue of maintaining initial features to achieve efficiency. As a consequence, none of these methods can achieve both high efficiency and background consistency. To tackle the challenges and the aforementioned disadvantages, we introduce PostEdit, a method that incorporates a posterior scheme to govern the diffusion sampling process. Specifically, a corresponding measurement term related to both the initial features and Langevin dynamics is introduced to optimize the estimated image generated by the given target prompt. Extensive experimental results indicate that the proposed PostEdit achieves state-of-the-art editing performance while accurately preserving unedited regions. Furthermore, the method is both inversion- and training-free, necessitating approximately 1.5 seconds and 18 GB of GPU memory to generate high-quality results.
PTSEFormer: Progressive Temporal-Spatial Enhanced TransFormer Towards Video Object Detection
Sep 06, 2022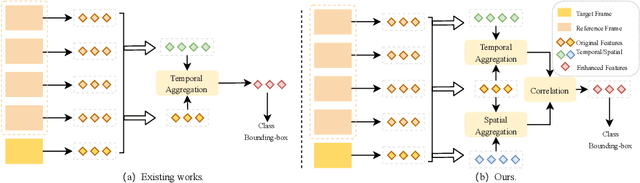
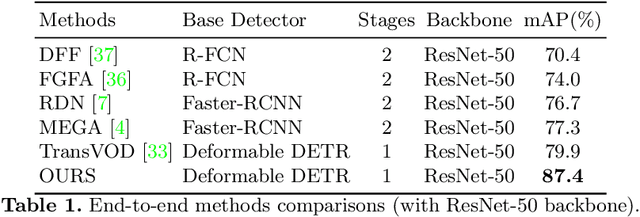
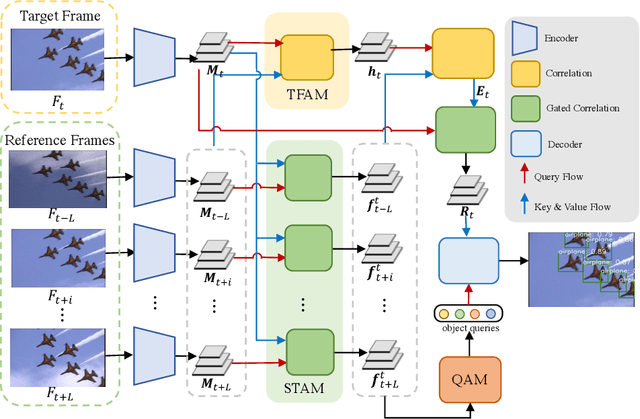
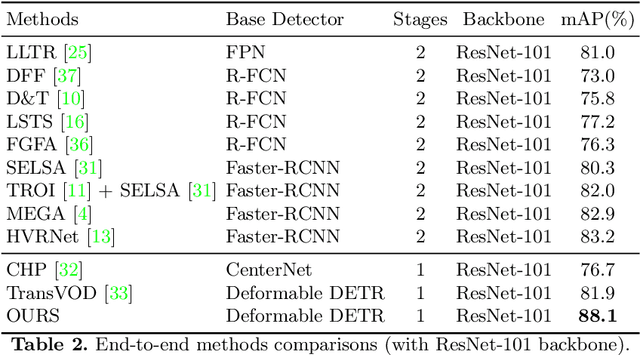
Recent years have witnessed a trend of applying context frames to boost the performance of object detection as video object detection. Existing methods usually aggregate features at one stroke to enhance the feature. These methods, however, usually lack spatial information from neighboring frames and suffer from insufficient feature aggregation. To address the issues, we perform a progressive way to introduce both temporal information and spatial information for an integrated enhancement. The temporal information is introduced by the temporal feature aggregation model (TFAM), by conducting an attention mechanism between the context frames and the target frame (i.e., the frame to be detected). Meanwhile, we employ a Spatial Transition Awareness Model (STAM) to convey the location transition information between each context frame and target frame. Built upon a transformer-based detector DETR, our PTSEFormer also follows an end-to-end fashion to avoid heavy post-processing procedures while achieving 88.1% mAP on the ImageNet VID dataset. Codes are available at https://github.com/Hon-Wong/PTSEFormer.
NeuroFluid: Fluid Dynamics Grounding with Particle-Driven Neural Radiance Fields
Mar 03, 2022



Deep learning has shown great potential for modeling the physical dynamics of complex particle systems such as fluids (in Lagrangian descriptions). Existing approaches, however, require the supervision of consecutive particle properties, including positions and velocities. In this paper, we consider a partially observable scenario known as fluid dynamics grounding, that is, inferring the state transitions and interactions within the fluid particle systems from sequential visual observations of the fluid surface. We propose a differentiable two-stage network named NeuroFluid. Our approach consists of (i) a particle-driven neural renderer, which involves fluid physical properties into the volume rendering function, and (ii) a particle transition model optimized to reduce the differences between the rendered and the observed images. NeuroFluid provides the first solution to unsupervised learning of particle-based fluid dynamics by training these two models jointly. It is shown to reasonably estimate the underlying physics of fluids with different initial shapes, viscosity, and densities. It is a potential alternative approach to understanding complex fluid mechanics, such as turbulence, that are difficult to model using traditional methods of mathematical physics.