 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiasing Learning for Membership Inference Attacks Against Recommender Systems
Jun 28, 2022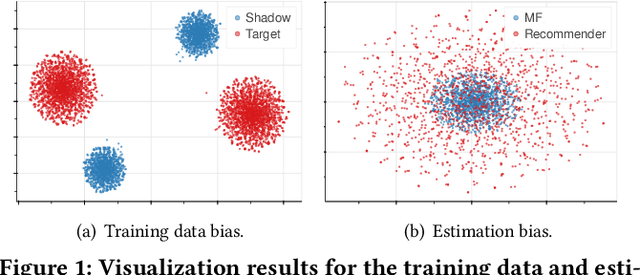
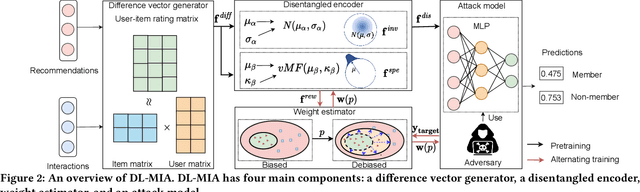
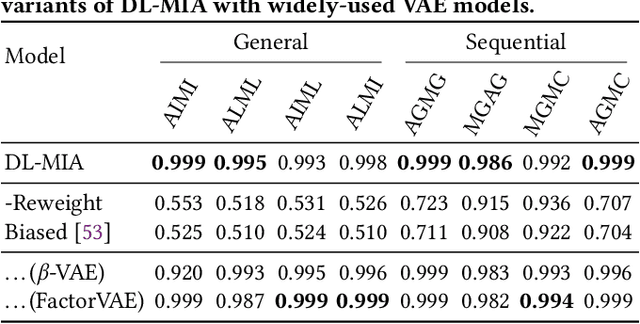
Learned recommender systems may inadvertently leak information about their training data, leading to privacy violations. We investigate privacy threats faced by recommender systems through the lens of membership inference. In such attacks, an adversary aims to infer whether a user's data is used to train the target recommender. To achieve this, previous work has used a shadow recommender to derive training data for the attack model, and then predicts the membership by calculating difference vectors between users' historical interactions and recommended items. State-of-the-art methods face two challenging problems: (1) training data for the attack model is biased due to the gap between shadow and target recommenders, and (2) hidden states in recommenders are not observational, resulting in inaccurate estimations of difference vectors. To address the above limitations, we propose a Debiasing Learning for Membership Inference Attacks against recommender systems (DL-MIA) framework that has four main components: (1) a difference vector generator, (2) a disentangled encoder, (3) a weight estimator, and (4) an attack model. To mitigate the gap between recommenders, a variational auto-encoder (VAE) based disentangled encoder is devised to identify recommender invariant and specific features. To reduce the estimation bias, we design a weight estimator, assigning a truth-level score for each difference vector to indicate estimation accuracy. We evaluate DL-MIA against both general recommenders and sequential recommenders on three real-world datasets. Experimental results show that DL-MIA effectively alleviates training and estimation biases simultaneously, and achieves state-of-the-art attack performance.
Proactively Control Privacy in Recommender Systems
Apr 01, 2022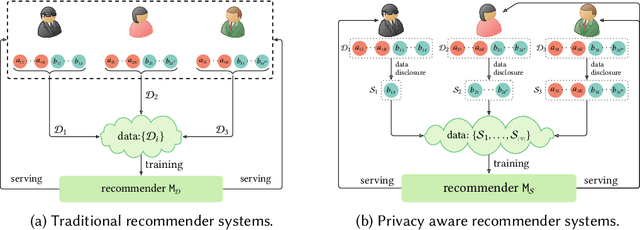
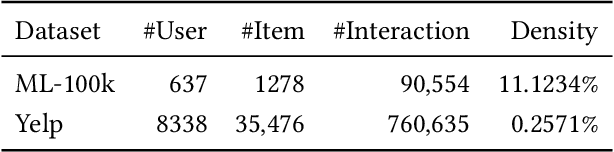
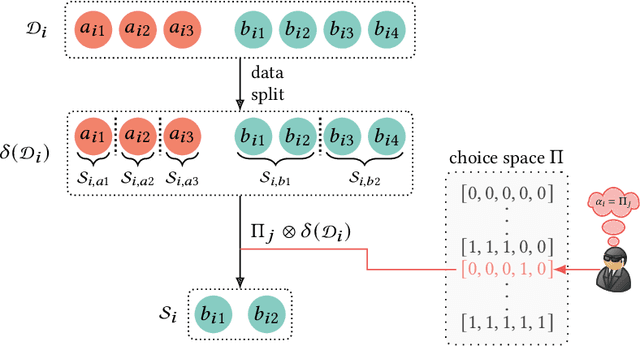
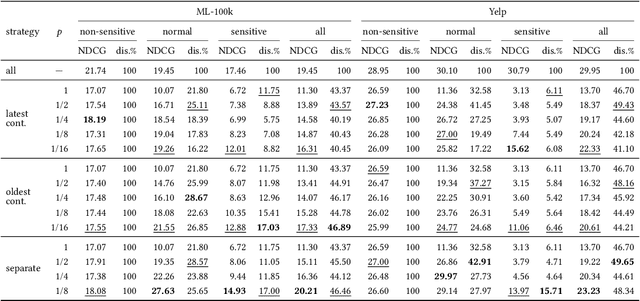
Recently, privacy issues in web services that rely on users' personal data have raised great attention. Unlike existing privacy-preserving technologies such as federated learning and differential privacy, we explore another way to mitigate users' privacy concerns, giving them control over their own data. For this goal, we propose a privacy aware recommendation framework that gives users delicate control over their personal data, including implicit behaviors, e.g., clicks and watches. In this new framework, users can proactively control which data to disclose based on the trade-off between anticipated privacy risks and potential utilities. Then we study users' privacy decision making under different data disclosure mechanisms and recommendation models, and how their data disclosure decisions affect the recommender system's performance. To avoid the high cost of real-world experiments, we apply simulations to study the effects of our proposed framework. Specifically, we propose a reinforcement learning algorithm to simulate users' decisions (with various sensitivities) under three proposed platform mechanisms on two datasets with three representative recommendation models. The simulation results show that the platform mechanisms with finer split granularity and more unrestrained disclosure strategy can bring better results for both end users and platforms than the "all or nothing" binary mechanism adopted by most real-world applications. It also shows that our proposed framework can effectively protect users' privacy since they can obtain comparable or even better results with much less disclosed data.
CHEX: CHannel EXploration for CNN Model Compression
Mar 29, 2022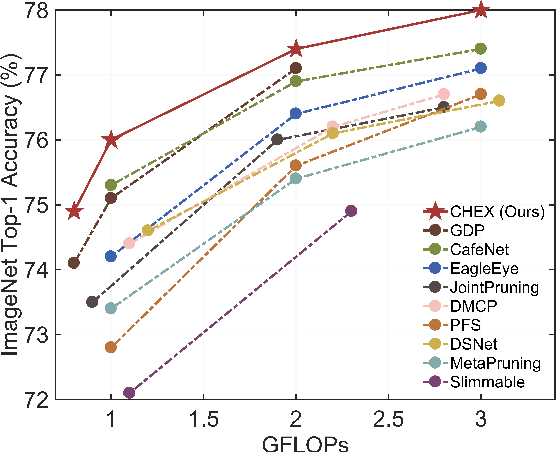
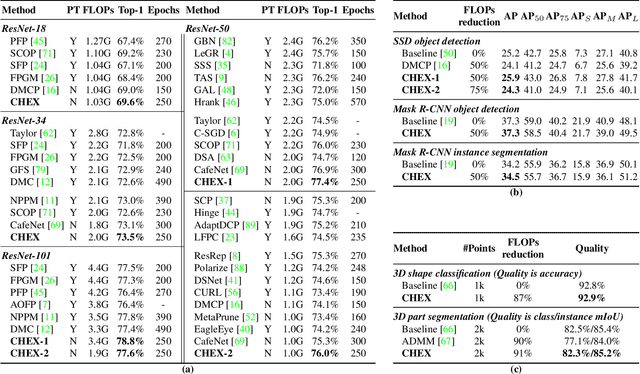
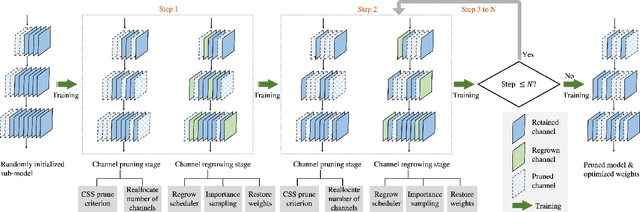

Channel pruning has been broadly recognized as an effective technique to reduce the computation and memory cost of deep convolutional neural networks. However, conventional pruning methods have limitations in that: they are restricted to pruning process only, and they require a fully pre-trained large model. Such limitations may lead to sub-optimal model quality as well as excessive memory and training cost. In this paper, we propose a novel Channel Exploration methodology, dubbed as CHEX, to rectify these problems. As opposed to pruning-only strategy, we propose to repeatedly prune and regrow the channels throughout the training process, which reduces the risk of pruning important channels prematurely. More exactly: From intra-layer's aspect, we tackle the channel pruning problem via a well known column subset selection (CSS) formulation. From inter-layer's aspect, our regrowing stages open a path for dynamically re-allocating the number of channels across all the layers under a global channel sparsity constraint. In addition, all the exploration process is done in a single training from scratch without the need of a pre-trained large model. Experimental results demonstrate that CHEX can effectively reduce the FLOPs of diverse CNN architectures on a variety of computer vision tasks, including image classification, object detection, instance segmentation, and 3D vision. For example, our compressed ResNet-50 model on ImageNet dataset achieves 76% top1 accuracy with only 25% FLOPs of the original ResNet-50 model, outperforming previous state-of-the-art channel pruning methods. The checkpoints and code are available at here .
Neural Re-ranking in Multi-stage Recommender Systems: A Review
Feb 14, 2022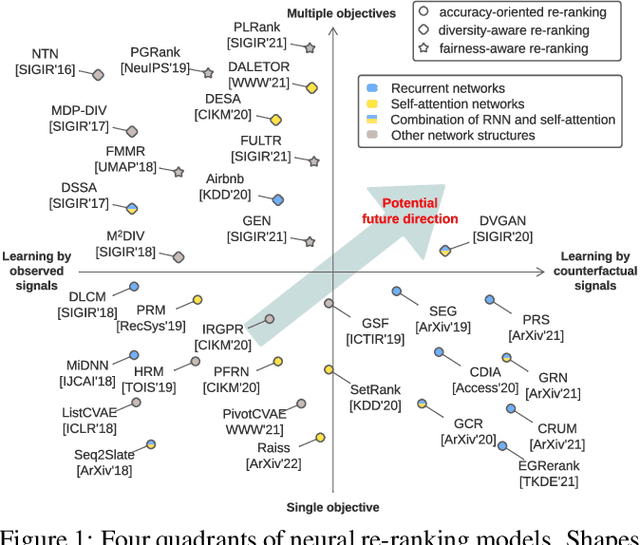
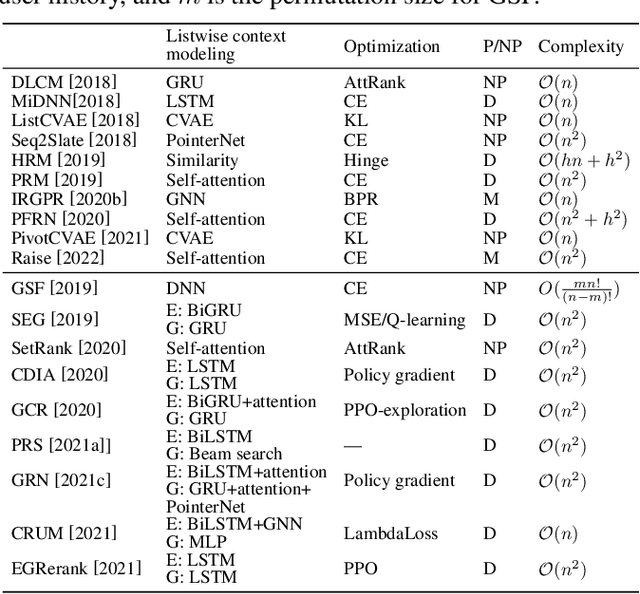
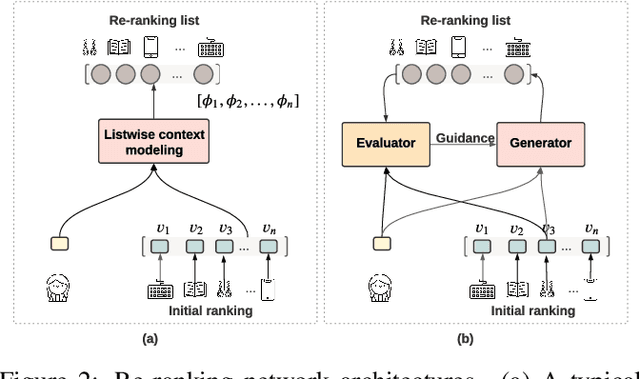
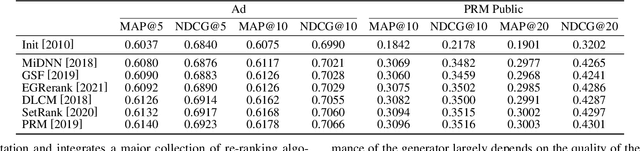
As the final stage of the multi-stage recommender system (MRS), re-ranking directly affects user experience and satisfaction by rearranging the input ranking lists, and thereby plays a critical role in MRS. With the advances in deep learning, neural re-ranking has become a trending topic and been widely applied in industrial applications. This review aims at integrating re-ranking algorithms into a broader picture, and paving ways for more comprehensive solutions for future research. For this purpose, we first present a taxonomy of current methods on neural re-ranking. Then we give a description of these methods along with the historic development according to their objectives. The network structure, personalization, and complexity are also discussed and compared. Next, we provide benchmarks of the major neural re-ranking models and quantitatively analyze their re-ranking performance. Finally, the review concludes with a discussion on future prospects of this field. A list of papers discussed in this review, the benchmark datasets, our re-ranking library LibRerank, and detailed parameter settings are publicly available at https://github.com/LibRerank-Community/LibRerank.
Recommendation Unlearning
Jan 25, 2022
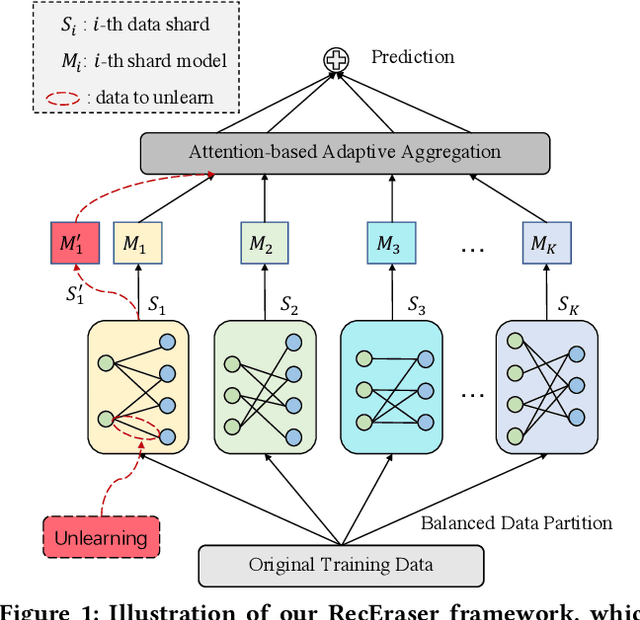
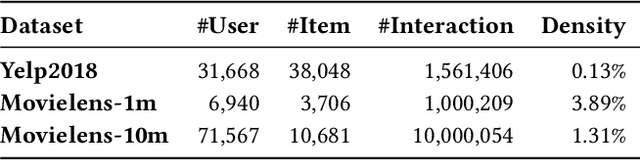
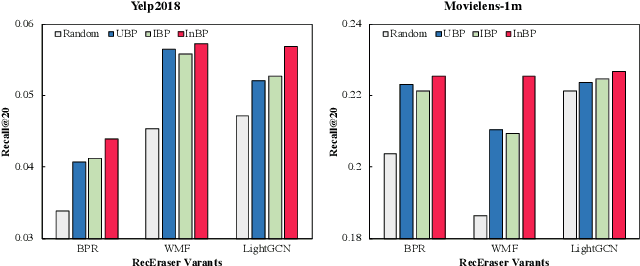
Recommender systems provide essential web services by learning users' personal preferences from collected data. However, in many cases, systems also need to forget some training data. From the perspective of privacy, several privacy regulations have recently been proposed, requiring systems to eliminate any impact of the data whose owner requests to forget. From the perspective of utility, if a system's utility is damaged by some bad data, the system needs to forget these data to regain utility. From the perspective of usability, users can delete noise and incorrect entries so that a system can provide more useful recommendations. While unlearning is very important, it has not been well-considered in existing recommender systems. Although there are some researches have studied the problem of machine unlearning in the domains of image and text data, existing methods can not been directly applied to recommendation as they are unable to consider the collaborative information. In this paper, we propose RecEraser, a general and efficient machine unlearning framework tailored to recommendation task. The main idea of RecEraser is to partition the training set into multiple shards and train a constituent model for each shard. Specifically, to keep the collaborative information of the data, we first design three novel data partition algorithms to divide training data into balanced groups based on their similarity. Then, considering that different shard models do not uniformly contribute to the final prediction, we further propose an adaptive aggregation method to improve the global model utility. Experimental results on three public benchmarks show that RecEraser can not only achieve efficient unlearning, but also outperform the state-of-the-art unlearning methods in terms of model utility. The source code can be found at https://github.com/chenchongthu/Recommendation-Unlearning
Compact Multi-level Sparse Neural Networks with Input Independent Dynamic Rerouting
Dec 21, 2021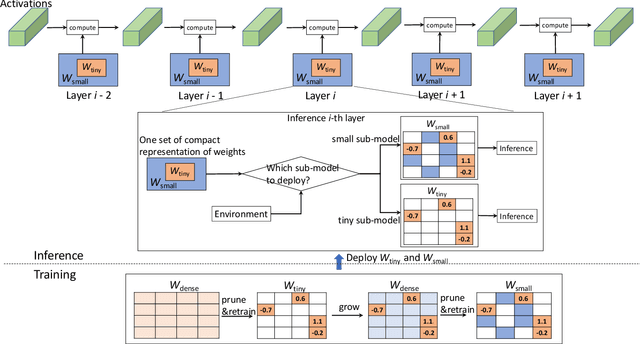

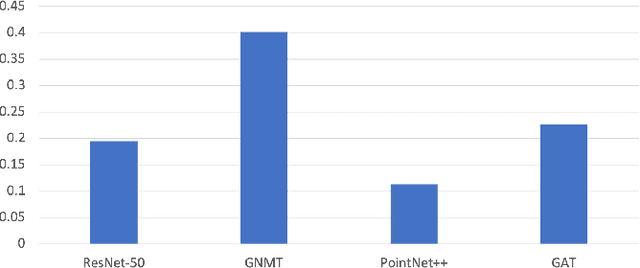
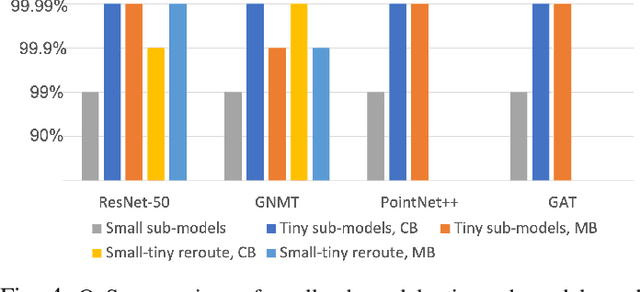
Deep neural networks (DNNs) have shown to provide superb performance in many real life applications, but their large computation cost and storage requirement have prevented them from being deployed to many edge and internet-of-things (IoT) devices. Sparse deep neural networks, whose majority weight parameters are zeros, can substantially reduce the computation complexity and memory consumption of the models. In real-use scenarios, devices may suffer from large fluctuations of the available computation and memory resources under different environment, and the quality of service (QoS) is difficult to maintain due to the long tail inferences with large latency. Facing the real-life challenges, we propose to train a sparse model that supports multiple sparse levels. That is, a hierarchical structure of weights are satisfied such that the locations and the values of the non-zero parameters of the more-sparse sub-model area subset of the less-sparse sub-model. In this way, one can dynamically select the appropriate sparsity level during inference, while the storage cost is capped by the least sparse sub-model. We have verified our methodologies on a variety of DNN models and tasks, including the ResNet-50, PointNet++, GNMT, and graph attention networks. We obtain sparse sub-models with an average of 13.38% weights and 14.97% FLOPs, while the accuracies are as good as their dense counterparts. More-sparse sub-models with 5.38% weights and 4.47% of FLOPs, which are subsets of the less-sparse ones, can be obtained with only 3.25% relative accuracy loss.
Load-balanced Gather-scatter Patterns for Sparse Deep Neural Networks
Dec 20, 2021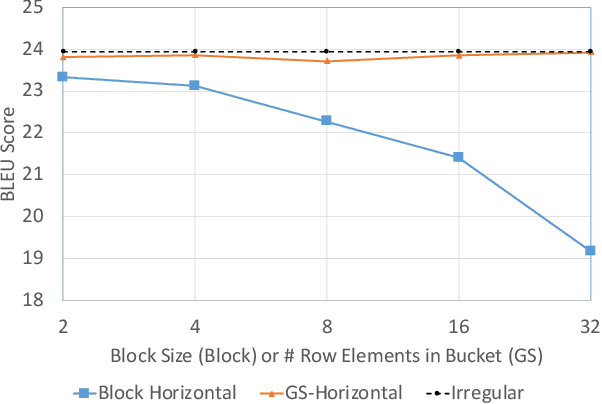
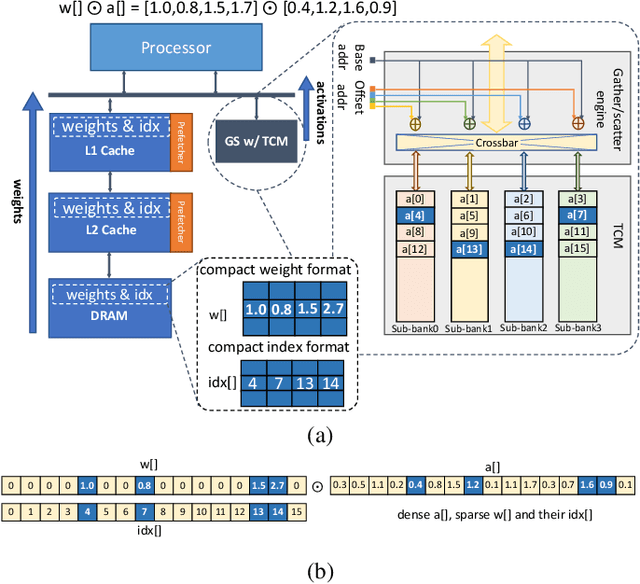

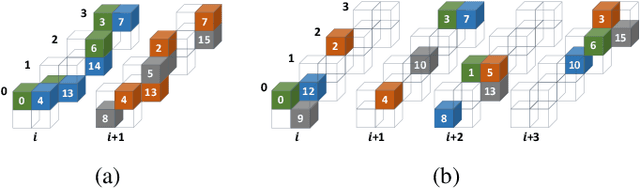
Deep neural networks (DNNs) have been proven to be effective in solving many real-life problems, but its high computation cost prohibits those models from being deployed to edge devices. Pruning, as a method to introduce zeros to model weights, has shown to be an effective method to provide good trade-offs between model accuracy and computation efficiency, and is a widely-used method to generate compressed models. However, the granularity of pruning makes important trade-offs. At the same sparsity level, a coarse-grained structured sparse pattern is more efficient on conventional hardware but results in worse accuracy, while a fine-grained unstructured sparse pattern can achieve better accuracy but is inefficient on existing hardware. On the other hand, some modern processors are equipped with fast on-chip scratchpad memories and gather/scatter engines that perform indirect load and store operations on such memories. In this work, we propose a set of novel sparse patterns, named gather-scatter (GS) patterns, to utilize the scratchpad memories and gather/scatter engines to speed up neural network inferences. Correspondingly, we present a compact sparse format. The proposed set of sparse patterns, along with a novel pruning methodology, address the load imbalance issue and result in models with quality close to unstructured sparse models and computation efficiency close to structured sparse models. Our experiments show that GS patterns consistently make better trade-offs between accuracy and computation efficiency compared to conventional structured sparse patterns. GS patterns can reduce the runtime of the DNN components by two to three times at the same accuracy levels. This is confirmed on three different deep learning tasks and popular models, namely, GNMT for machine translation, ResNet50 for image recognition, and Japser for acoustic speech recognition.
Factual Consistency Evaluation for Text Summarization via Counterfactual Estimation
Sep 08, 2021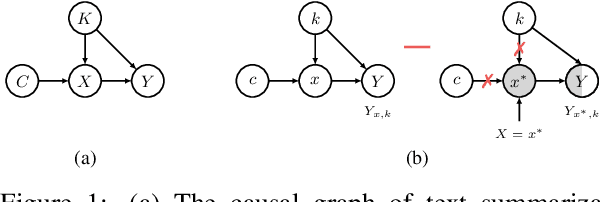

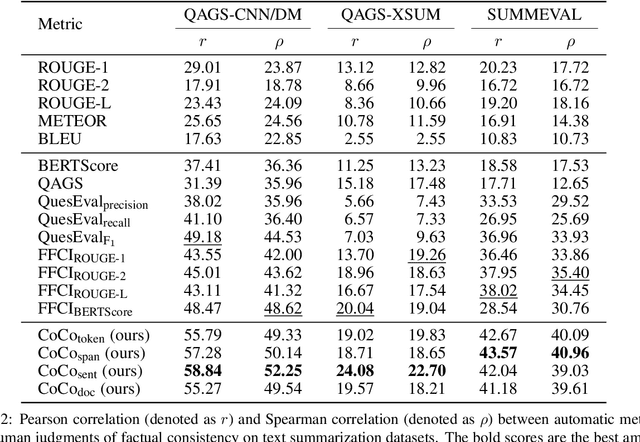
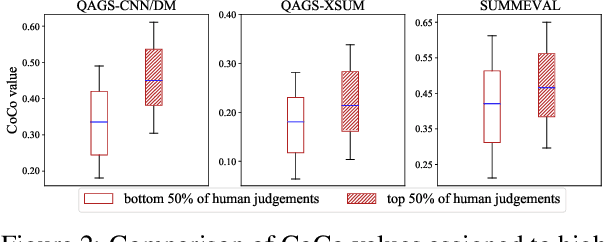
Despite significant progress has been achieved in text summarization, factual inconsistency in generated summaries still severely limits its practical applications. Among the key factors to ensure factual consistency, a reliable automatic evaluation metric is the first and the most crucial one. However, existing metrics either neglect the intrinsic cause of the factual inconsistency or rely on auxiliary tasks, leading to an unsatisfied correlation with human judgments or increasing the inconvenience of usage in practice. In light of these challenges, we propose a novel metric to evaluate the factual consistency in text summarization via counterfactual estimation, which formulates the causal relationship among the source document, the generated summary, and the language prior. We remove the effect of language prior, which can cause factual inconsistency, from the total causal effect on the generated summary, and provides a simple yet effective way to evaluate consistency without relying on other auxiliary tasks. We conduct a series of experiments on three public abstractive text summarization datasets, and demonstrate the advantages of the proposed metric in both improving the correlation with human judgments and the convenience of usage. The source code is available at https://github.com/xieyxclack/factual_coco.
Counterfactual Evaluation for Explainable AI
Sep 05, 2021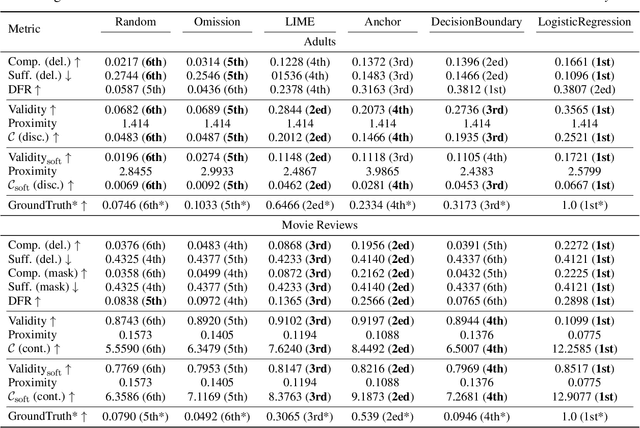
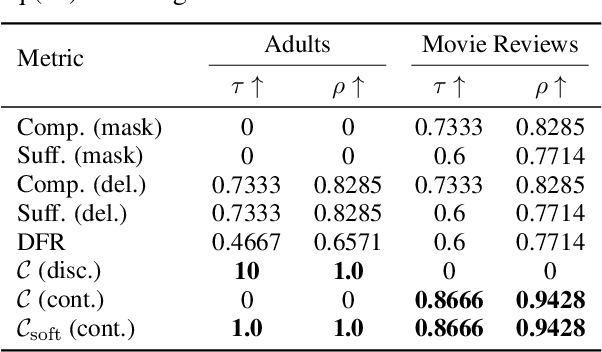
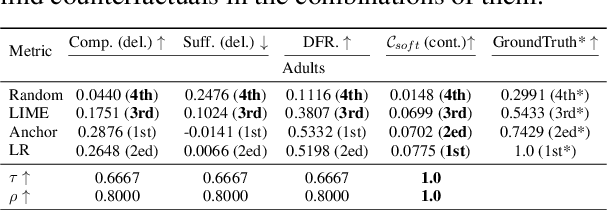
While recent years have witnessed the emergence of various explainable methods in machine learning, to what degree the explanations really represent the reasoning process behind the model prediction -- namely, the faithfulness of explanation -- is still an open problem. One commonly used way to measure faithfulness is \textit{erasure-based} criteria. Though conceptually simple, erasure-based criterion could inevitably introduce biases and artifacts. We propose a new methodology to evaluate the faithfulness of explanations from the \textit{counterfactual reasoning} perspective: the model should produce substantially different outputs for the original input and its corresponding counterfactual edited on a faithful feature. Specially, we introduce two algorithms to find the proper counterfactuals in both discrete and continuous scenarios and then use the acquired counterfactuals to measure faithfulness. Empirical results on several datasets show that compared with existing metrics, our proposed counterfactual evaluation method can achieve top correlation with the ground truth under diffe
Effective Model Sparsification by Scheduled Grow-and-Prune Methods
Jun 18, 2021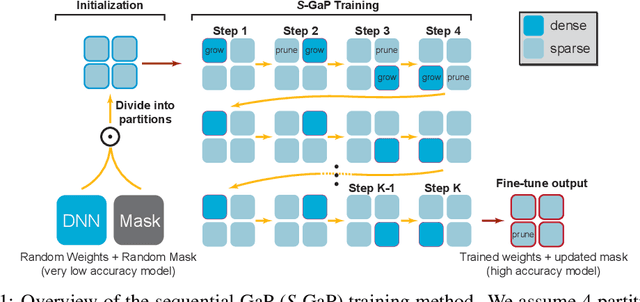

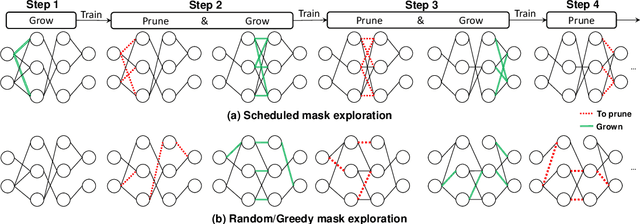
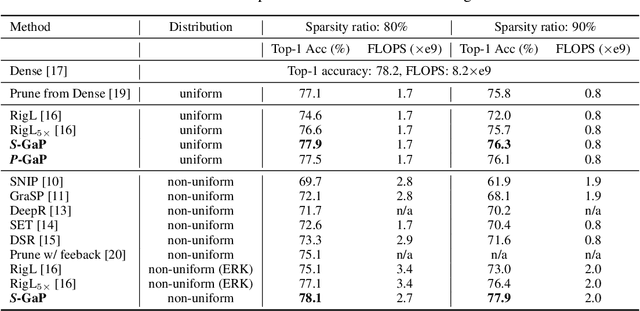
Deep neural networks (DNNs) are effective in solving many real-world problems. Larger DNN models usually exhibit better quality (e.g., accuracy) but their excessive computation results in long training and inference time. Model sparsification can reduce the computation and memory cost while maintaining model quality. Most existing sparsification algorithms unidirectionally remove weights, while others randomly or greedily explore a small subset of weights in each layer. The inefficiency of the algorithms reduces the achievable sparsity level. In addition, many algorithms still require pre-trained dense models and thus suffer from large memory footprint and long training time. In this paper, we propose a novel scheduled grow-and-prune (GaP) methodology without pre-training the dense models. It addresses the shortcomings of the previous works by repeatedly growing a subset of layers to dense and then pruning back to sparse after some training. Experiments have shown that such models can match or beat the quality of highly optimized dense models at 80% sparsity on a variety of tasks, such as image classification, objective detection, 3D object part segmentation, and translation. They also outperform other state-of-the-art (SOTA) pruning methods, including pruning from pre-trained dense models. As an example, a 90% sparse ResNet-50 obtained via GaP achieves 77.9% top-1 accuracy on ImageNet, improving the SOTA results by 1.5%.