 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVehicle-Infrastructure Cooperative 3D Object Detection via Feature Flow Prediction
Mar 19, 2023



Cooperatively utilizing both ego-vehicle and infrastructure sensor data can significantly enhance autonomous driving perception abilities. However, temporal asynchrony and limited wireless communication in traffic environments can lead to fusion misalignment and impact detection performance. This paper proposes Feature Flow Net (FFNet), a novel cooperative detection framework that uses a feature flow prediction module to address these issues in vehicle-infrastructure cooperative 3D object detection. Rather than transmitting feature maps extracted from still-images, FFNet transmits feature flow, which leverages the temporal coherence of sequential infrastructure frames to predict future features and compensate for asynchrony. Additionally, we introduce a self-supervised approach to enable FFNet to generate feature flow with feature prediction ability. Experimental results demonstrate that our proposed method outperforms existing cooperative detection methods while requiring no more than 1/10 transmission cost of raw data on the DAIR-V2X dataset when temporal asynchrony exceeds 200$ms$. The code is available at \href{https://github.com/haibao-yu/FFNet-VIC3D}{https://github.com/haibao-yu/FFNet-VIC3D}.
Fast-BEV: A Fast and Strong Bird's-Eye View Perception Baseline
Jan 29, 2023



Recently, perception task based on Bird's-Eye View (BEV) representation has drawn more and more attention, and BEV representation is promising as the foundation for next-generation Autonomous Vehicle (AV) perception. However, most existing BEV solutions either require considerable resources to execute on-vehicle inference or suffer from modest performance. This paper proposes a simple yet effective framework, termed Fast-BEV , which is capable of performing faster BEV perception on the on-vehicle chips. Towards this goal, we first empirically find that the BEV representation can be sufficiently powerful without expensive transformer based transformation nor depth representation. Our Fast-BEV consists of five parts, We novelly propose (1) a lightweight deployment-friendly view transformation which fast transfers 2D image feature to 3D voxel space, (2) an multi-scale image encoder which leverages multi-scale information for better performance, (3) an efficient BEV encoder which is particularly designed to speed up on-vehicle inference. We further introduce (4) a strong data augmentation strategy for both image and BEV space to avoid over-fitting, (5) a multi-frame feature fusion mechanism to leverage the temporal information. Through experiments, on 2080Ti platform, our R50 model can run 52.6 FPS with 47.3% NDS on the nuScenes validation set, exceeding the 41.3 FPS and 47.5% NDS of the BEVDepth-R50 model and 30.2 FPS and 45.7% NDS of the BEVDet4D-R50 model. Our largest model (R101@900x1600) establishes a competitive 53.5% NDS on the nuScenes validation set. We further develop a benchmark with considerable accuracy and efficiency on current popular on-vehicle chips. The code is released at: https://github.com/Sense-GVT/Fast-BEV.
Fast-BEV: Towards Real-time On-vehicle Bird's-Eye View Perception
Jan 19, 2023



Recently, the pure camera-based Bird's-Eye-View (BEV) perception removes expensive Lidar sensors, making it a feasible solution for economical autonomous driving. However, most existing BEV solutions either suffer from modest performance or require considerable resources to execute on-vehicle inference. This paper proposes a simple yet effective framework, termed Fast-BEV, which is capable of performing real-time BEV perception on the on-vehicle chips. Towards this goal, we first empirically find that the BEV representation can be sufficiently powerful without expensive view transformation or depth representation. Starting from M2BEV baseline, we further introduce (1) a strong data augmentation strategy for both image and BEV space to avoid over-fitting (2) a multi-frame feature fusion mechanism to leverage the temporal information (3) an optimized deployment-friendly view transformation to speed up the inference. Through experiments, we show Fast-BEV model family achieves considerable accuracy and efficiency on edge. In particular, our M1 model (R18@256x704) can run over 50FPS on the Tesla T4 platform, with 47.0% NDS on the nuScenes validation set. Our largest model (R101@900x1600) establishes a new state-of-the-art 53.5% NDS on the nuScenes validation set. The code is released at: https://github.com/Sense-GVT/Fast-BEV.
* Accepted by NeurIPS2022_ML4AD on October 22, 2022
Delving into the Devils of Bird's-eye-view Perception: A Review, Evaluation and Recipe
Sep 12, 2022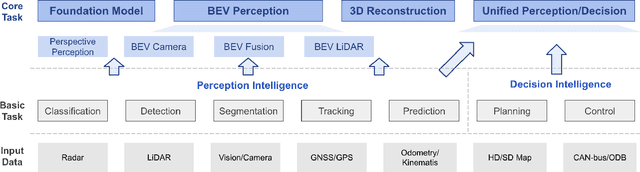
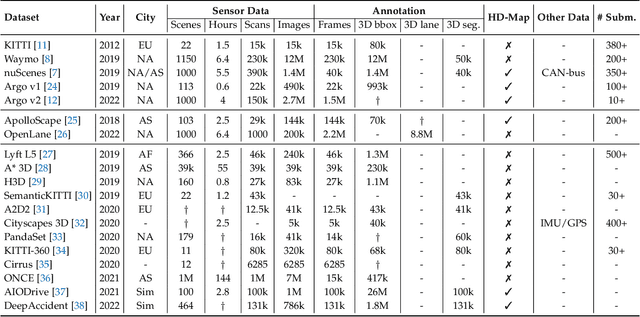
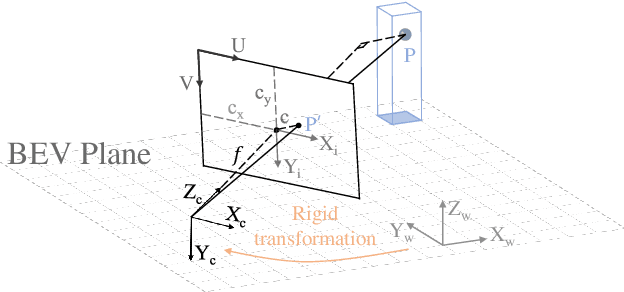
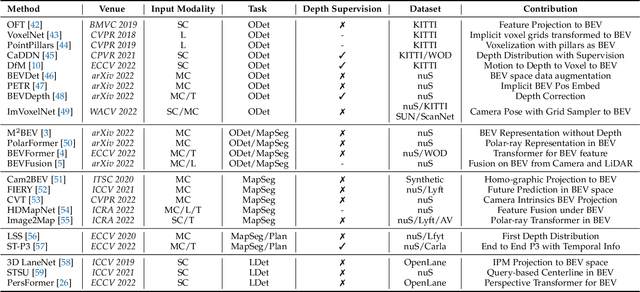
Learning powerful representations in bird's-eye-view (BEV) for perception tasks is trending and drawing extensive attention both from industry and academia. Conventional approaches for most autonomous driving algorithms perform detection, segmentation, tracking, etc., in a front or perspective view. As sensor configurations get more complex, integrating multi-source information from different sensors and representing features in a unified view come of vital importance. BEV perception inherits several advantages, as representing surrounding scenes in BEV is intuitive and fusion-friendly; and representing objects in BEV is most desirable for subsequent modules as in planning and/or control. The core problems for BEV perception lie in (a) how to reconstruct the lost 3D information via view transformation from perspective view to BEV; (b) how to acquire ground truth annotations in BEV grid; (c) how to formulate the pipeline to incorporate features from different sources and views; and (d) how to adapt and generalize algorithms as sensor configurations vary across different scenarios. In this survey, we review the most recent work on BEV perception and provide an in-depth analysis of different solutions. Moreover, several systematic designs of BEV approach from the industry are depicted as well. Furthermore, we introduce a full suite of practical guidebook to improve the performance of BEV perception tasks, including camera, LiDAR and fusion inputs. At last, we point out the future research directions in this area. We hope this report would shed some light on the community and encourage more research effort on BEV perception. We keep an active repository to collect the most recent work and provide a toolbox for bag of tricks at https://github.com/OpenPerceptionX/BEVPerception-Survey-Recipe.
UNITS: Unsupervised Intermediate Training Stage for Scene Text Detection
May 10, 2022
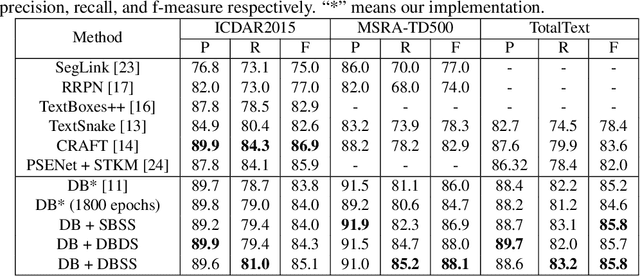
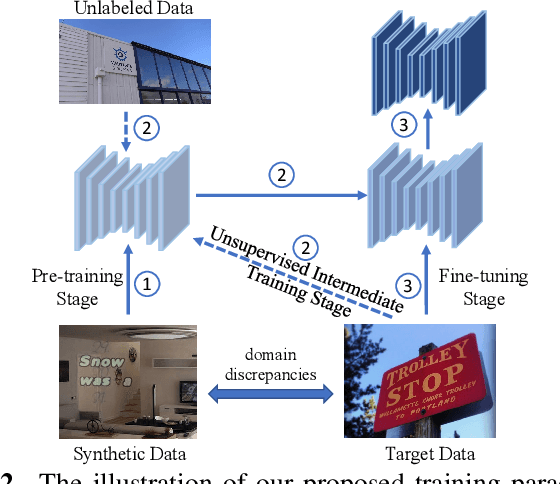
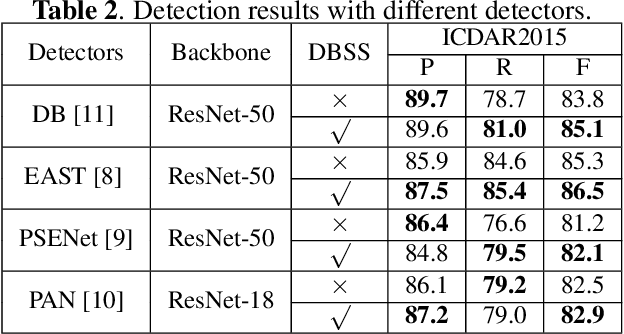
Recent scene text detection methods are almost based on deep learning and data-driven. Synthetic data is commonly adopted for pre-training due to expensive annotation cost. However, there are obvious domain discrepancies between synthetic data and real-world data. It may lead to sub-optimal performance to directly adopt the model initialized by synthetic data in the fine-tuning stage. In this paper, we propose a new training paradigm for scene text detection, which introduces an \textbf{UN}supervised \textbf{I}ntermediate \textbf{T}raining \textbf{S}tage (UNITS) that builds a buffer path to real-world data and can alleviate the gap between the pre-training stage and fine-tuning stage. Three training strategies are further explored to perceive information from real-world data in an unsupervised way. With UNITS, scene text detectors are improved without introducing any parameters and computations during inference. Extensive experimental results show consistent performance improvements on three public datasets.
Understanding The Robustness in Vision Transformers
Apr 27, 2022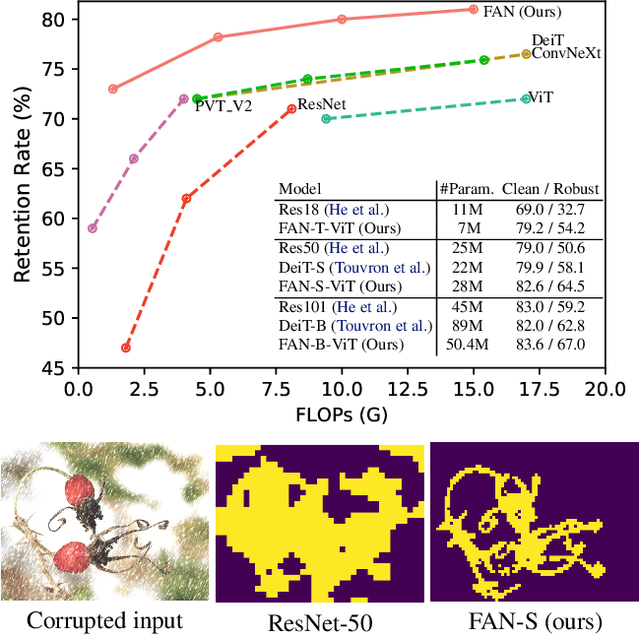

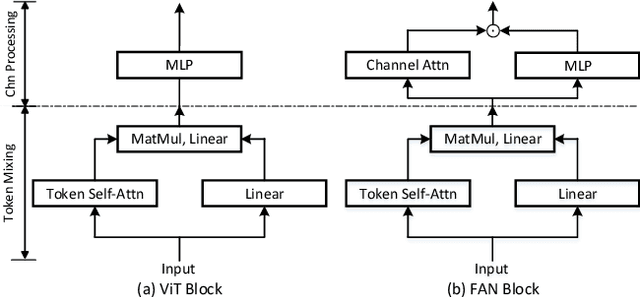
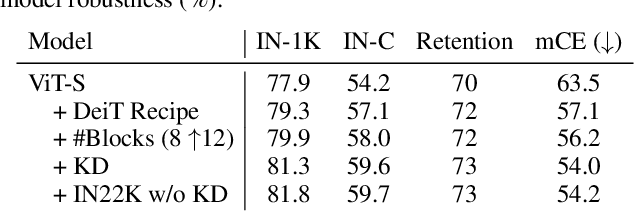
Recent studies show that Vision Transformers(ViTs) exhibit strong robustness against various corruptions. Although this property is partly attributed to the self-attention mechanism, there is still a lack of systematic understanding. In this paper, we examine the role of self-attention in learning robust representations. Our study is motivated by the intriguing properties of the emerging visual grouping in Vision Transformers, which indicates that self-attention may promote robustness through improved mid-level representations. We further propose a family of fully attentional networks (FANs) that strengthen this capability by incorporating an attentional channel processing design. We validate the design comprehensively on various hierarchical backbones. Our model achieves a state of-the-art 87.1% accuracy and 35.8% mCE on ImageNet-1k and ImageNet-C with 76.8M parameters. We also demonstrate state-of-the-art accuracy and robustness in two downstream tasks: semantic segmentation and object detection. Code will be available at https://github.com/NVlabs/FAN.
M$^2$BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Birds-Eye View Representation
Apr 19, 2022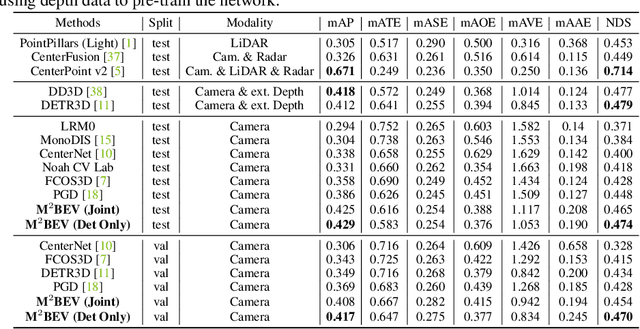
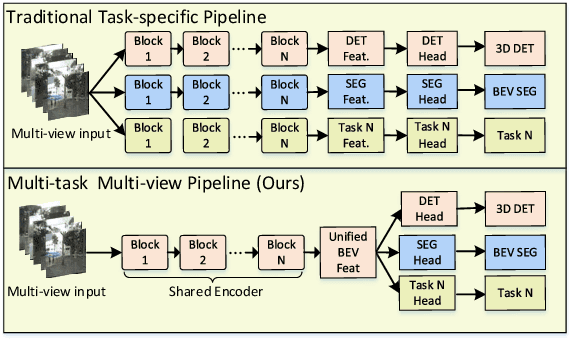
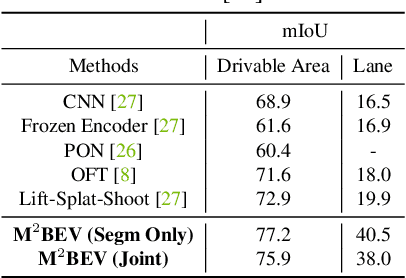
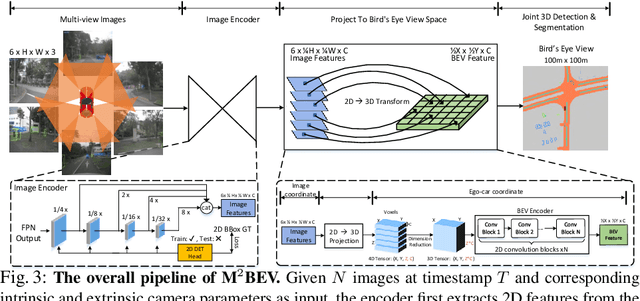
In this paper, we propose M$^2$BEV, a unified framework that jointly performs 3D object detection and map segmentation in the Birds Eye View~(BEV) space with multi-camera image inputs. Unlike the majority of previous works which separately process detection and segmentation, M$^2$BEV infers both tasks with a unified model and improves efficiency. M$^2$BEV efficiently transforms multi-view 2D image features into the 3D BEV feature in ego-car coordinates. Such BEV representation is important as it enables different tasks to share a single encoder. Our framework further contains four important designs that benefit both accuracy and efficiency: (1) An efficient BEV encoder design that reduces the spatial dimension of a voxel feature map. (2) A dynamic box assignment strategy that uses learning-to-match to assign ground-truth 3D boxes with anchors. (3) A BEV centerness re-weighting that reinforces with larger weights for more distant predictions, and (4) Large-scale 2D detection pre-training and auxiliary supervision. We show that these designs significantly benefit the ill-posed camera-based 3D perception tasks where depth information is missing. M$^2$BEV is memory efficient, allowing significantly higher resolution images as input, with faster inference speed. Experiments on nuScenes show that M$^2$BEV achieves state-of-the-art results in both 3D object detection and BEV segmentation, with the best single model achieving 42.5 mAP and 57.0 mIoU in these two tasks, respectively.
Improving Monocular Visual Odometry Using Learned Depth
Apr 04, 2022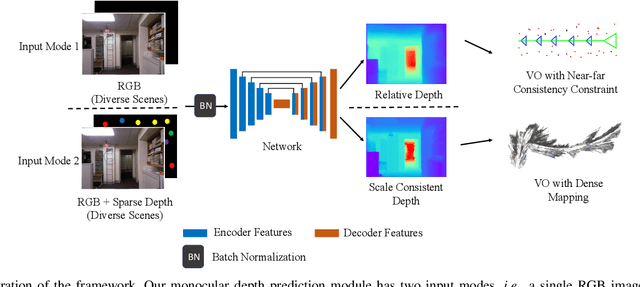
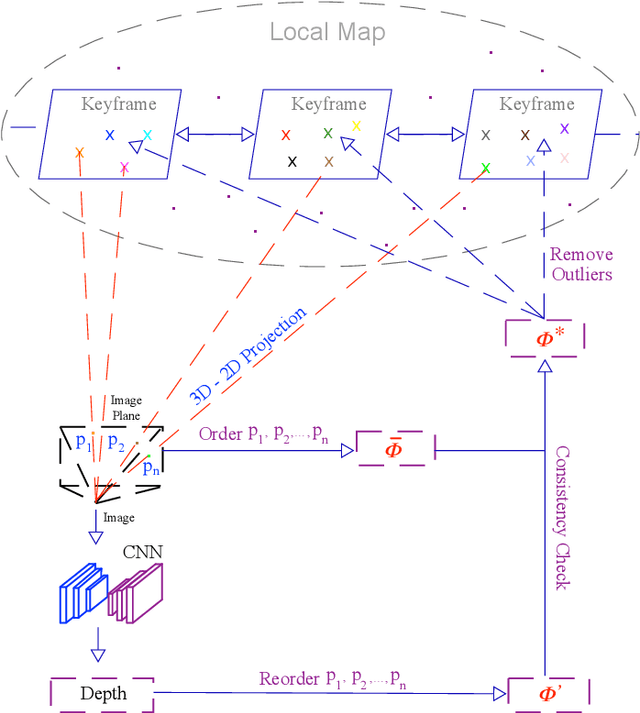
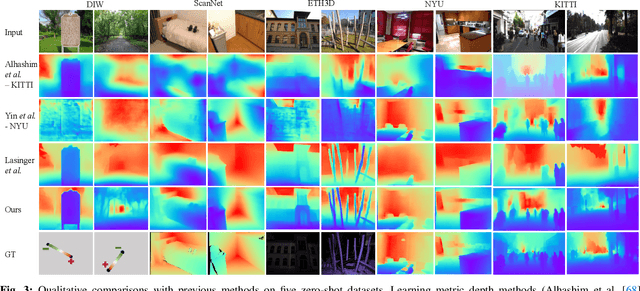
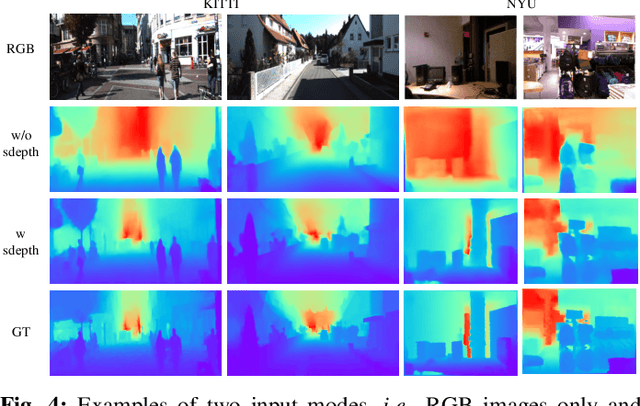
Monocular visual odometry (VO) is an important task in robotics and computer vision. Thus far, how to build accurate and robust monocular VO systems that can work well in diverse scenarios remains largely unsolved. In this paper, we propose a framework to exploit monocular depth estimation for improving VO. The core of our framework is a monocular depth estimation module with a strong generalization capability for diverse scenes. It consists of two separate working modes to assist the localization and mapping. With a single monocular image input, the depth estimation module predicts a relative depth to help the localization module on improving the accuracy. With a sparse depth map and an RGB image input, the depth estimation module can generate accurate scale-consistent depth for dense mapping. Compared with current learning-based VO methods, our method demonstrates a stronger generalization ability to diverse scenes. More significantly, our framework is able to boost the performances of existing geometry-based VO methods by a large margin.
BEVFormer: Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
Mar 31, 2022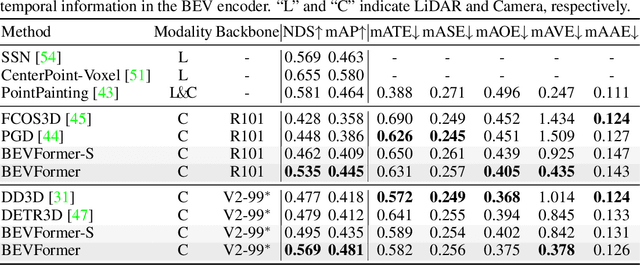
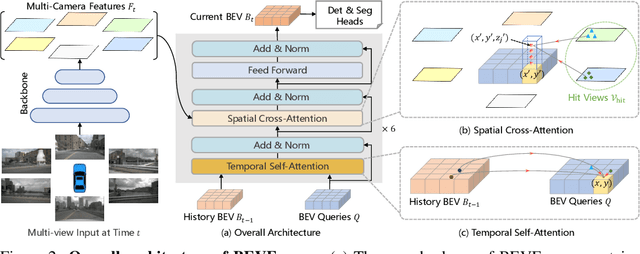
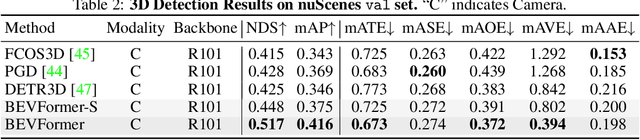
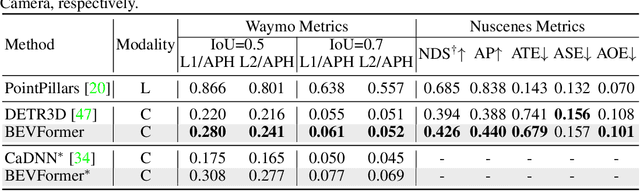
3D visual perception tasks, including 3D detection and map segmentation based on multi-camera images, are essential for autonomous driving systems. In this work, we present a new framework termed BEVFormer, which learns unified BEV representations with spatiotemporal transformers to support multiple autonomous driving perception tasks. In a nutshell, BEVFormer exploits both spatial and temporal information by interacting with spatial and temporal space through predefined grid-shaped BEV queries. To aggregate spatial information, we design a spatial cross-attention that each BEV query extracts the spatial features from the regions of interest across camera views. For temporal information, we propose a temporal self-attention to recurrently fuse the history BEV information. Our approach achieves the new state-of-the-art 56.9\% in terms of NDS metric on the nuScenes test set, which is 9.0 points higher than previous best arts and on par with the performance of LiDAR-based baselines. We further show that BEVFormer remarkably improves the accuracy of velocity estimation and recall of objects under low visibility conditions. The code will be released at https://github.com/zhiqi-li/BEVFormer.
WegFormer: Transformers for Weakly Supervised Semantic Segmentation
Mar 16, 2022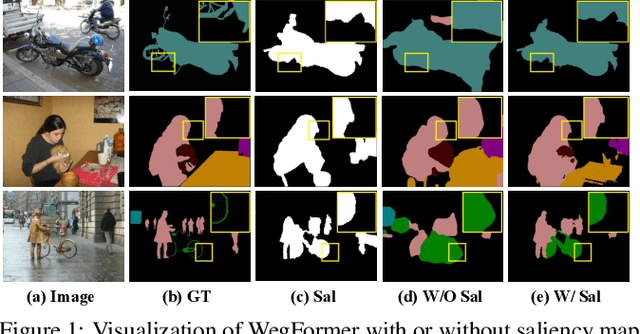
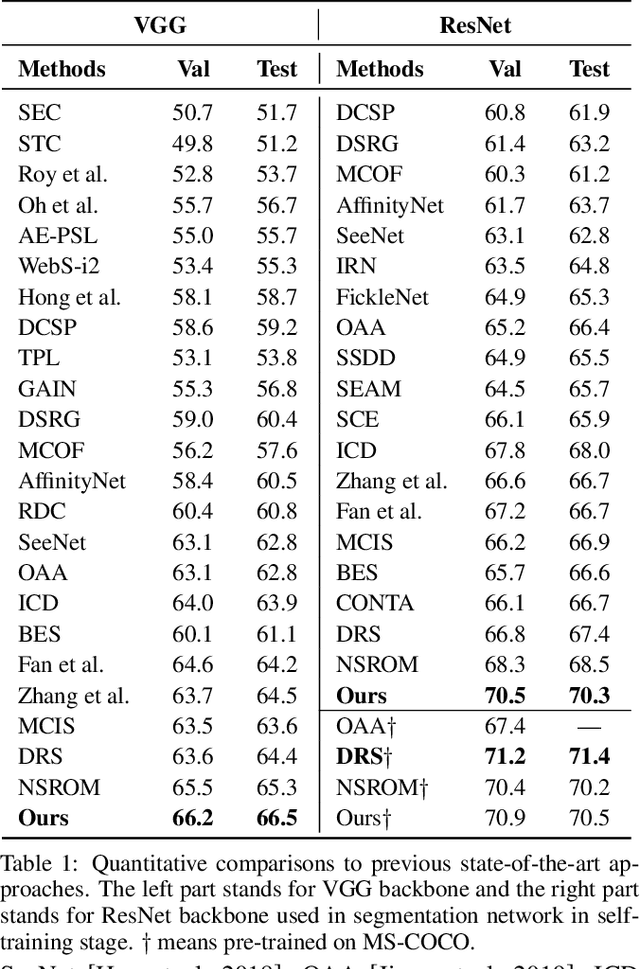
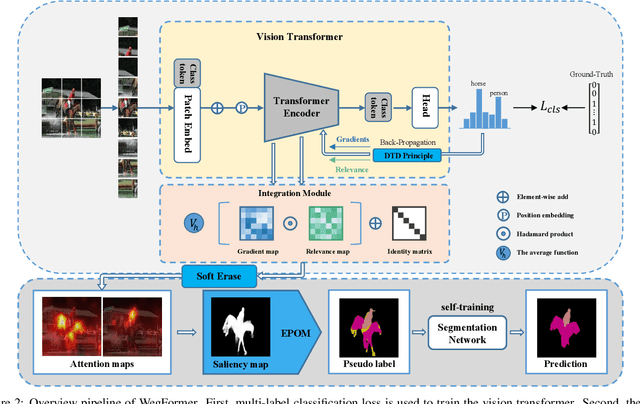

Although convolutional neural networks (CNNs) have achieved remarkable progress in weakly supervised semantic segmentation (WSSS), the effective receptive field of CNN is insufficient to capture global context information, leading to sub-optimal results. Inspired by the great success of Transformers in fundamental vision areas, this work for the first time introduces Transformer to build a simple and effective WSSS framework, termed WegFormer. Unlike existing CNN-based methods, WegFormer uses Vision Transformer (ViT) as a classifier to produce high-quality pseudo segmentation masks. To this end, we introduce three tailored components in our Transformer-based framework, which are (1) a Deep Taylor Decomposition (DTD) to generate attention maps, (2) a soft erasing module to smooth the attention maps, and (3) an efficient potential object mining (EPOM) to filter noisy activation in the background. Without any bells and whistles, WegFormer achieves state-of-the-art 70.5% mIoU on the PASCAL VOC dataset, significantly outperforming the previous best method. We hope WegFormer provides a new perspective to tap the potential of Transformer in weakly supervised semantic segmentation. Code will be released.