 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEARL: Training Socratic Tutors with Pedagogically Aligned Reinforcement Learning
May 28, 2026Large Language Models (LLMs) have shown promise as educational tutors, yet effective tutoring requires more than solving problems: it must provide progressive Socratic guidance and balance multiple pedagogical objectives across multi-turn interactions. However, training such tutors remains challenging due to limited-fidelity and weakly controllable student simulation, under-specified pedagogical reward modeling, and unstable multi-objective optimization. To overcome these limitations, we propose PEARL, a pedagogically aligned reinforcement learning framework for training Socratic tutoring agents, consisting of three key components. First, we introduce a controllable student simulator that decouples latent cognitive states from response generation to model diverse abilities and misconceptions. Second, we develop a generative reward model that jointly evaluates pedagogical quality and objective correctness for policy optimization. Finally, we propose a stable multi-objective RL scheme that discretizes rewards within each dimension and aggregates normalized advantages across dimensions, preventing high-variance objectives from dominating updates. Experiments on multiple benchmarks show that PEARL achieves the best performance among open-source models and remains competitive with leading proprietary LLMs, despite using only a 30B policy model.
UNITS: Unsupervised Intermediate Training Stage for Scene Text Detection
May 10, 2022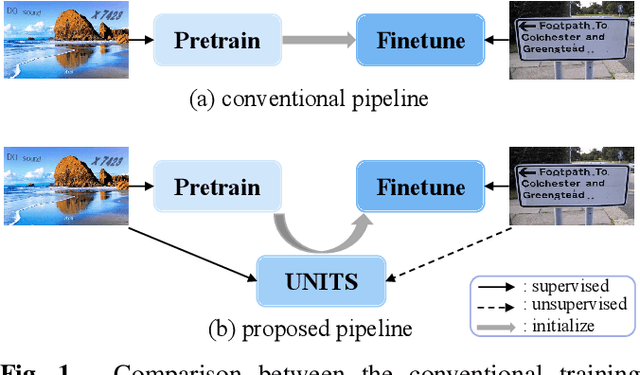
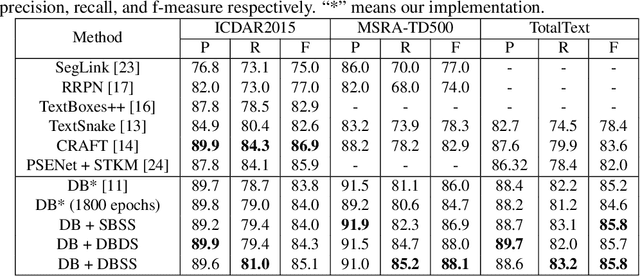
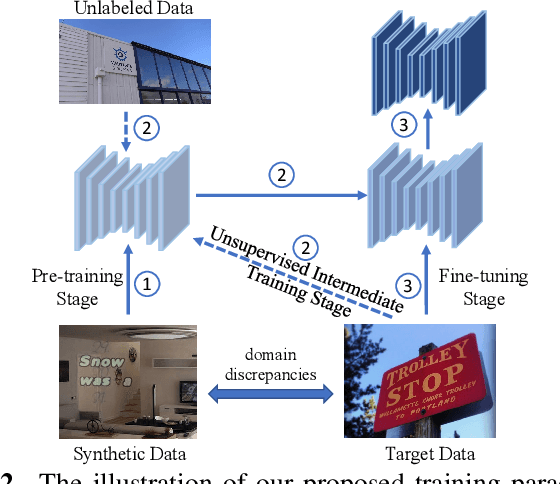
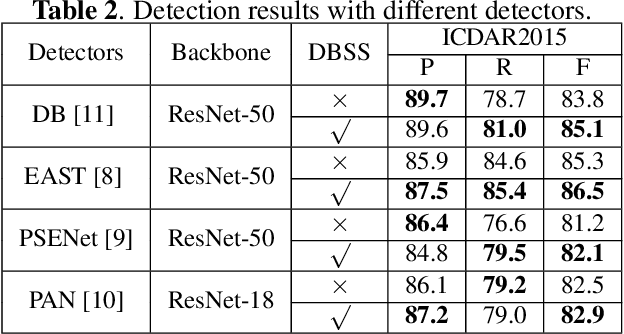
Recent scene text detection methods are almost based on deep learning and data-driven. Synthetic data is commonly adopted for pre-training due to expensive annotation cost. However, there are obvious domain discrepancies between synthetic data and real-world data. It may lead to sub-optimal performance to directly adopt the model initialized by synthetic data in the fine-tuning stage. In this paper, we propose a new training paradigm for scene text detection, which introduces an \textbf{UN}supervised \textbf{I}ntermediate \textbf{T}raining \textbf{S}tage (UNITS) that builds a buffer path to real-world data and can alleviate the gap between the pre-training stage and fine-tuning stage. Three training strategies are further explored to perceive information from real-world data in an unsupervised way. With UNITS, scene text detectors are improved without introducing any parameters and computations during inference. Extensive experimental results show consistent performance improvements on three public datasets.
Which and Where to Focus: A Simple yet Accurate Framework for Arbitrary-Shaped Nearby Text Detection in Scene Images
Sep 08, 2021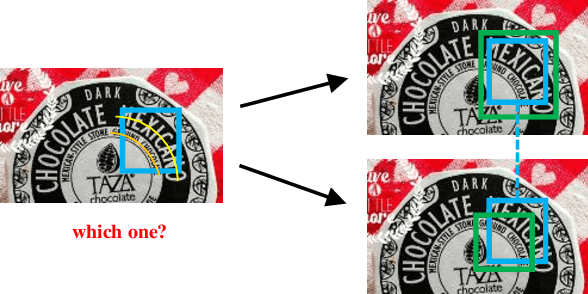
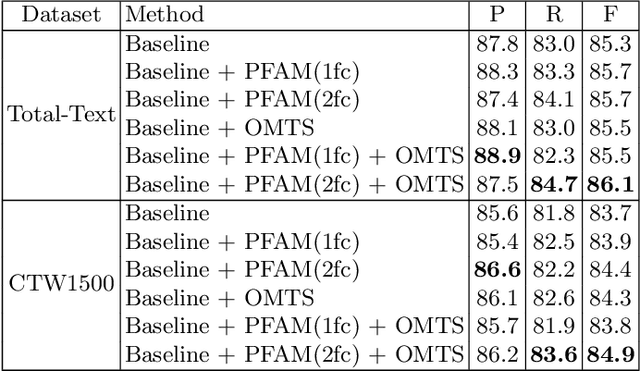
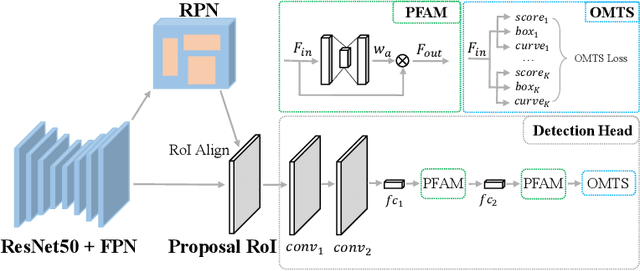
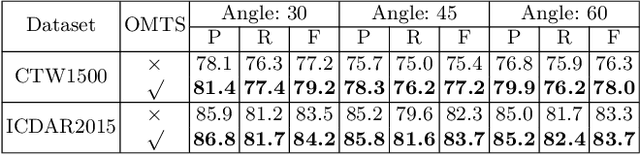
Scene text detection has drawn the close attention of researchers. Though many methods have been proposed for horizontal and oriented texts, previous methods may not perform well when dealing with arbitrary-shaped texts such as curved texts. In particular, confusion problem arises in the case of nearby text instances. In this paper, we propose a simple yet effective method for accurate arbitrary-shaped nearby scene text detection. Firstly, a One-to-Many Training Scheme (OMTS) is designed to eliminate confusion and enable the proposals to learn more appropriate groundtruths in the case of nearby text instances. Secondly, we propose a Proposal Feature Attention Module (PFAM) to exploit more effective features for each proposal, which can better adapt to arbitrary-shaped text instances. Finally, we propose a baseline that is based on Faster R-CNN and outputs the curve representation directly. Equipped with PFAM and OMTS, the detector can achieve state-of-the-art or competitive performance on several challenging benchmarks.
Mask is All You Need: Rethinking Mask R-CNN for Dense and Arbitrary-Shaped Scene Text Detection
Sep 08, 2021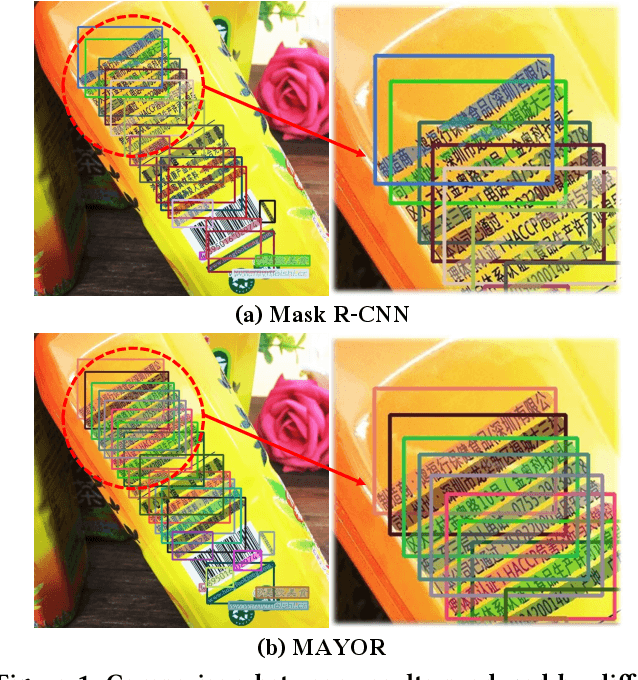
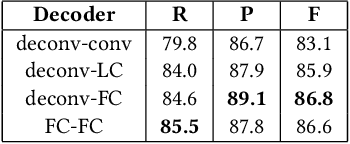
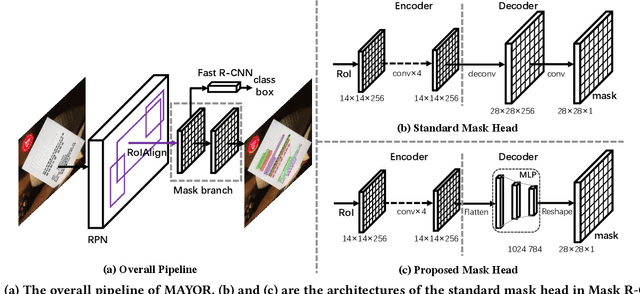
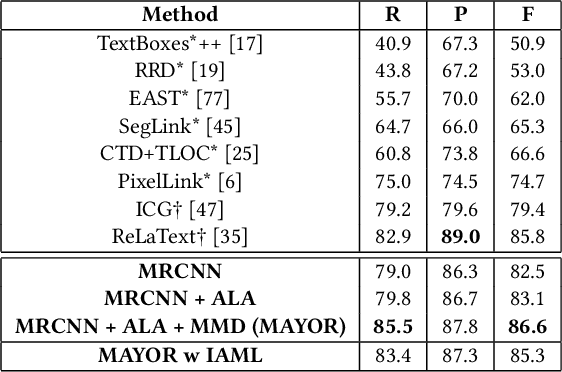
Due to the large success in object detection and instance segmentation, Mask R-CNN attracts great attention and is widely adopted as a strong baseline for arbitrary-shaped scene text detection and spotting. However, two issues remain to be settled. The first is dense text case, which is easy to be neglected but quite practical. There may exist multiple instances in one proposal, which makes it difficult for the mask head to distinguish different instances and degrades the performance. In this work, we argue that the performance degradation results from the learning confusion issue in the mask head. We propose to use an MLP decoder instead of the "deconv-conv" decoder in the mask head, which alleviates the issue and promotes robustness significantly. And we propose instance-aware mask learning in which the mask head learns to predict the shape of the whole instance rather than classify each pixel to text or non-text. With instance-aware mask learning, the mask branch can learn separated and compact masks. The second is that due to large variations in scale and aspect ratio, RPN needs complicated anchor settings, making it hard to maintain and transfer across different datasets. To settle this issue, we propose an adaptive label assignment in which all instances especially those with extreme aspect ratios are guaranteed to be associated with enough anchors. Equipped with these components, the proposed method named MAYOR achieves state-of-the-art performance on five benchmarks including DAST1500, MSRA-TD500, ICDAR2015, CTW1500, and Total-Text.