 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Gap between Language Models and Cross-Lingual Sequence Labeling
Apr 11, 2022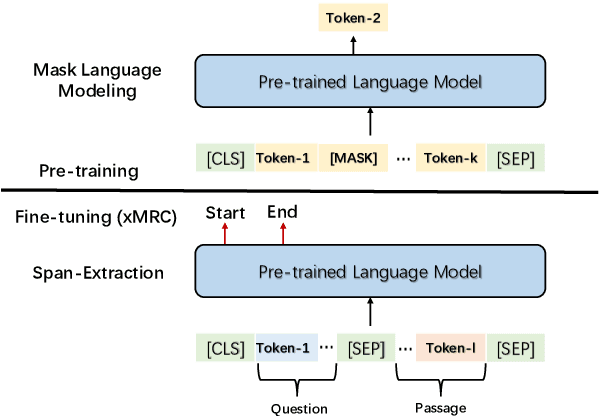


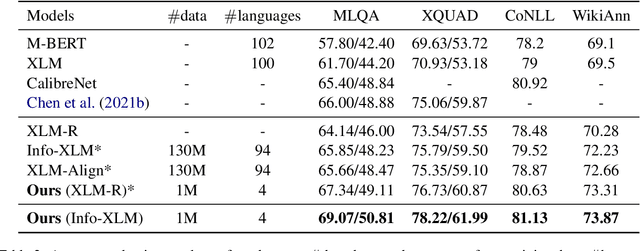
Large-scale cross-lingual pre-trained language models (xPLMs) have shown effectiveness in cross-lingual sequence labeling tasks (xSL), such as cross-lingual machine reading comprehension (xMRC) by transferring knowledge from a high-resource language to low-resource languages. Despite the great success, we draw an empirical observation that there is a training objective gap between pre-training and fine-tuning stages: e.g., mask language modeling objective requires local understanding of the masked token and the span-extraction objective requires global understanding and reasoning of the input passage/paragraph and question, leading to the discrepancy between pre-training and xMRC. In this paper, we first design a pre-training task tailored for xSL named Cross-lingual Language Informative Span Masking (CLISM) to eliminate the objective gap in a self-supervised manner. Second, we present ContrAstive-Consistency Regularization (CACR), which utilizes contrastive learning to encourage the consistency between representations of input parallel sequences via unsupervised cross-lingual instance-wise training signals during pre-training. By these means, our methods not only bridge the gap between pretrain-finetune, but also enhance PLMs to better capture the alignment between different languages. Extensive experiments prove that our method achieves clearly superior results on multiple xSL benchmarks with limited pre-training data. Our methods also surpass the previous state-of-the-art methods by a large margin in few-shot data settings, where only a few hundred training examples are available.
Transformer-Empowered Content-Aware Collaborative Filtering
Apr 02, 2022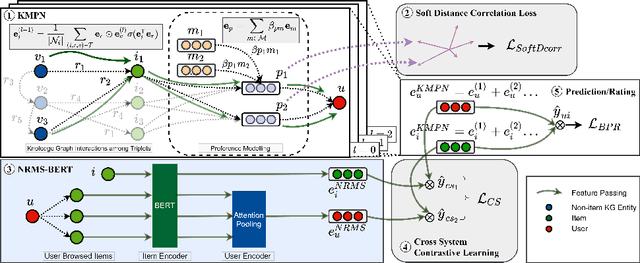
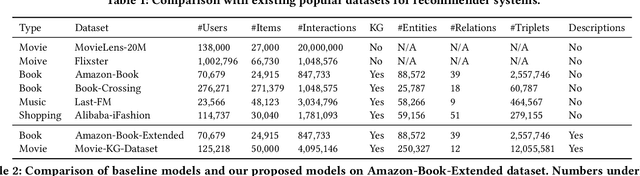
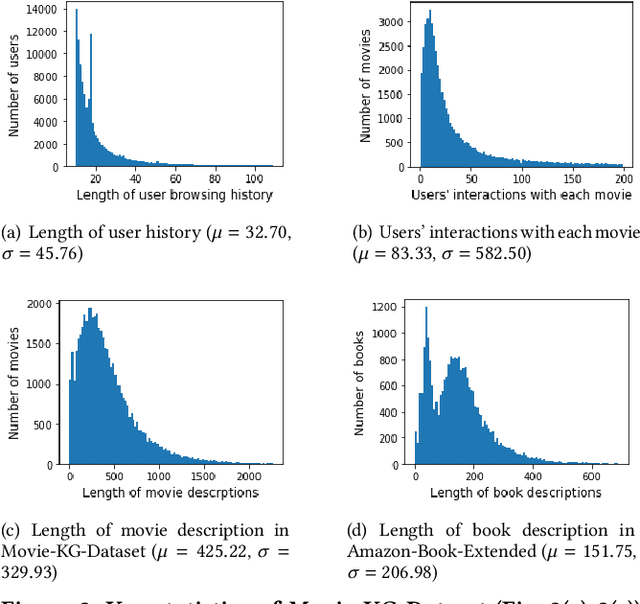
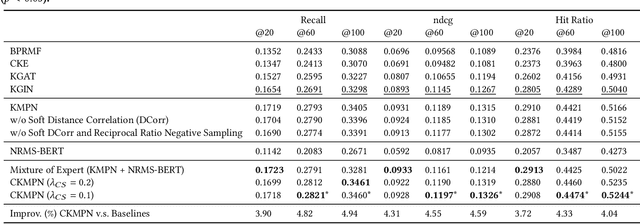
Knowledge graph (KG) based Collaborative Filtering is an effective approach to personalizing recommendation systems for relatively static domains such as movies and books, by leveraging structured information from KG to enrich both item and user representations. Motivated by the use of Transformers for understanding rich text in content-based filtering recommender systems, we propose Content-aware KG-enhanced Meta-preference Networks as a way to enhance collaborative filtering recommendation based on both structured information from KG as well as unstructured content features based on Transformer-empowered content-based filtering. To achieve this, we employ a novel training scheme, Cross-System Contrastive Learning, to address the inconsistency of the two very different systems and propose a powerful collaborative filtering model and a variant of the well-known NRMS system within this modeling framework. We also contribute to public domain resources through the creation of a large-scale movie-knowledge-graph dataset and an extension of the already public Amazon-Book dataset through incorporation of text descriptions crawled from external sources. We present experimental results showing that enhancing collaborative filtering with Transformer-based features derived from content-based filtering outperforms strong baseline systems, improving the ability of knowledge-graph-based collaborative filtering systems to exploit item content information.
FORCE: A Framework of Rule-Based Conversational Recommender System
Mar 18, 2022
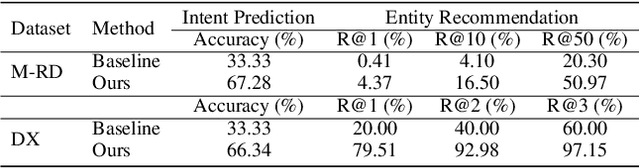
The conversational recommender systems (CRSs) have received extensive attention in recent years. However, most of the existing works focus on various deep learning models, which are largely limited by the requirement of large-scale human-annotated datasets. Such methods are not able to deal with the cold-start scenarios in industrial products. To alleviate the problem, we propose FORCE, a Framework Of Rule-based Conversational Recommender system that helps developers to quickly build CRS bots by simple configuration. We conduct experiments on two datasets in different languages and domains to verify its effectiveness and usability.
PromDA: Prompt-based Data Augmentation for Low-Resource NLU Tasks
Mar 17, 2022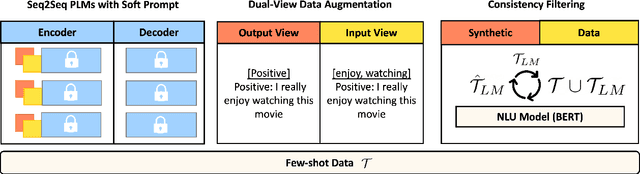
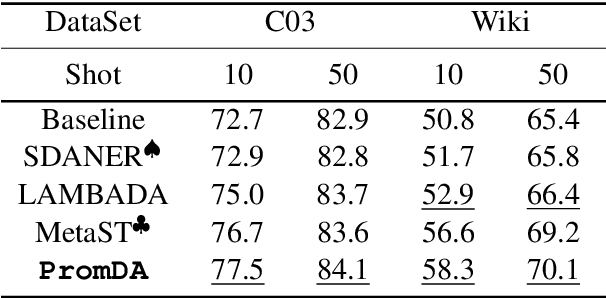
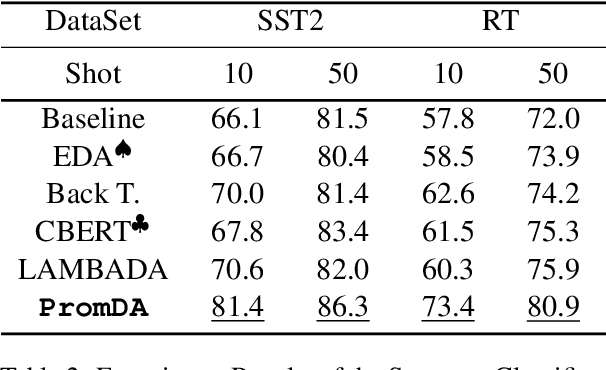

This paper focuses on the Data Augmentation for low-resource Natural Language Understanding (NLU) tasks. We propose Prompt-based D}ata Augmentation model (PromDA) which only trains small-scale Soft Prompt (i.e., a set of trainable vectors) in the frozen Pre-trained Language Models (PLMs). This avoids human effort in collecting unlabeled in-domain data and maintains the quality of generated synthetic data. In addition, PromDA generates synthetic data via two different views and filters out the low-quality data using NLU models. Experiments on four benchmarks show that synthetic data produced by PromDA successfully boost up the performance of NLU models which consistently outperform several competitive baseline models, including a state-of-the-art semi-supervised model using unlabeled in-domain data. The synthetic data from PromDA are also complementary with unlabeled in-domain data. The NLU models can be further improved when they are combined for training.
TegTok: Augmenting Text Generation via Task-specific and Open-world Knowledge
Mar 16, 2022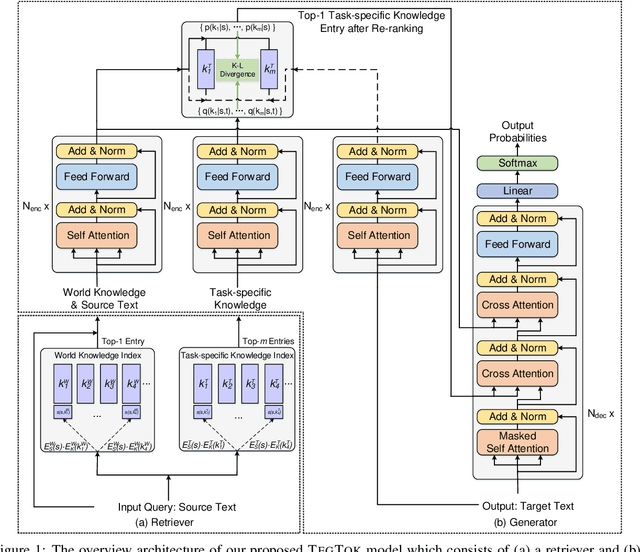
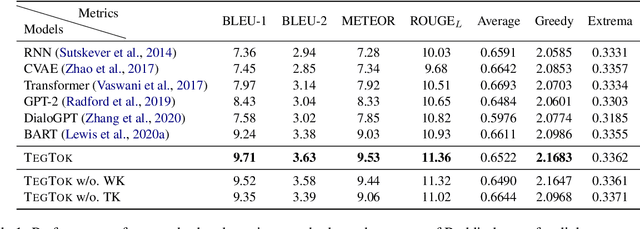
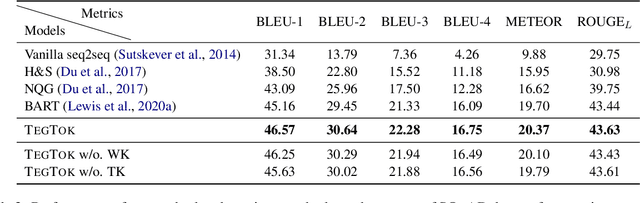
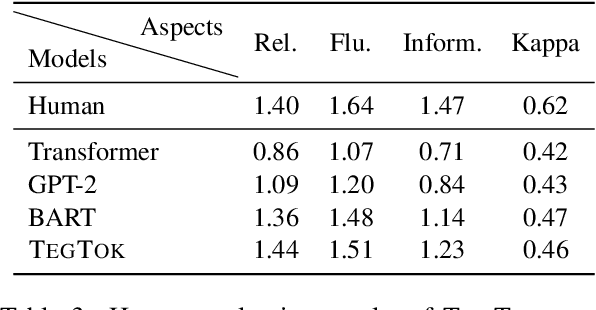
Generating natural and informative texts has been a long-standing problem in NLP. Much effort has been dedicated into incorporating pre-trained language models (PLMs) with various open-world knowledge, such as knowledge graphs or wiki pages. However, their ability to access and manipulate the task-specific knowledge is still limited on downstream tasks, as this type of knowledge is usually not well covered in PLMs and is hard to acquire. To address the problem, we propose augmenting TExt Generation via Task-specific and Open-world Knowledge (TegTok) in a unified framework. Our model selects knowledge entries from two types of knowledge sources through dense retrieval and then injects them into the input encoding and output decoding stages respectively on the basis of PLMs. With the help of these two types of knowledge, our model can learn what and how to generate. Experiments on two text generation tasks of dialogue generation and question generation, and on two datasets show that our method achieves better performance than various baseline models.
HeterMPC: A Heterogeneous Graph Neural Network for Response Generation in Multi-Party Conversations
Mar 16, 2022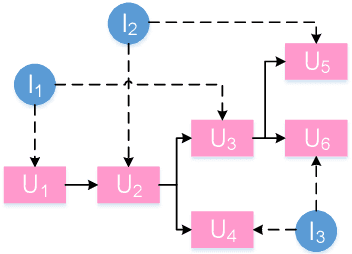
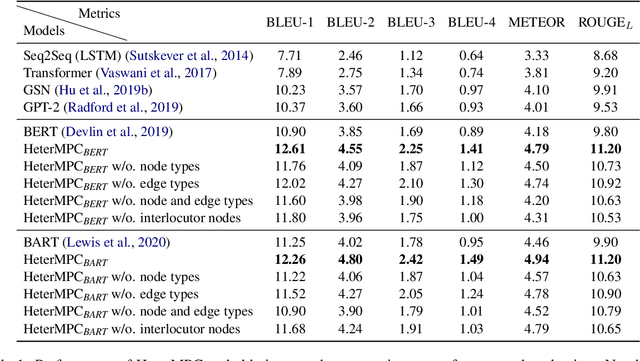
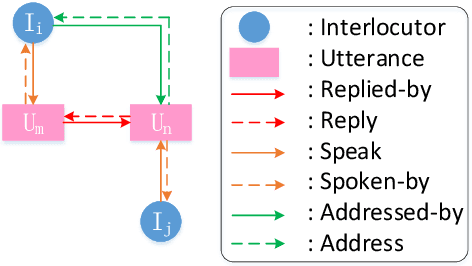
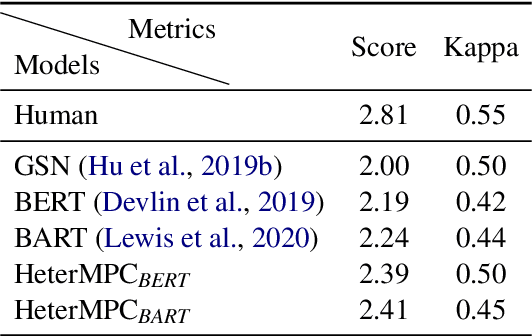
Recently, various response generation models for two-party conversations have achieved impressive improvements, but less effort has been paid to multi-party conversations (MPCs) which are more practical and complicated. Compared with a two-party conversation where a dialogue context is a sequence of utterances, building a response generation model for MPCs is more challenging, since there exist complicated context structures and the generated responses heavily rely on both interlocutors (i.e., speaker and addressee) and history utterances. To address these challenges, we present HeterMPC, a heterogeneous graph-based neural network for response generation in MPCs which models the semantics of utterances and interlocutors simultaneously with two types of nodes in a graph. Besides, we also design six types of meta relations with node-edge-type-dependent parameters to characterize the heterogeneous interactions within the graph. Through multi-hop updating, HeterMPC can adequately utilize the structural knowledge of conversations for response generation. Experimental results on the Ubuntu Internet Relay Chat (IRC) channel benchmark show that HeterMPC outperforms various baseline models for response generation in MPCs.
Multi-View Document Representation Learning for Open-Domain Dense Retrieval
Mar 16, 2022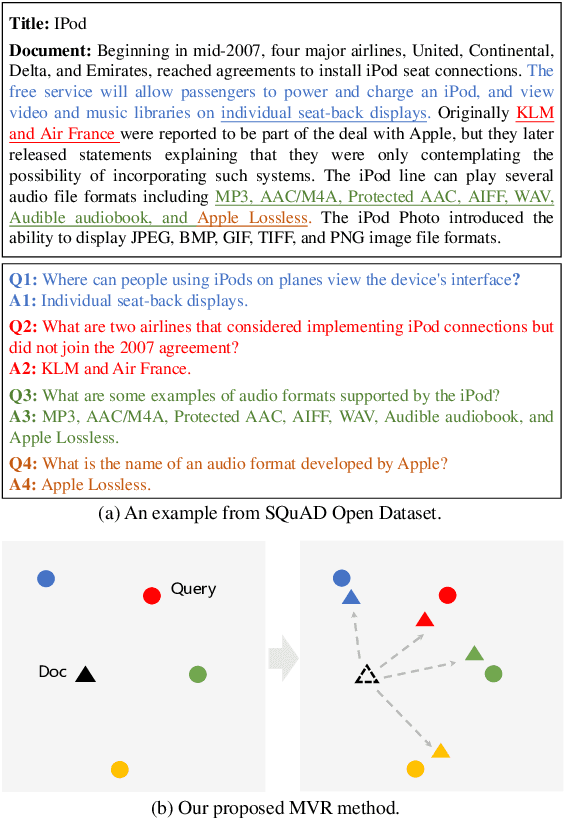
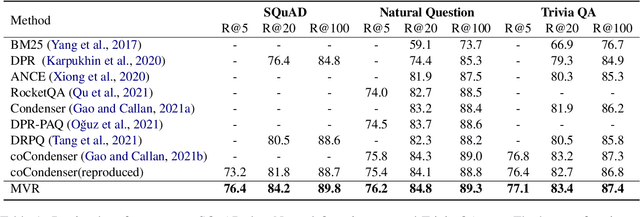
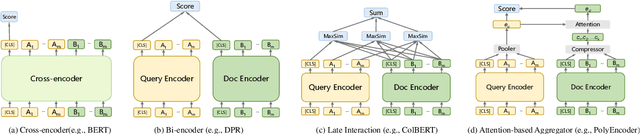
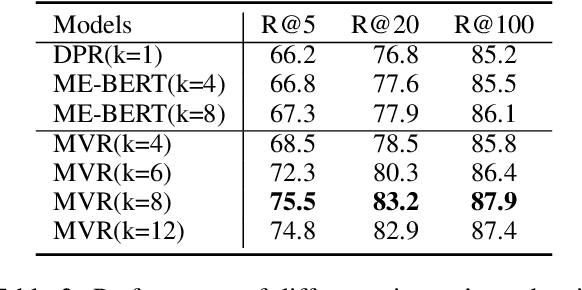
Dense retrieval has achieved impressive advances in first-stage retrieval from a large-scale document collection, which is built on bi-encoder architecture to produce single vector representation of query and document. However, a document can usually answer multiple potential queries from different views. So the single vector representation of a document is hard to match with multi-view queries, and faces a semantic mismatch problem. This paper proposes a multi-view document representation learning framework, aiming to produce multi-view embeddings to represent documents and enforce them to align with different queries. First, we propose a simple yet effective method of generating multiple embeddings through viewers. Second, to prevent multi-view embeddings from collapsing to the same one, we further propose a global-local loss with annealed temperature to encourage the multiple viewers to better align with different potential queries. Experiments show our method outperforms recent works and achieves state-of-the-art results.
ClarET: Pre-training a Correlation-Aware Context-To-Event Transformer for Event-Centric Generation and Classification
Mar 09, 2022
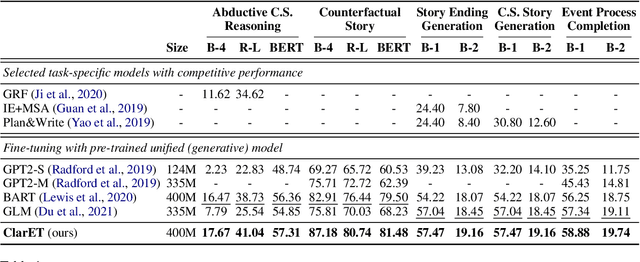
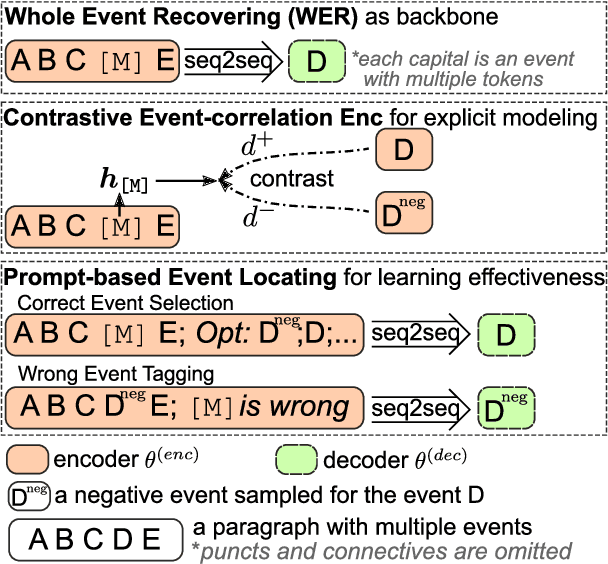
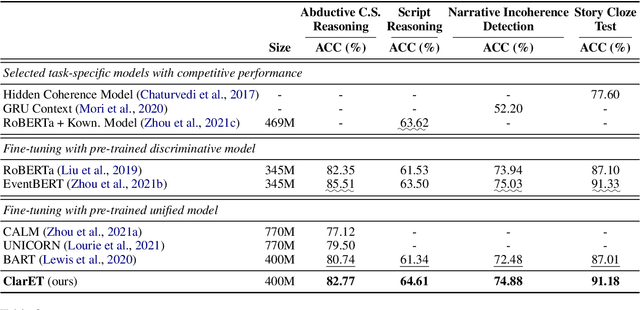
Generating new events given context with correlated ones plays a crucial role in many event-centric reasoning tasks. Existing works either limit their scope to specific scenarios or overlook event-level correlations. In this paper, we propose to pre-train a general Correlation-aware context-to-Event Transformer (ClarET) for event-centric reasoning. To achieve this, we propose three novel event-centric objectives, i.e., whole event recovering, contrastive event-correlation encoding and prompt-based event locating, which highlight event-level correlations with effective training. The proposed ClarET is applicable to a wide range of event-centric reasoning scenarios, considering its versatility of (i) event-correlation types (e.g., causal, temporal, contrast), (ii) application formulations (i.e., generation and classification), and (iii) reasoning types (e.g., abductive, counterfactual and ending reasoning). Empirical fine-tuning results, as well as zero- and few-shot learning, on 9 benchmarks (5 generation and 4 classification tasks covering 4 reasoning types with diverse event correlations), verify its effectiveness and generalization ability.
NÜWA-LIP: Language Guided Image Inpainting with Defect-free VQGAN
Feb 10, 2022Language guided image inpainting aims to fill in the defective regions of an image under the guidance of text while keeping non-defective regions unchanged. However, the encoding process of existing models suffers from either receptive spreading of defective regions or information loss of non-defective regions, giving rise to visually unappealing inpainting results. To address the above issues, this paper proposes N\"UWA-LIP by incorporating defect-free VQGAN (DF-VQGAN) with multi-perspective sequence to sequence (MP-S2S). In particular, DF-VQGAN introduces relative estimation to control receptive spreading and adopts symmetrical connections to protect information. MP-S2S further enhances visual information from complementary perspectives, including both low-level pixels and high-level tokens. Experiments show that DF-VQGAN performs more robustness than VQGAN. To evaluate the inpainting performance of our model, we built up 3 open-domain benchmarks, where N\"UWA-LIP is also superior to recent strong baselines.
PCL: Peer-Contrastive Learning with Diverse Augmentations for Unsupervised Sentence Embeddings
Jan 28, 2022
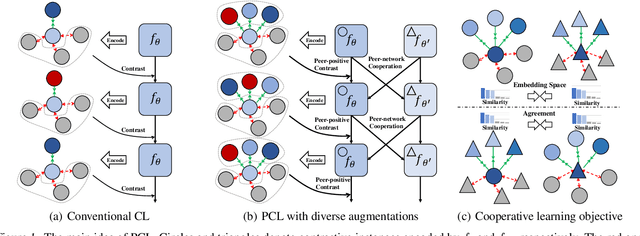
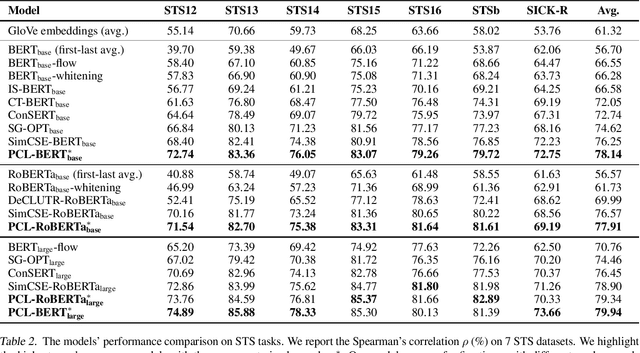
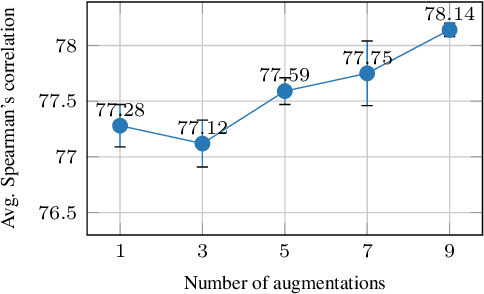
Learning sentence embeddings in an unsupervised manner is fundamental in natural language processing. Recent common practice is to couple pre-trained language models with unsupervised contrastive learning, whose success relies on augmenting a sentence with a semantically-close positive instance to construct contrastive pairs. Nonetheless, existing approaches usually depend on a mono-augmenting strategy, which causes learning shortcuts towards the augmenting biases and thus corrupts the quality of sentence embeddings. A straightforward solution is resorting to more diverse positives from a multi-augmenting strategy, while an open question remains about how to unsupervisedly learn from the diverse positives but with uneven augmenting qualities in the text field. As one answer, we propose a novel Peer-Contrastive Learning (PCL) with diverse augmentations. PCL constructs diverse contrastive positives and negatives at the group level for unsupervised sentence embeddings. PCL can perform peer-positive contrast as well as peer-network cooperation, which offers an inherent anti-bias ability and an effective way to learn from diverse augmentations. Experiments on STS benchmarks verify the effectiveness of our PCL against its competitors in unsupervised sentence embeddings.