 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogVED: A Pre-trained Latent Variable Encoder-Decoder Model for Dialog Response Generation
Apr 27, 2022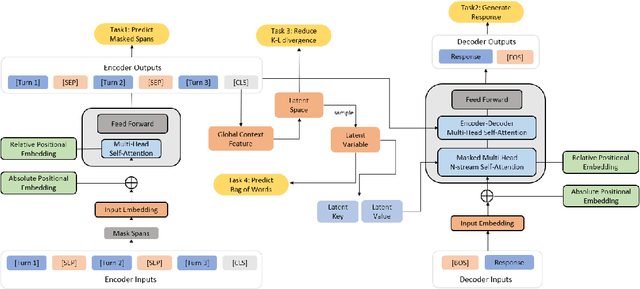
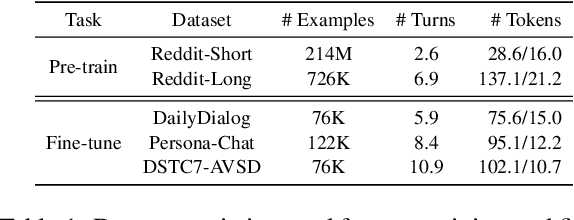
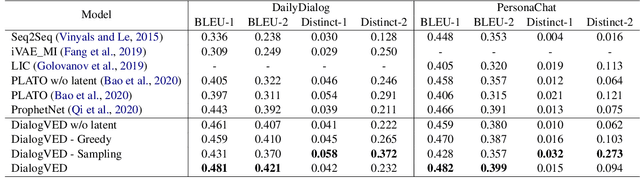
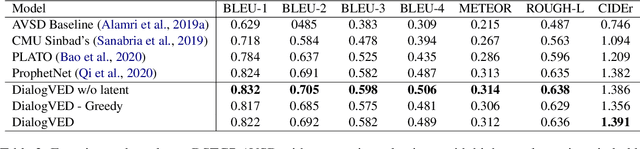
Dialog response generation in open domain is an important research topic where the main challenge is to generate relevant and diverse responses. In this paper, we propose a new dialog pre-training framework called DialogVED, which introduces continuous latent variables into the enhanced encoder-decoder pre-training framework to increase the relevance and diversity of responses. With the help of a large dialog corpus (Reddit), we pre-train the model using the following 4 tasks, used in training language models (LMs) and Variational Autoencoders (VAEs) literature: 1) masked language model; 2) response generation; 3) bag-of-words prediction; and 4) KL divergence reduction. We also add additional parameters to model the turn structure in dialogs to improve the performance of the pre-trained model. We conduct experiments on PersonaChat, DailyDialog, and DSTC7-AVSD benchmarks for response generation. Experimental results show that our model achieves the new state-of-the-art results on all these datasets.
CodeRetriever: Unimodal and Bimodal Contrastive Learning
Jan 26, 2022
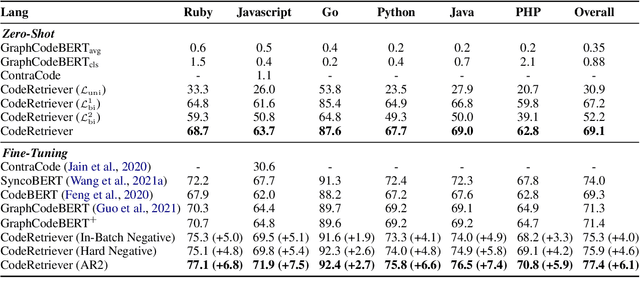
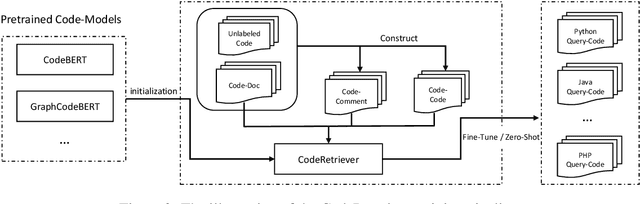
In this paper, we propose the CodeRetriever model, which combines the unimodal and bimodal contrastive learning to train function-level code semantic representations, specifically for the code search task. For unimodal contrastive learning, we design a semantic-guided method to build positive code pairs based on the documentation and function name. For bimodal contrastive learning, we leverage the documentation and in-line comments of code to build text-code pairs. Both contrastive objectives can fully leverage the large-scale code corpus for pre-training. Experimental results on several public benchmarks, (i.e., CodeSearch, CoSQA, etc.) demonstrate the effectiveness of CodeRetriever in the zero-shot setting. By fine-tuning with domain/language specified downstream data, CodeRetriever achieves the new state-of-the-art performance with significant improvement over existing code pre-trained models. We will make the code, model checkpoint, and constructed datasets publicly available.
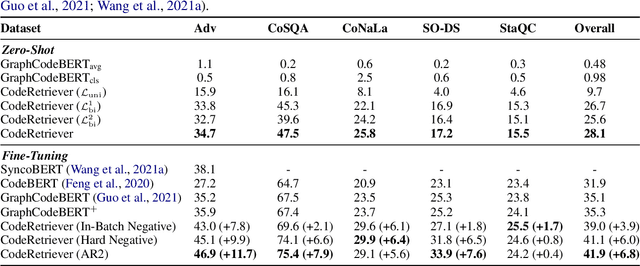
Contextual Fine-to-Coarse Distillation for Coarse-grained Response Selection in Open-Domain Conversations
Sep 24, 2021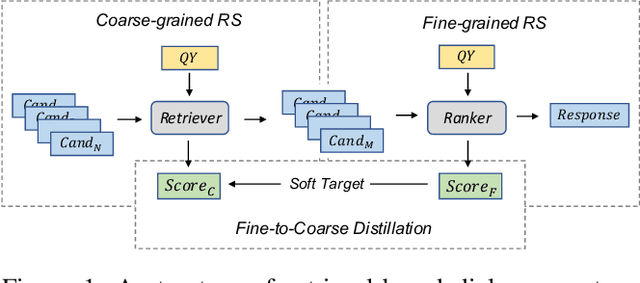
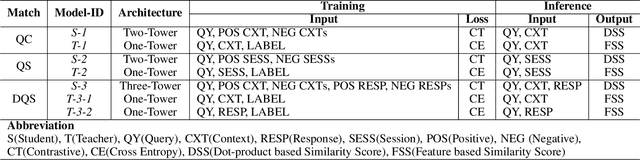
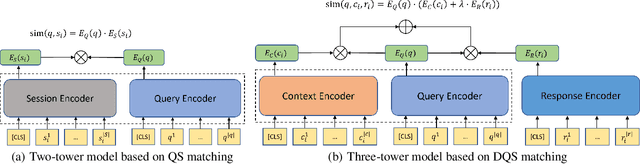

We study the problem of coarse-grained response selection in retrieval-based dialogue systems. The problem is equally important with fine-grained response selection, but is less explored in existing literature. In this paper, we propose a Contextual Fine-to-Coarse (CFC) distilled model for coarse-grained response selection in open-domain conversations. In our CFC model, dense representations of query, candidate response and corresponding context is learned based on the multi-tower architecture, and more expressive knowledge learned from the one-tower architecture (fine-grained) is distilled into the multi-tower architecture (coarse-grained) to enhance the performance of the retriever. To evaluate the performance of our proposed model, we construct two new datasets based on the Reddit comments dump and Twitter corpus. Extensive experimental results on the two datasets show that the proposed methods achieve a significant improvement over all evaluation metrics compared with traditional baseline methods.
ProphetNet-X: Large-Scale Pre-training Models for English, Chinese, Multi-lingual, Dialog, and Code Generation
Apr 16, 2021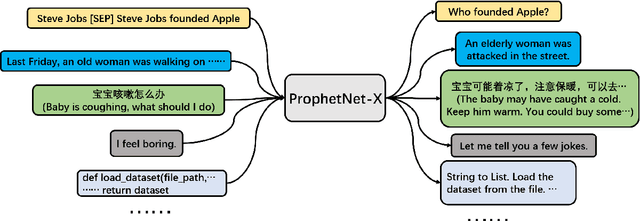

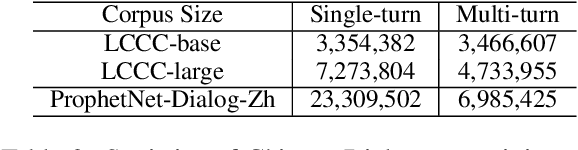
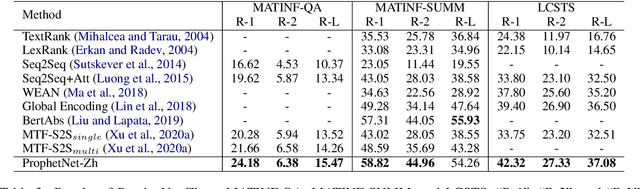
Now, the pre-training technique is ubiquitous in natural language processing field. ProphetNet is a pre-training based natural language generation method which shows powerful performance on English text summarization and question generation tasks. In this paper, we extend ProphetNet into other domains and languages, and present the ProphetNet family pre-training models, named ProphetNet-X, where X can be English, Chinese, Multi-lingual, and so on. We pre-train a cross-lingual generation model ProphetNet-Multi, a Chinese generation model ProphetNet-Zh, two open-domain dialog generation models ProphetNet-Dialog-En and ProphetNet-Dialog-Zh. And also, we provide a PLG (Programming Language Generation) model ProphetNet-Code to show the generation performance besides NLG (Natural Language Generation) tasks. In our experiments, ProphetNet-X models achieve new state-of-the-art performance on 10 benchmarks. All the models of ProphetNet-X share the same model structure, which allows users to easily switch between different models. We make the code and models publicly available, and we will keep updating more pre-training models and finetuning scripts. A video to introduce ProphetNet-X usage is also released.