 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptual Flow Network for Visually Grounded Reasoning
May 04, 2026Despite the success of Large-Vision Language Models (LVLMs), general optimization objectives (e.g., standard MLE) fail to constrain visual trajectories, leading to language bias and hallucination. To mitigate this, current methods introduce geometric priors from visual experts as additional supervision. However, we observe that such supervision is typically suboptimal: it is biased toward geometric precision and offers limited reasoning utility. To bridge this gap, we propose Perceptual Flow Network (PFlowNet), which eschews rigid alignment with the expert priors and achieves interpretable yet more effective visual reasoning. Specifically, PFlowNet decouples perception from reasoning to establish a self-conditioned generation process. Based on this, it integrates multi-dimensional rewards with vicinal geometric shaping via variational reinforcement learning, thereby facilitating reasoning-oriented perceptual behaviors while preserving visual reliability. PFlowNet delivers a provable performance guarantee and competitive empirical results, particularly setting new SOTA records on V* Bench (90.6%) and MME-RealWorld-lite (67.0%).
TC-AE: Unlocking Token Capacity for Deep Compression Autoencoders
Apr 08, 2026We propose TC-AE, a ViT-based architecture for deep compression autoencoders. Existing methods commonly increase the channel number of latent representations to maintain reconstruction quality under high compression ratios. However, this strategy often leads to latent representation collapse, which degrades generative performance. Instead of relying on increasingly complex architectures or multi-stage training schemes, TC-AE addresses this challenge from the perspective of the token space, the key bridge between pixels and image latents, through two complementary innovations: Firstly, we study token number scaling by adjusting the patch size in ViT under a fixed latent budget, and identify aggressive token-to-latent compression as the key factor that limits effective scaling. To address this issue, we decompose token-to-latent compression into two stages, reducing structural information loss and enabling effective token number scaling for generation. Secondly, to further mitigate latent representation collapse, we enhance the semantic structure of image tokens via joint self-supervised training, leading to more generative-friendly latents. With these designs, TC-AE achieves substantially improved reconstruction and generative performance under deep compression. We hope our research will advance ViT-based tokenizer for visual generation.
DeepScan: A Training-Free Framework for Visually Grounded Reasoning in Large Vision-Language Models
Mar 04, 2026Humans can robustly localize visual evidence and provide grounded answers even in noisy environments by identifying critical cues and then relating them to the full context in a bottom-up manner. Inspired by this, we propose DeepScan, a training-free framework that combines Hierarchical Scanning, Refocusing, and Evidence-Enhanced Reasoning for visually grounded reasoning in Large Vision-Language Models (LVLMs). Unlike existing methods that pursue one-shot localization of complete evidence, Hierarchical Scanning performs local cue exploration and multi-scale evidence extraction to recover evidence in a bottom-up manner, effectively mitigating the impacts of distractive context. Refocusing then optimizes the localized evidence view through collaboration of LVLMs and visual experts. Finally, Evidence-Enhanced Reasoning aggregates multi-granular views via a hybrid evidence memory and yields accurate and interpretable answers. Experimental results demonstrate that DeepScan significantly boosts LVLMs in diverse visual tasks, especially in fine-grained visual understanding. It achieves 90.6% overall accuracy on V* when integrated with Qwen2.5-VL-7B. Moreover, DeepScan provides consistent improvements for LVLMs across various architectures and model scales without additional adaptation cost.
* 18 pages 17 figures
Why 1 + 1 < 1 in Visual Token Pruning: Beyond Naive Integration via Multi-Objective Balanced Covering
May 15, 2025Existing visual token pruning methods target prompt alignment and visual preservation with static strategies, overlooking the varying relative importance of these objectives across tasks, which leads to inconsistent performance. To address this, we derive the first closed-form error bound for visual token pruning based on the Hausdorff distance, uniformly characterizing the contributions of both objectives. Moreover, leveraging $\epsilon$-covering theory, we reveal an intrinsic trade-off between these objectives and quantify their optimal attainment levels under a fixed budget. To practically handle this trade-off, we propose Multi-Objective Balanced Covering (MoB), which reformulates visual token pruning as a bi-objective covering problem. In this framework, the attainment trade-off reduces to budget allocation via greedy radius trading. MoB offers a provable performance bound and linear scalability with respect to the number of input visual tokens, enabling adaptation to challenging pruning scenarios. Extensive experiments show that MoB preserves 96.4% of performance for LLaVA-1.5-7B using only 11.1% of the original visual tokens and accelerates LLaVA-Next-7B by 1.3-1.5$\times$ with negligible performance loss. Additionally, evaluations on Qwen2-VL and Video-LLaVA confirm that MoB integrates seamlessly into advanced MLLMs and diverse vision-language tasks.
Dual-stream Time-Delay Neural Network with Dynamic Global Filter for Speaker Verification
Mar 20, 2023The time-delay neural network (TDNN) is one of the state-of-the-art models for text-independent speaker verification. However, it is difficult for conventional TDNN to capture global context that has been proven critical for robust speaker representations and long-duration speaker verification in many recent works. Besides, the common solutions, e.g., self-attention, have quadratic complexity for input tokens, which makes them computationally unaffordable when applied to the feature maps with large sizes in TDNN. To address these issues, we propose the Global Filter for TDNN, which applies log-linear complexity FFT/IFFT and a set of differentiable frequency-domain filters to efficiently model the long-term dependencies in speech. Besides, a dynamic filtering strategy, and a sparse regularization method are specially designed to enhance the performance of the global filter and prevent it from overfitting. Furthermore, we construct a dual-stream TDNN (DS-TDNN), which splits the basic channels for complexity reduction and employs the global filter to increase recognition performance. Experiments on Voxceleb and SITW databases show that the DS-TDNN achieves approximate 10% improvement with a decline over 28% and 15% in complexity and parameters compared with the ECAPA-TDNN. Besides, it has the best trade-off between efficiency and effectiveness compared with other popular baseline systems when facing long-duration speech. Finally, visualizations and a detailed ablation study further reveal the advantages of the DS-TDNN.
PSVRF: Learning to restore Pitch-Shifted Voice without reference
Oct 06, 2022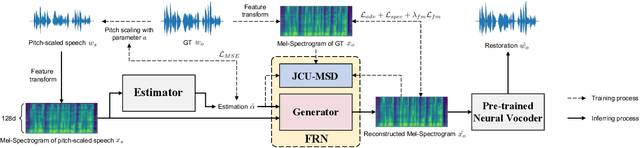
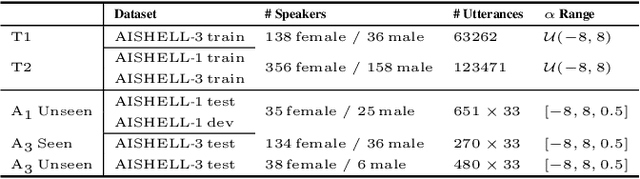
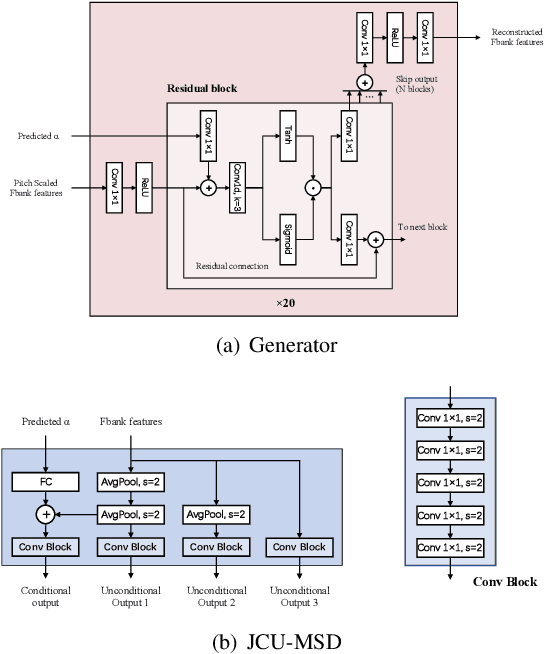
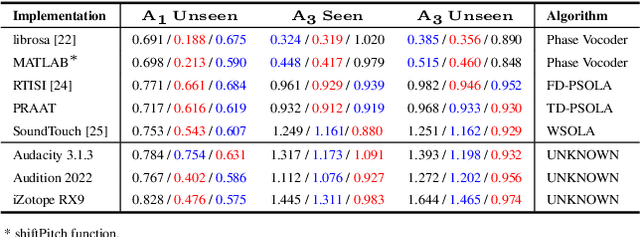
Pitch scaling algorithms have a significant impact on the security of Automatic Speaker Verification (ASV) systems. Although numerous anti-spoofing algorithms have been proposed to identify the pitch-shifted voice and even restore it to the original version, they either have poor performance or require the original voice as a reference, limiting the prospects of applications. In this paper, we propose a no-reference approach termed PSVRF$^1$ for high-quality restoration of pitch-shifted voice. Experiments on AISHELL-1 and AISHELL-3 demonstrate that PSVRF can restore the voice disguised by various pitch-scaling techniques, which obviously enhances the robustness of ASV systems to pitch-scaling attacks. Furthermore, the performance of PSVRF even surpasses that of the state-of-the-art reference-based approach.