 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruneHal: Reducing Hallucinations in Multi-modal Large Language Models through Adaptive KV Cache Pruning
Oct 22, 2025While multi-modal large language models (MLLMs) have made significant progress in recent years, the issue of hallucinations remains a major challenge. To mitigate this phenomenon, existing solutions either introduce additional data for further training or incorporate external or internal information during inference. However, these approaches inevitably introduce extra computational costs. In this paper, we observe that hallucinations in MLLMs are strongly associated with insufficient attention allocated to visual tokens. In particular, the presence of redundant visual tokens disperses the model's attention, preventing it from focusing on the most informative ones. As a result, critical visual cues are often under-attended, which in turn exacerbates the occurrence of hallucinations. Building on this observation, we propose \textbf{PruneHal}, a training-free, simple yet effective method that leverages adaptive KV cache pruning to enhance the model's focus on critical visual information, thereby mitigating hallucinations. To the best of our knowledge, we are the first to apply token pruning for hallucination mitigation in MLLMs. Notably, our method don't require additional training and incurs nearly no extra inference cost. Moreover, PruneHal is model-agnostic and can be seamlessly integrated with different decoding strategies, including those specifically designed for hallucination mitigation. We evaluate PruneHal on several widely used hallucination evaluation benchmarks using four mainstream MLLMs, achieving robust and outstanding results that highlight the effectiveness and superiority of our method. Our code will be publicly available.
AdaTP: Attention-Debiased Token Pruning for Video Large Language Models
May 26, 2025Video Large Language Models (Video LLMs) have achieved remarkable results in video understanding tasks. However, they often suffer from heavy computational overhead due to the large number of visual tokens generated from multiple video frames. Existing visual token compression methods often rely on attention scores from language models as guidance. However, these scores exhibit inherent biases: global bias reflects a tendency to focus on the two ends of the visual token sequence, while local bias leads to an over-concentration on the same spatial positions across different frames. To address the issue of attention bias, we propose $\textbf{A}$ttention-$\textbf{D}$ebi$\textbf{a}$sed $\textbf{T}$oken $\textbf{P}$runing for Video Large Language Models ($\textbf{AdaTP}$), a novel token pruning pipeline for Video LLMs. AdaTP integrates two dedicated debiasing modules into the pipeline, targeting global attention bias and local attention bias, respectively. Without the need for additional training, our method significantly reduces the computational overhead of Video LLMs while retaining the performance of vanilla models. Extensive evaluation shows that AdaTP achieves state-of-the-art performance in various commonly used video understanding benchmarks. In particular, on LLaVA-OneVision-7B, AdaTP maintains performance without degradation while using only up to $27.3\%$ FLOPs compared to the vanilla model. Our code will be released soon.
[CLS] Token Tells Everything Needed for Training-free Efficient MLLMs
Dec 08, 2024![Figure 1 for [CLS] Token Tells Everything Needed for Training-free Efficient MLLMs](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fdef0b0ef768be4c551f56adc209bf441a4105d6e%2F1-Figure1-1.png&w=640&q=75)
![Figure 2 for [CLS] Token Tells Everything Needed for Training-free Efficient MLLMs](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fdef0b0ef768be4c551f56adc209bf441a4105d6e%2F6-Table1-1.png&w=640&q=75)
![Figure 3 for [CLS] Token Tells Everything Needed for Training-free Efficient MLLMs](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fdef0b0ef768be4c551f56adc209bf441a4105d6e%2F4-Figure2-1.png&w=640&q=75)
![Figure 4 for [CLS] Token Tells Everything Needed for Training-free Efficient MLLMs](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fdef0b0ef768be4c551f56adc209bf441a4105d6e%2F7-Table2-1.png&w=640&q=75)
Multimodal Large Language Models (MLLMs) have recently demonstrated strong performance across a wide range of vision-language tasks, garnering significant attention in the computer vision. However, their efficient deployment remains a substantial challenge due to high computational costs and memory requirements. Recognizing the redundancy of information within the vision modality, recent studies have explored methods for compressing visual tokens in MLLMs to enhance efficiency in a training-free manner. Despite their effectiveness, existing methods like Fast rely on the attention between visual tokens and prompt text tokens as the importance indicator, overlooking the relevance to response text and thus introducing perception bias. In this paper, we demonstrate that in MLLMs, the [CLS] token in the visual encoder inherently knows which visual tokens are important for MLLMs. Building on this prior, we introduce a simple yet effective method for train-free visual token compression, called VTC-CLS. Firstly, it leverages the attention score of the [CLS] token on visual tokens as an importance indicator for pruning visual tokens. Besides, we also explore ensembling the importance scores derived by the [CLS] token from different layers to capture the key visual information more comprehensively. Extensive experiments demonstrate that our VTC-CLS achieves the state-of-the-art performance across various tasks compared with baseline methods. It also brings notably less computational costs in a training-free manner, highlighting its effectiveness and superiority. Code and models are available at \url{https://github.com/THU-MIG/VTC-CLS}.
Paint4Poem: A Dataset for Artistic Visualization of Classical Chinese Poems
Sep 27, 2021

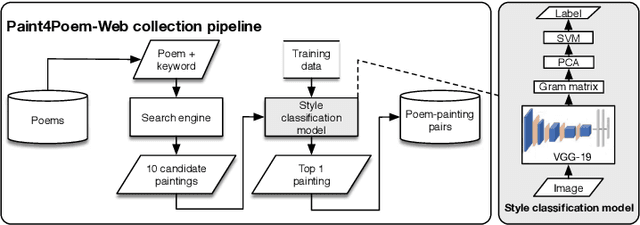
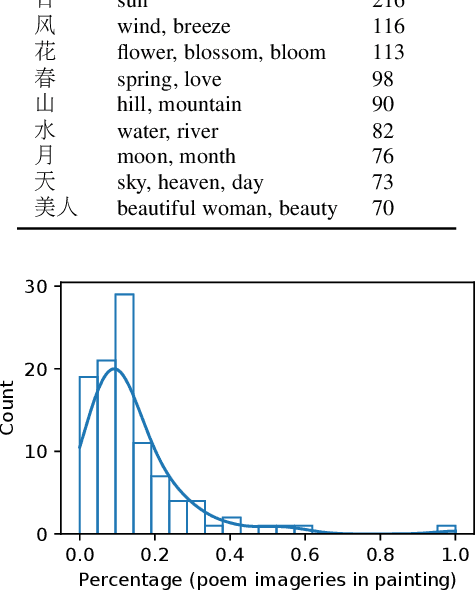
In this work we propose a new task: artistic visualization of classical Chinese poems, where the goal is to generatepaintings of a certain artistic style for classical Chinese poems. For this purpose, we construct a new dataset called Paint4Poem. Thefirst part of Paint4Poem consists of 301 high-quality poem-painting pairs collected manually from an influential modern Chinese artistFeng Zikai. As its small scale poses challenges for effectively training poem-to-painting generation models, we introduce the secondpart of Paint4Poem, which consists of 3,648 caption-painting pairs collected manually from Feng Zikai's paintings and 89,204 poem-painting pairs collected automatically from the web. We expect the former to help learning the artist painting style as it containshis most paintings, and the latter to help learning the semantic relevance between poems and paintings. Further, we analyze Paint4Poem regarding poem diversity, painting style, and the semantic relevance between poems and paintings. We create abenchmark for Paint4Poem: we train two representative text-to-image generation models: AttnGAN and MirrorGAN, and evaluate theirperformance regarding painting pictorial quality, painting stylistic relevance, and semantic relevance between poems and paintings.The results indicate that the models are able to generate paintings that have good pictorial quality and mimic Feng Zikai's style, but thereflection of poem semantics is limited. The dataset also poses many interesting research directions on this task, including transferlearning, few-shot learning, text-to-image generation for low-resource data etc. The dataset is publicly available.(https://github.com/paint4poem/paint4poem)