 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARGenSeg: Image Segmentation with Autoregressive Image Generation Model
Oct 23, 2025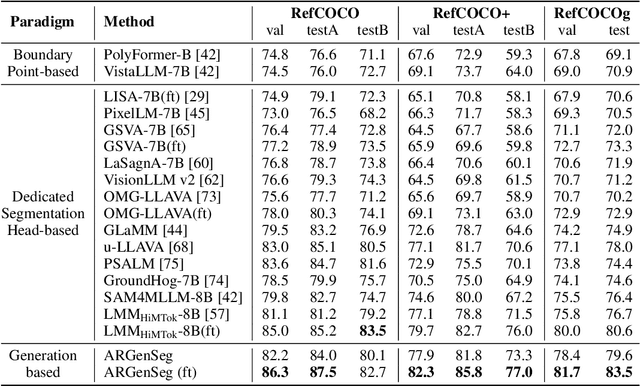
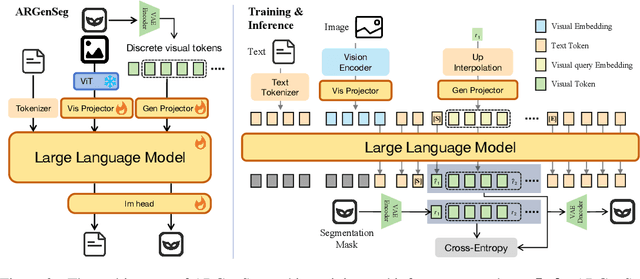


We propose a novel AutoRegressive Generation-based paradigm for image Segmentation (ARGenSeg), achieving multimodal understanding and pixel-level perception within a unified framework. Prior works integrating image segmentation into multimodal large language models (MLLMs) typically employ either boundary points representation or dedicated segmentation heads. These methods rely on discrete representations or semantic prompts fed into task-specific decoders, which limits the ability of the MLLM to capture fine-grained visual details. To address these challenges, we introduce a segmentation framework for MLLM based on image generation, which naturally produces dense masks for target objects. We leverage MLLM to output visual tokens and detokenize them into images using an universal VQ-VAE, making the segmentation fully dependent on the pixel-level understanding of the MLLM. To reduce inference latency, we employ a next-scale-prediction strategy to generate required visual tokens in parallel. Extensive experiments demonstrate that our method surpasses prior state-of-the-art approaches on multiple segmentation datasets with a remarkable boost in inference speed, while maintaining strong understanding capabilities.
CasP: Improving Semi-Dense Feature Matching Pipeline Leveraging Cascaded Correspondence Priors for Guidance
Jul 23, 2025Semi-dense feature matching methods have shown strong performance in challenging scenarios. However, the existing pipeline relies on a global search across the entire feature map to establish coarse matches, limiting further improvements in accuracy and efficiency. Motivated by this limitation, we propose a novel pipeline, CasP, which leverages cascaded correspondence priors for guidance. Specifically, the matching stage is decomposed into two progressive phases, bridged by a region-based selective cross-attention mechanism designed to enhance feature discriminability. In the second phase, one-to-one matches are determined by restricting the search range to the one-to-many prior areas identified in the first phase. Additionally, this pipeline benefits from incorporating high-level features, which helps reduce the computational costs of low-level feature extraction. The acceleration gains of CasP increase with higher resolution, and our lite model achieves a speedup of $\sim2.2\times$ at a resolution of 1152 compared to the most efficient method, ELoFTR. Furthermore, extensive experiments demonstrate its superiority in geometric estimation, particularly with impressive cross-domain generalization. These advantages highlight its potential for latency-sensitive and high-robustness applications, such as SLAM and UAV systems. Code is available at https://github.com/pq-chen/CasP.
Ming-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025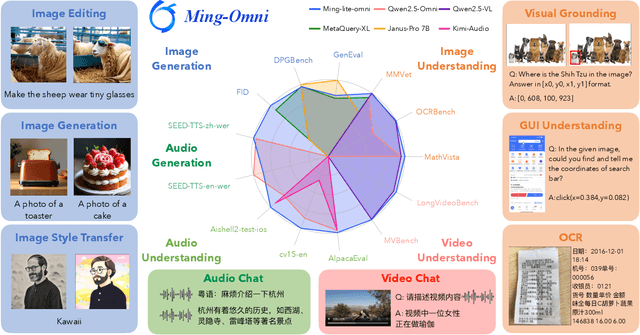
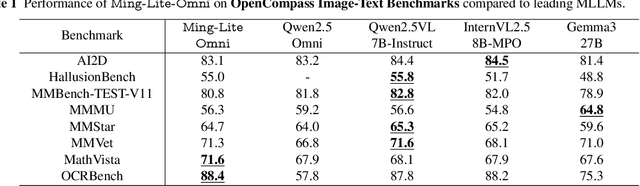
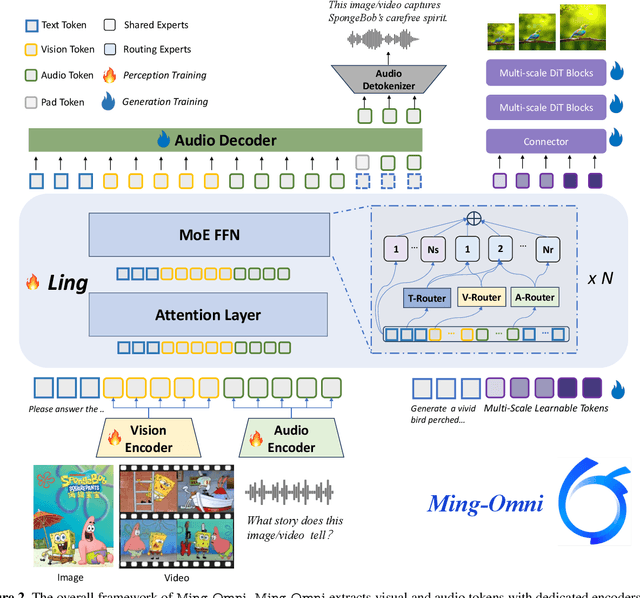
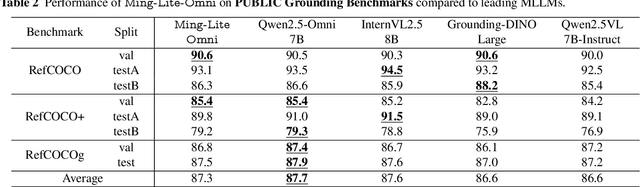
We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
Ming-Lite-Uni: Advancements in Unified Architecture for Natural Multimodal Interaction
May 05, 2025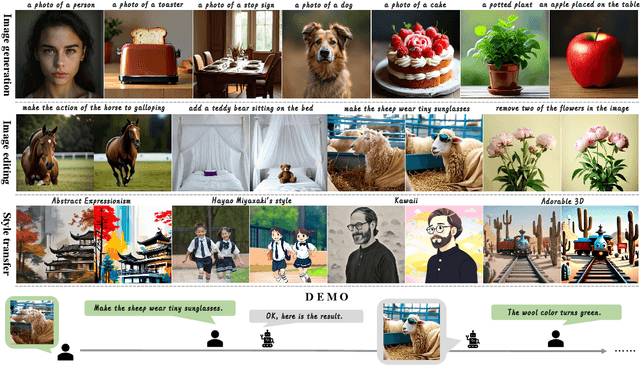

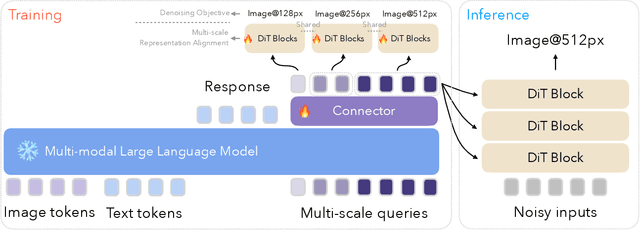
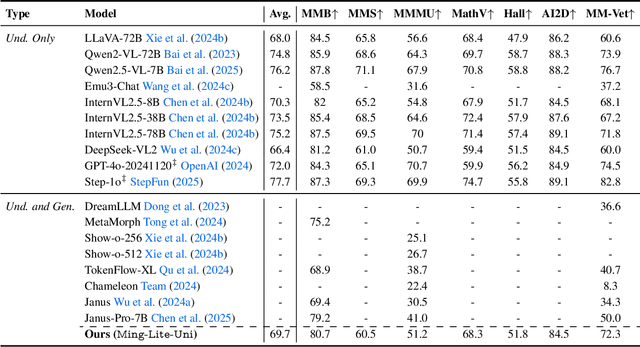
We introduce Ming-Lite-Uni, an open-source multimodal framework featuring a newly designed unified visual generator and a native multimodal autoregressive model tailored for unifying vision and language. Specifically, this project provides an open-source implementation of the integrated MetaQueries and M2-omni framework, while introducing the novel multi-scale learnable tokens and multi-scale representation alignment strategy. By leveraging a fixed MLLM and a learnable diffusion model, Ming-Lite-Uni enables native multimodal AR models to perform both text-to-image generation and instruction based image editing tasks, expanding their capabilities beyond pure visual understanding. Our experimental results demonstrate the strong performance of Ming-Lite-Uni and illustrate the impressive fluid nature of its interactive process. All code and model weights are open-sourced to foster further exploration within the community. Notably, this work aligns with concurrent multimodal AI milestones - such as ChatGPT-4o with native image generation updated in March 25, 2025 - underscoring the broader significance of unified models like Ming-Lite-Uni on the path toward AGI. Ming-Lite-Uni is in alpha stage and will soon be further refined.
Plug-and-Play DISep: Separating Dense Instances for Scene-to-Pixel Weakly-Supervised Change Detection in High-Resolution Remote Sensing Images
Jan 10, 2025Existing Weakly-Supervised Change Detection (WSCD) methods often encounter the problem of "instance lumping" under scene-level supervision, particularly in scenarios with a dense distribution of changed instances (i.e., changed objects). In these scenarios, unchanged pixels between changed instances are also mistakenly identified as changed, causing multiple changes to be mistakenly viewed as one. In practical applications, this issue prevents the accurate quantification of the number of changes. To address this issue, we propose a Dense Instance Separation (DISep) method as a plug-and-play solution, refining pixel features from a unified instance perspective under scene-level supervision. Specifically, our DISep comprises a three-step iterative training process: 1) Instance Localization: We locate instance candidate regions for changed pixels using high-pass class activation maps. 2) Instance Retrieval: We identify and group these changed pixels into different instance IDs through connectivity searching. Then, based on the assigned instance IDs, we extract corresponding pixel-level features on a per-instance basis. 3) Instance Separation: We introduce a separation loss to enforce intra-instance pixel consistency in the embedding space, thereby ensuring separable instance feature representations. The proposed DISep adds only minimal training cost and no inference cost. It can be seamlessly integrated to enhance existing WSCD methods. We achieve state-of-the-art performance by enhancing {three Transformer-based and four ConvNet-based methods} on the LEVIR-CD, WHU-CD, DSIFN-CD, SYSU-CD, and CDD datasets. Additionally, our DISep can be used to improve fully-supervised change detection methods. Code is available at https://github.com/zhenghuizhao/Plug-and-Play-DISep-for-Change-Detection.
Cross-View Geo-Localization with Street-View and VHR Satellite Imagery in Decentrality Settings
Dec 16, 2024Cross-View Geo-Localization tackles the problem of image geo-localization in GNSS-denied environments by matching street-view query images with geo-tagged aerial-view reference images. However, existing datasets and methods often assume center-aligned settings or only consider limited decentrality (i.e., the offset of the query image from the reference image center). This assumption overlooks the challenges present in real-world applications, where large decentrality can significantly enhance localization efficiency but simultaneously lead to a substantial degradation in localization accuracy. To address this limitation, we introduce CVSat, a novel dataset designed to evaluate cross-view geo-localization with a large geographic scope and diverse landscapes, emphasizing the decentrality issue. Meanwhile, we propose AuxGeo (Auxiliary Enhanced Geo-Localization), which leverages a multi-metric optimization strategy with two novel modules: the Bird's-eye view Intermediary Module (BIM) and the Position Constraint Module (PCM). BIM uses bird's-eye view images derived from street-view panoramas as an intermediary, simplifying the cross-view challenge with decentrality to a cross-view problem and a decentrality problem. PCM leverages position priors between cross-view images to establish multi-grained alignment constraints. These modules improve the performance of cross-view geo-localization with the decentrality problem. Extensive experiments demonstrate that AuxGeo outperforms previous methods on our proposed CVSat dataset, mitigating the issue of large decentrality, and also achieves state-of-the-art performance on existing public datasets such as CVUSA, CVACT, and VIGOR.
HomoMatcher: Dense Feature Matching Results with Semi-Dense Efficiency by Homography Estimation
Nov 11, 2024



Feature matching between image pairs is a fundamental problem in computer vision that drives many applications, such as SLAM. Recently, semi-dense matching approaches have achieved substantial performance enhancements and established a widely-accepted coarse-to-fine paradigm. However, the majority of existing methods focus on improving coarse feature representation rather than the fine-matching module. Prior fine-matching techniques, which rely on point-to-patch matching probability expectation or direct regression, often lack precision and do not guarantee the continuity of feature points across sequential images. To address this limitation, this paper concentrates on enhancing the fine-matching module in the semi-dense matching framework. We employ a lightweight and efficient homography estimation network to generate the perspective mapping between patches obtained from coarse matching. This patch-to-patch approach achieves the overall alignment of two patches, resulting in a higher sub-pixel accuracy by incorporating additional constraints. By leveraging the homography estimation between patches, we can achieve a dense matching result with low computational cost. Extensive experiments demonstrate that our method achieves higher accuracy compared to previous semi-dense matchers. Meanwhile, our dense matching results exhibit similar end-point-error accuracy compared to previous dense matchers while maintaining semi-dense efficiency.
POA: Pre-training Once for Models of All Sizes
Aug 02, 2024



Large-scale self-supervised pre-training has paved the way for one foundation model to handle many different vision tasks. Most pre-training methodologies train a single model of a certain size at one time. Nevertheless, various computation or storage constraints in real-world scenarios require substantial efforts to develop a series of models with different sizes to deploy. Thus, in this study, we propose a novel tri-branch self-supervised training framework, termed as POA (Pre-training Once for All), to tackle this aforementioned issue. Our approach introduces an innovative elastic student branch into a modern self-distillation paradigm. At each pre-training step, we randomly sample a sub-network from the original student to form the elastic student and train all branches in a self-distilling fashion. Once pre-trained, POA allows the extraction of pre-trained models of diverse sizes for downstream tasks. Remarkably, the elastic student facilitates the simultaneous pre-training of multiple models with different sizes, which also acts as an additional ensemble of models of various sizes to enhance representation learning. Extensive experiments, including k-nearest neighbors, linear probing evaluation and assessments on multiple downstream tasks demonstrate the effectiveness and advantages of our POA. It achieves state-of-the-art performance using ViT, Swin Transformer and ResNet backbones, producing around a hundred models with different sizes through a single pre-training session. The code is available at: https://github.com/Qichuzyy/POA.
SkySense: A Multi-Modal Remote Sensing Foundation Model Towards Universal Interpretation for Earth Observation Imagery
Dec 15, 2023



Prior studies on Remote Sensing Foundation Model (RSFM) reveal immense potential towards a generic model for Earth Observation. Nevertheless, these works primarily focus on a single modality without temporal and geo-context modeling, hampering their capabilities for diverse tasks. In this study, we present SkySense, a generic billion-scale model, pre-trained on a curated multi-modal Remote Sensing Imagery (RSI) dataset with 21.5 million temporal sequences. SkySense incorporates a factorized multi-modal spatiotemporal encoder taking temporal sequences of optical and Synthetic Aperture Radar (SAR) data as input. This encoder is pre-trained by our proposed Multi-Granularity Contrastive Learning to learn representations across different modal and spatial granularities. To further enhance the RSI representations by the geo-context clue, we introduce Geo-Context Prototype Learning to learn region-aware prototypes upon RSI's multi-modal spatiotemporal features. To our best knowledge, SkySense is the largest Multi-Modal RSFM to date, whose modules can be flexibly combined or used individually to accommodate various tasks. It demonstrates remarkable generalization capabilities on a thorough evaluation encompassing 16 datasets over 7 tasks, from single- to multi-modal, static to temporal, and classification to localization. SkySense surpasses 18 recent RSFMs in all test scenarios. Specifically, it outperforms the latest models such as GFM, SatLas and Scale-MAE by a large margin, i.e., 2.76%, 3.67% and 3.61% on average respectively. We will release the pre-trained weights to facilitate future research and Earth Observation applications.
Exploring Effective Priors and Efficient Models for Weakly-Supervised Change Detection
Jul 27, 2023



Weakly-supervised change detection (WSCD) aims to detect pixel-level changes with only image-level annotations. Owing to its label efficiency, WSCD is drawing increasing attention recently. However, current WSCD methods often encounter the challenge of change missing and fabricating, i.e., the inconsistency between image-level annotations and pixel-level predictions. Specifically, change missing refer to the situation that the WSCD model fails to predict any changed pixels, even though the image-level label indicates changed, and vice versa for change fabricating. To address this challenge, in this work, we leverage global-scale and local-scale priors in WSCD and propose two components: a Dilated Prior (DP) decoder and a Label Gated (LG) constraint. The DP decoder decodes samples with the changed image-level label, skips samples with the unchanged label, and replaces them with an all-unchanged pixel-level label. The LG constraint is derived from the correspondence between changed representations and image-level labels, penalizing the model when it mispredicts the change status. Additionally, we develop TransWCD, a simple yet powerful transformer-based model, showcasing the potential of weakly-supervised learning in change detection. By integrating the DP decoder and LG constraint into TransWCD, we form TransWCD-DL. Our proposed TransWCD and TransWCD-DL achieve significant +6.33% and +9.55% F1 score improvements over the state-of-the-art methods on the WHU-CD dataset, respectively. Some performance metrics even exceed several fully-supervised change detection (FSCD) competitors. Code will be available at https://github.com/zhenghuizhao/TransWCD.