 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniNFT: Modality-wise Omni Diffusion Reinforcement for Joint Audio-Video Generation
May 12, 2026Recent advances in joint audio-video generation have been remarkable, yet real-world applications demand strong per-modality fidelity, cross-modal alignment, and fine-grained synchronization. Reinforcement Learning (RL) offers a promising paradigm, but its extension to multi-objective and multi-modal joint audio-video generation remains unexplored. Notably, our in-depth analysis first reveals that the primary obstacles to applying RL in this stem from: (i) multi-objective advantages inconsistency, where the advantages of multimodal outputs are not always consistent within a group; (ii) multi-modal gradients imbalance, where video-branch gradients leak into shallow audio layers responsible for intra-modal generation; (iii) uniform credit assignment, where fine-grained cross-modal alignment regions fail to get efficient exploration. These shortcomings suggest that vanilla RL fine-tuning strategy with a single global advantage often leads to suboptimal results. To address these challenges, we propose OmniNFT, a novel modality-aware online diffusion RL framework with three key innovations: (1) Modality-wise advantage routing, which routes independent per-reward advantages to their respective modality generation branches. (2) Layer-wise gradient surgery, which selectively detaches video-branch gradients on shallow audio layers while retaining those for cross-modal interaction layers. (3) Region-wise loss reweighting, which modulates policy optimization toward critical regions related to audio-video synchronization and fine-grained alignment. Extensive experiments on JavisBench and VBench with the LTX-2 backbone demonstrate that OmniNFT achieves comprehensive improvements in audio and video perceptual quality, cross-modal alignment, and audio-video synchronization.
RAE-AR: Taming Autoregressive Models with Representation Autoencoders
Apr 02, 2026The latent space of generative modeling is long dominated by the VAE encoder. The latents from the pretrained representation encoders (e.g., DINO, SigLIP, MAE) are previously considered inappropriate for generative modeling. Recently, RAE method lights the hope and reveals that the representation autoencoder can also achieve competitive performance as the VAE encoder. However, the integration of representation autoencoder into continuous autoregressive (AR) models, remains largely unexplored. In this work, we investigate the challenges of employing high-dimensional representation autoencoders within the AR paradigm, denoted as \textit{RAE-AR}. We focus on the unique properties of AR models and identify two primary hurdles: complex token-wise distribution modeling and the high-dimensionality amplified training-inference gap (exposure bias). To address these, we introduce token simplification via distribution normalization to ease modeling difficulty and improve convergence. Furthermore, we enhance prediction robustness by incorporating Gaussian noise injection during training to mitigate exposure bias. Our empirical results demonstrate that these modifications substantially bridge the performance gap, enabling representation autoencoder to achieve results comparable to traditional VAEs on AR models. This work paves the way for a more unified architecture across visual understanding and generative modeling.
MaskFocus: Focusing Policy Optimization on Critical Steps for Masked Image Generation
Dec 21, 2025Reinforcement learning (RL) has demonstrated significant potential for post-training language models and autoregressive visual generative models, but adapting RL to masked generative models remains challenging. The core factor is that policy optimization requires accounting for the probability likelihood of each step due to its multi-step and iterative refinement process. This reliance on entire sampling trajectories introduces high computational cost, whereas natively optimizing random steps often yields suboptimal results. In this paper, we present MaskFocus, a novel RL framework that achieves effective policy optimization for masked generative models by focusing on critical steps. Specifically, we determine the step-level information gain by measuring the similarity between the intermediate images at each sampling step and the final generated image. Crucially, we leverage this to identify the most critical and valuable steps and execute focused policy optimization on them. Furthermore, we design a dynamic routing sampling mechanism based on entropy to encourage the model to explore more valuable masking strategies for samples with low entropy. Extensive experiments on multiple Text-to-Image benchmarks validate the effectiveness of our method.
Group Critical-token Policy Optimization for Autoregressive Image Generation
Sep 26, 2025Recent studies have extended Reinforcement Learning with Verifiable Rewards (RLVR) to autoregressive (AR) visual generation and achieved promising progress. However, existing methods typically apply uniform optimization across all image tokens, while the varying contributions of different image tokens for RLVR's training remain unexplored. In fact, the key obstacle lies in how to identify more critical image tokens during AR generation and implement effective token-wise optimization for them. To tackle this challenge, we propose $\textbf{G}$roup $\textbf{C}$ritical-token $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{GCPO}$), which facilitates effective policy optimization on critical tokens. We identify the critical tokens in RLVR-based AR generation from three perspectives, specifically: $\textbf{(1)}$ Causal dependency: early tokens fundamentally determine the later tokens and final image effect due to unidirectional dependency; $\textbf{(2)}$ Entropy-induced spatial structure: tokens with high entropy gradients correspond to image structure and bridges distinct visual regions; $\textbf{(3)}$ RLVR-focused token diversity: tokens with low visual similarity across a group of sampled images contribute to richer token-level diversity. For these identified critical tokens, we further introduce a dynamic token-wise advantage weight to encourage exploration, based on confidence divergence between the policy model and reference model. By leveraging 30\% of the image tokens, GCPO achieves better performance than GRPO with full tokens. Extensive experiments on multiple text-to-image benchmarks for both AR models and unified multimodal models demonstrate the effectiveness of GCPO for AR visual generation.
VideoMAR: Autoregressive Video Generatio with Continuous Tokens
Jun 18, 2025Masked-based autoregressive models have demonstrated promising image generation capability in continuous space. However, their potential for video generation remains under-explored. In this paper, we propose \textbf{VideoMAR}, a concise and efficient decoder-only autoregressive image-to-video model with continuous tokens, composing temporal frame-by-frame and spatial masked generation. We first identify temporal causality and spatial bi-directionality as the first principle of video AR models, and propose the next-frame diffusion loss for the integration of mask and video generation. Besides, the huge cost and difficulty of long sequence autoregressive modeling is a basic but crucial issue. To this end, we propose the temporal short-to-long curriculum learning and spatial progressive resolution training, and employ progressive temperature strategy at inference time to mitigate the accumulation error. Furthermore, VideoMAR replicates several unique capacities of language models to video generation. It inherently bears high efficiency due to simultaneous temporal-wise KV cache and spatial-wise parallel generation, and presents the capacity of spatial and temporal extrapolation via 3D rotary embeddings. On the VBench-I2V benchmark, VideoMAR surpasses the previous state-of-the-art (Cosmos I2V) while requiring significantly fewer parameters ($9.3\%$), training data ($0.5\%$), and GPU resources ($0.2\%$).
DualFast: Dual-Speedup Framework for Fast Sampling of Diffusion Models
Jun 16, 2025



Diffusion probabilistic models (DPMs) have achieved impressive success in visual generation. While, they suffer from slow inference speed due to iterative sampling. Employing fewer sampling steps is an intuitive solution, but this will also introduces discretization error. Existing fast samplers make inspiring efforts to reduce discretization error through the adoption of high-order solvers, potentially reaching a plateau in terms of optimization. This raises the question: can the sampling process be accelerated further? In this paper, we re-examine the nature of sampling errors, discerning that they comprise two distinct elements: the widely recognized discretization error and the less explored approximation error. Our research elucidates the dynamics between these errors and the step by implementing a dual-error disentanglement strategy. Building on these foundations, we introduce an unified and training-free acceleration framework, DualFast, designed to enhance the speed of DPM sampling by concurrently accounting for both error types, thereby minimizing the total sampling error. DualFast is seamlessly compatible with existing samplers and significantly boost their sampling quality and speed, particularly in extremely few sampling steps. We substantiate the effectiveness of our framework through comprehensive experiments, spanning both unconditional and conditional sampling domains, across both pixel-space and latent-space DPMs.
Ming-Lite-Uni: Advancements in Unified Architecture for Natural Multimodal Interaction
May 05, 2025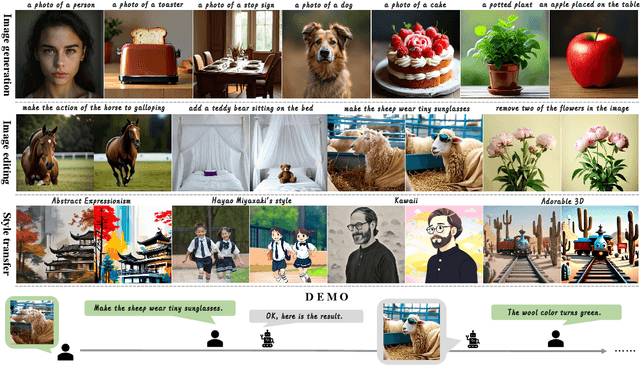

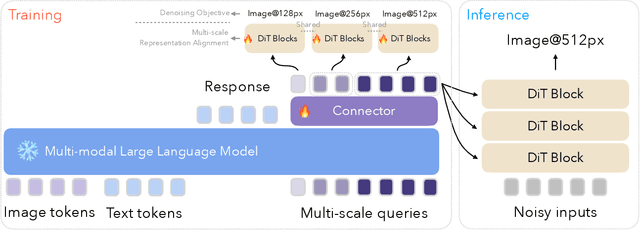
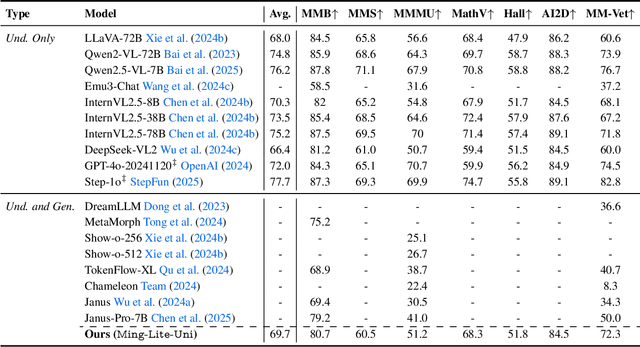
We introduce Ming-Lite-Uni, an open-source multimodal framework featuring a newly designed unified visual generator and a native multimodal autoregressive model tailored for unifying vision and language. Specifically, this project provides an open-source implementation of the integrated MetaQueries and M2-omni framework, while introducing the novel multi-scale learnable tokens and multi-scale representation alignment strategy. By leveraging a fixed MLLM and a learnable diffusion model, Ming-Lite-Uni enables native multimodal AR models to perform both text-to-image generation and instruction based image editing tasks, expanding their capabilities beyond pure visual understanding. Our experimental results demonstrate the strong performance of Ming-Lite-Uni and illustrate the impressive fluid nature of its interactive process. All code and model weights are open-sourced to foster further exploration within the community. Notably, this work aligns with concurrent multimodal AI milestones - such as ChatGPT-4o with native image generation updated in March 25, 2025 - underscoring the broader significance of unified models like Ming-Lite-Uni on the path toward AGI. Ming-Lite-Uni is in alpha stage and will soon be further refined.
FreePCA: Integrating Consistency Information across Long-short Frames in Training-free Long Video Generation via Principal Component Analysis
May 02, 2025



Long video generation involves generating extended videos using models trained on short videos, suffering from distribution shifts due to varying frame counts. It necessitates the use of local information from the original short frames to enhance visual and motion quality, and global information from the entire long frames to ensure appearance consistency. Existing training-free methods struggle to effectively integrate the benefits of both, as appearance and motion in videos are closely coupled, leading to motion inconsistency and visual quality. In this paper, we reveal that global and local information can be precisely decoupled into consistent appearance and motion intensity information by applying Principal Component Analysis (PCA), allowing for refined complementary integration of global consistency and local quality. With this insight, we propose FreePCA, a training-free long video generation paradigm based on PCA that simultaneously achieves high consistency and quality. Concretely, we decouple consistent appearance and motion intensity features by measuring cosine similarity in the principal component space. Critically, we progressively integrate these features to preserve original quality and ensure smooth transitions, while further enhancing consistency by reusing the mean statistics of the initial noise. Experiments demonstrate that FreePCA can be applied to various video diffusion models without requiring training, leading to substantial improvements. Code is available at https://github.com/JosephTiTan/FreePCA.
Exposure Bias Reduction for Enhancing Diffusion Transformer Feature Caching
Mar 10, 2025



Diffusion Transformer (DiT) has exhibited impressive generation capabilities but faces great challenges due to its high computational complexity. To address this problem, various methods, notably feature caching, have been introduced. However, these approaches focus on aligning non-cache diffusion without analyzing the impact of caching on the generation of intermediate processes. So the lack of exploration provides us with room for analysis and improvement. In this paper, we analyze the impact of caching on the SNR of the diffusion process and discern that feature caching intensifies the denoising procedure, and we further identify this as a more severe exposure bias issue. Drawing on this insight, we introduce EB-Cache, a joint cache strategy that aligns the Non-exposure bias (which gives us a higher performance ceiling) diffusion process. Our approach incorporates a comprehensive understanding of caching mechanisms and offers a novel perspective on leveraging caches to expedite diffusion processes. Empirical results indicate that EB-Cache optimizes model performance while concurrently facilitating acceleration. Specifically, in the 50-step generation process, EB-Cache achieves 1.49$\times$ acceleration with 0.63 FID reduction from 3.69, surpassing prior acceleration methods. Code will be available at \href{https://github.com/aSleepyTree/EB-Cache}{https://github.com/aSleepyTree/EB-Cache}.
Frequency Autoregressive Image Generation with Continuous Tokens
Mar 07, 2025



Autoregressive (AR) models for image generation typically adopt a two-stage paradigm of vector quantization and raster-scan ``next-token prediction", inspired by its great success in language modeling. However, due to the huge modality gap, image autoregressive models may require a systematic reevaluation from two perspectives: tokenizer format and regression direction. In this paper, we introduce the frequency progressive autoregressive (\textbf{FAR}) paradigm and instantiate FAR with the continuous tokenizer. Specifically, we identify spectral dependency as the desirable regression direction for FAR, wherein higher-frequency components build upon the lower one to progressively construct a complete image. This design seamlessly fits the causality requirement for autoregressive models and preserves the unique spatial locality of image data. Besides, we delve into the integration of FAR and the continuous tokenizer, introducing a series of techniques to address optimization challenges and improve the efficiency of training and inference processes. We demonstrate the efficacy of FAR through comprehensive experiments on the ImageNet dataset and verify its potential on text-to-image generation.