 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-world Semantic Segmentation via Contrasting and Clustering Vision-Language Embedding
Jul 19, 2022
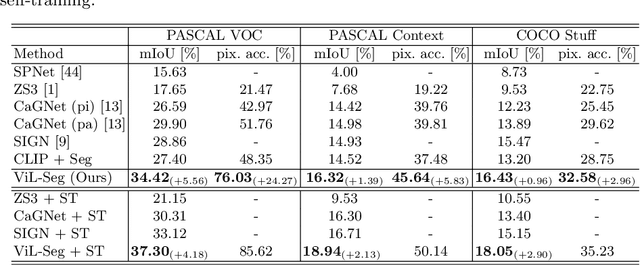
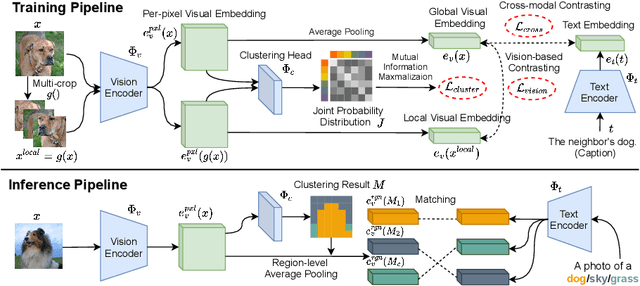
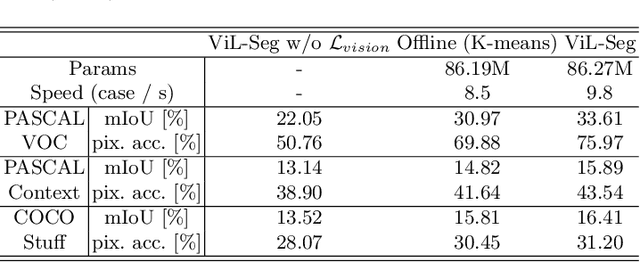
To bridge the gap between supervised semantic segmentation and real-world applications that acquires one model to recognize arbitrary new concepts, recent zero-shot segmentation attracts a lot of attention by exploring the relationships between unseen and seen object categories, yet requiring large amounts of densely-annotated data with diverse base classes. In this paper, we propose a new open-world semantic segmentation pipeline that makes the first attempt to learn to segment semantic objects of various open-world categories without any efforts on dense annotations, by purely exploiting the image-caption data that naturally exist on the Internet. Our method, Vision-language-driven Semantic Segmentation (ViL-Seg), employs an image and a text encoder to generate visual and text embeddings for the image-caption data, with two core components that endow its segmentation ability: First, the image encoder is jointly trained with a vision-based contrasting and a cross-modal contrasting, which encourage the visual embeddings to preserve both fine-grained semantics and high-level category information that are crucial for the segmentation task. Furthermore, an online clustering head is devised over the image encoder, which allows to dynamically segment the visual embeddings into distinct semantic groups such that they can be classified by comparing with various text embeddings to complete our segmentation pipeline. Experiments show that without using any data with dense annotations, our method can directly segment objects of arbitrary categories, outperforming zero-shot segmentation methods that require data labeling on three benchmark datasets.
Task-Customized Self-Supervised Pre-training with Scalable Dynamic Routing
May 26, 2022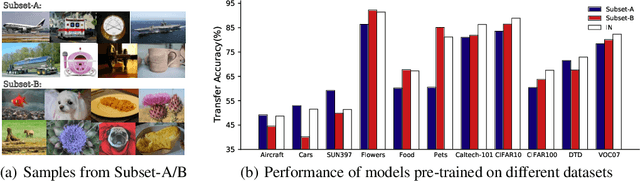
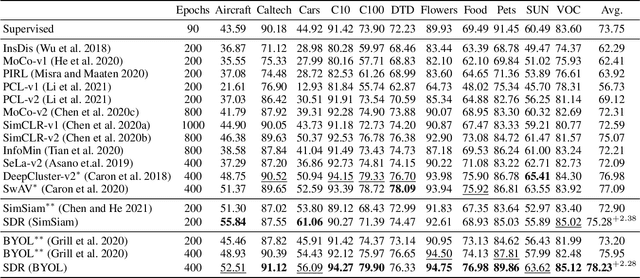
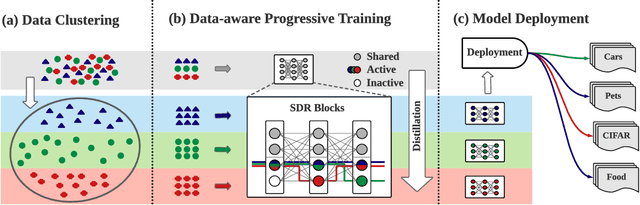
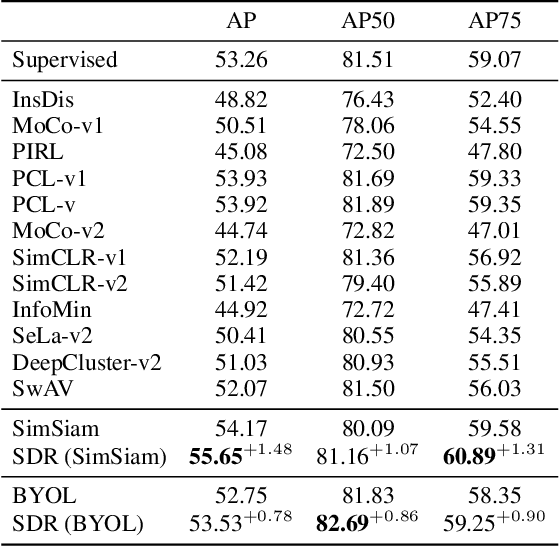
Self-supervised learning (SSL), especially contrastive methods, has raised attraction recently as it learns effective transferable representations without semantic annotations. A common practice for self-supervised pre-training is to use as much data as possible. For a specific downstream task, however, involving irrelevant data in pre-training may degenerate the downstream performance, observed from our extensive experiments. On the other hand, for existing SSL methods, it is burdensome and infeasible to use different downstream-task-customized datasets in pre-training for different tasks. To address this issue, we propose a novel SSL paradigm called Scalable Dynamic Routing (SDR), which can be trained once and deployed efficiently to different downstream tasks with task-customized pre-trained models. Specifically, we construct the SDRnet with various sub-nets and train each sub-net with only one subset of the data by data-aware progressive training. When a downstream task arrives, we route among all the pre-trained sub-nets to get the best along with its corresponding weights. Experiment results show that our SDR can train 256 sub-nets on ImageNet simultaneously, which provides better transfer performance than a unified model trained on the full ImageNet, achieving state-of-the-art (SOTA) averaged accuracy over 11 downstream classification tasks and AP on PASCAL VOC detection task.
ManiTrans: Entity-Level Text-Guided Image Manipulation via Token-wise Semantic Alignment and Generation
Apr 09, 2022

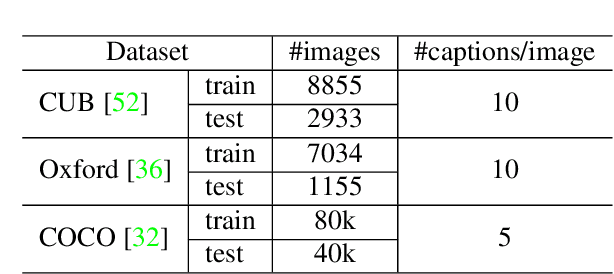
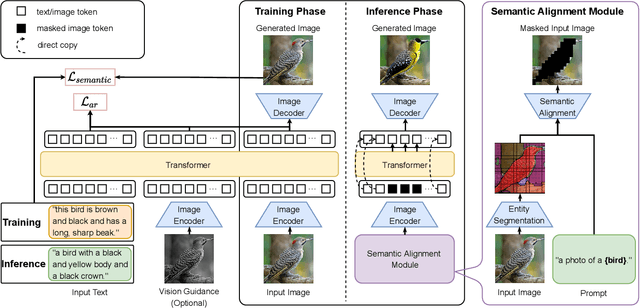
Existing text-guided image manipulation methods aim to modify the appearance of the image or to edit a few objects in a virtual or simple scenario, which is far from practical application. In this work, we study a novel task on text-guided image manipulation on the entity level in the real world. The task imposes three basic requirements, (1) to edit the entity consistent with the text descriptions, (2) to preserve the text-irrelevant regions, and (3) to merge the manipulated entity into the image naturally. To this end, we propose a new transformer-based framework based on the two-stage image synthesis method, namely \textbf{ManiTrans}, which can not only edit the appearance of entities but also generate new entities corresponding to the text guidance. Our framework incorporates a semantic alignment module to locate the image regions to be manipulated, and a semantic loss to help align the relationship between the vision and language. We conduct extensive experiments on the real datasets, CUB, Oxford, and COCO datasets to verify that our method can distinguish the relevant and irrelevant regions and achieve more precise and flexible manipulation compared with baseline methods. The project homepage is \url{https://jawang19.github.io/manitrans}.
Laneformer: Object-aware Row-Column Transformers for Lane Detection
Mar 18, 2022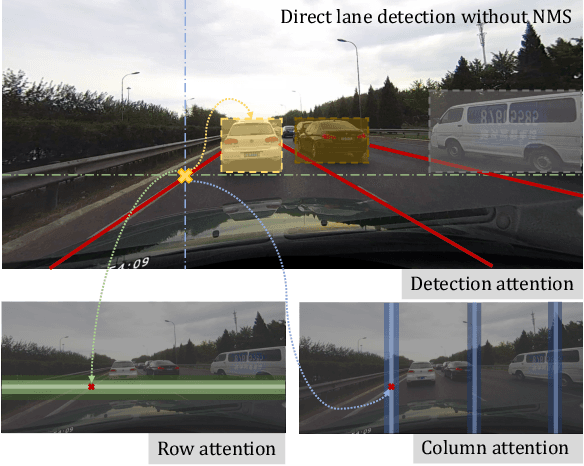
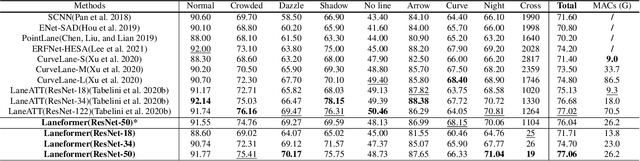
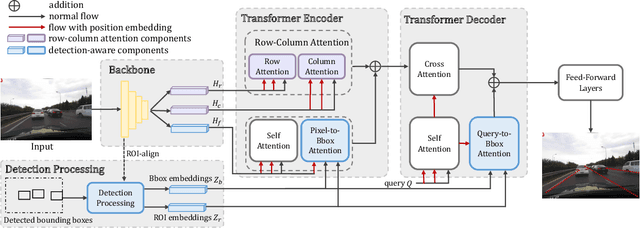
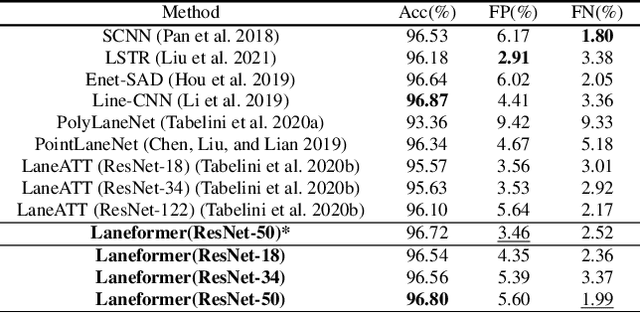
We present Laneformer, a conceptually simple yet powerful transformer-based architecture tailored for lane detection that is a long-standing research topic for visual perception in autonomous driving. The dominant paradigms rely on purely CNN-based architectures which often fail in incorporating relations of long-range lane points and global contexts induced by surrounding objects (e.g., pedestrians, vehicles). Inspired by recent advances of the transformer encoder-decoder architecture in various vision tasks, we move forwards to design a new end-to-end Laneformer architecture that revolutionizes the conventional transformers into better capturing the shape and semantic characteristics of lanes, with minimal overhead in latency. First, coupling with deformable pixel-wise self-attention in the encoder, Laneformer presents two new row and column self-attention operations to efficiently mine point context along with the lane shapes. Second, motivated by the appearing objects would affect the decision of predicting lane segments, Laneformer further includes the detected object instances as extra inputs of multi-head attention blocks in the encoder and decoder to facilitate the lane point detection by sensing semantic contexts. Specifically, the bounding box locations of objects are added into Key module to provide interaction with each pixel and query while the ROI-aligned features are inserted into Value module. Extensive experiments demonstrate our Laneformer achieves state-of-the-art performances on CULane benchmark, in terms of 77.1% F1 score. We hope our simple and effective Laneformer will serve as a strong baseline for future research in self-attention models for lane detection.
CODA: A Real-World Road Corner Case Dataset for Object Detection in Autonomous Driving
Mar 15, 2022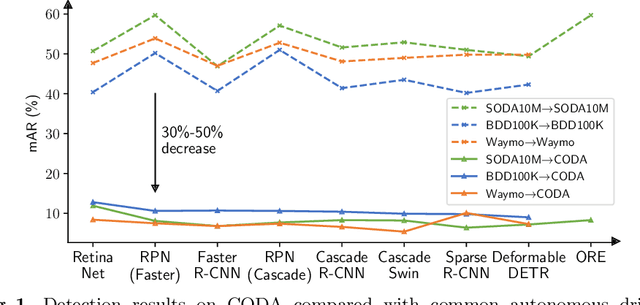
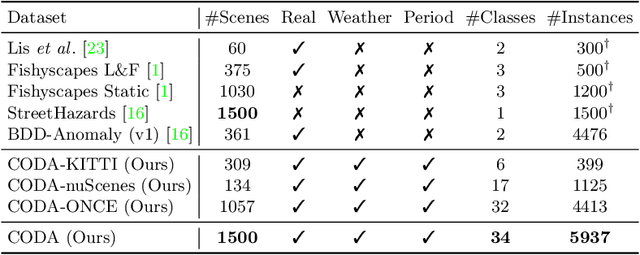

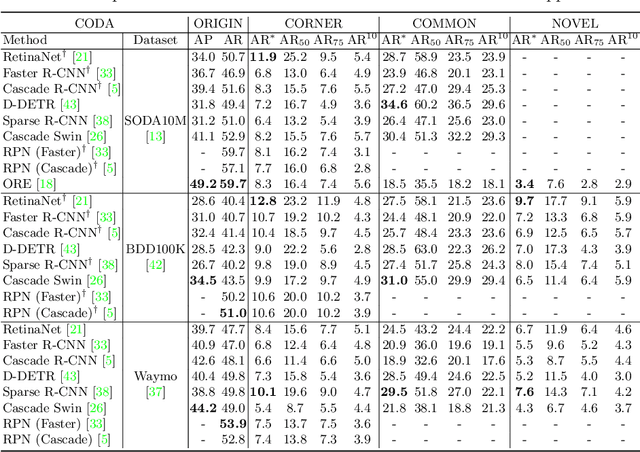
Contemporary deep-learning object detection methods for autonomous driving usually assume prefixed categories of common traffic participants, such as pedestrians and cars. Most existing detectors are unable to detect uncommon objects and corner cases (e.g., a dog crossing a street), which may lead to severe accidents in some situations, making the timeline for the real-world application of reliable autonomous driving uncertain. One main reason that impedes the development of truly reliably self-driving systems is the lack of public datasets for evaluating the performance of object detectors on corner cases. Hence, we introduce a challenging dataset named CODA that exposes this critical problem of vision-based detectors. The dataset consists of 1500 carefully selected real-world driving scenes, each containing four object-level corner cases (on average), spanning 30+ object categories. On CODA, the performance of standard object detectors trained on large-scale autonomous driving datasets significantly drops to no more than 12.8% in mAR. Moreover, we experiment with the state-of-the-art open-world object detector and find that it also fails to reliably identify the novel objects in CODA, suggesting that a robust perception system for autonomous driving is probably still far from reach. We expect our CODA dataset to facilitate further research in reliable detection for real-world autonomous driving. Our dataset will be released at https://coda-dataset.github.io.
Wukong: 100 Million Large-scale Chinese Cross-modal Pre-training Dataset and A Foundation Framework
Mar 10, 2022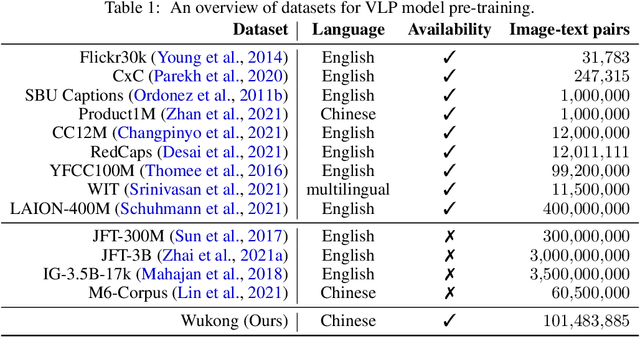
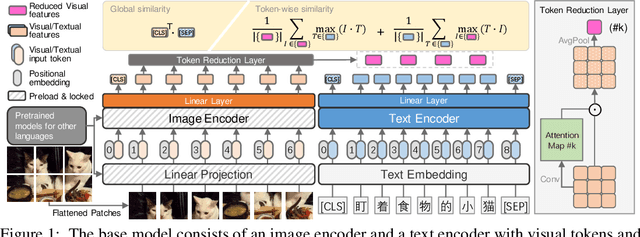


Vision-Language Pre-training (VLP) models have shown remarkable performance on various downstream tasks. Their success heavily relies on the scale of pre-trained cross-modal datasets. However, the lack of large-scale datasets and benchmarks in Chinese hinders the development of Chinese VLP models and broader multilingual applications. In this work, we release a large-scale Chinese cross-modal dataset named Wukong, containing 100 million Chinese image-text pairs from the web. Wukong aims to benchmark different multi-modal pre-training methods to facilitate the VLP research and community development. Furthermore, we release a group of models pre-trained with various image encoders (ViT-B/ViT-L/SwinT) and also apply advanced pre-training techniques into VLP such as locked-image text tuning, token-wise similarity in contrastive learning, and reduced-token interaction. Extensive experiments and a deep benchmarking of different downstream tasks are also provided. Experiments show that Wukong can serve as a promising Chinese pre-training dataset and benchmark for different cross-modal learning methods. For the zero-shot image classification task on 10 datasets, our model achieves an average accuracy of 73.03%. For the image-text retrieval task,our model achieves a mean recall of 71.6% on AIC-ICC which is 12.9% higher than the result of WenLan 2.0. More information can refer to https://wukong-dataset.github.io/wukong-dataset/.
GhostNets on Heterogeneous Devices via Cheap Operations
Jan 10, 2022
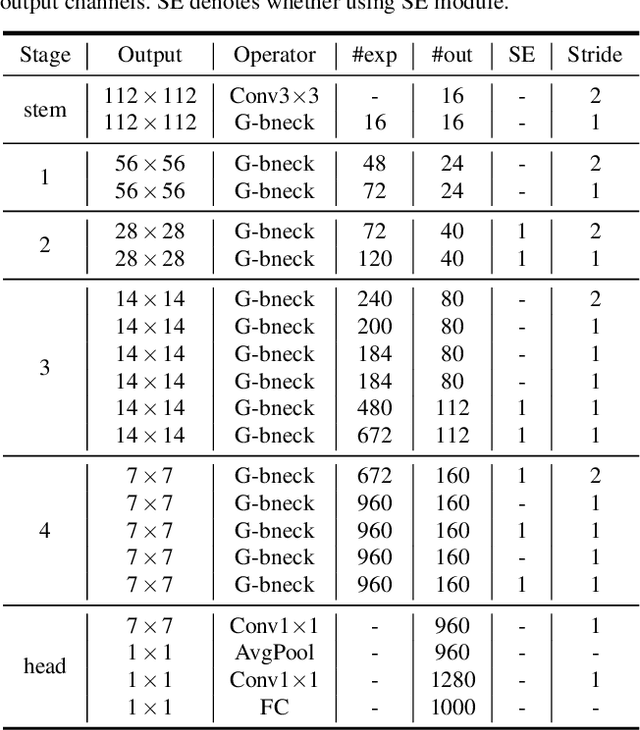
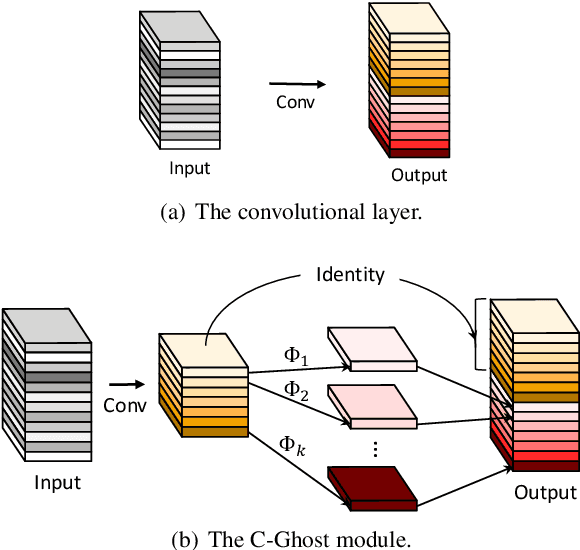
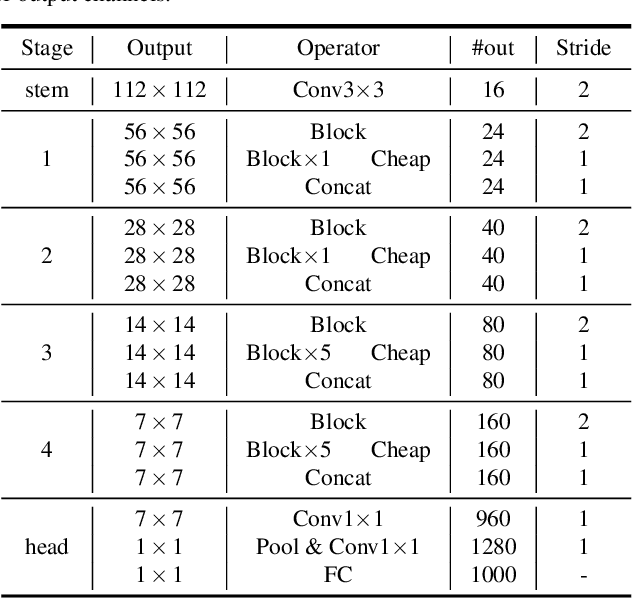
Deploying convolutional neural networks (CNNs) on mobile devices is difficult due to the limited memory and computation resources. We aim to design efficient neural networks for heterogeneous devices including CPU and GPU, by exploiting the redundancy in feature maps, which has rarely been investigated in neural architecture design. For CPU-like devices, we propose a novel CPU-efficient Ghost (C-Ghost) module to generate more feature maps from cheap operations. Based on a set of intrinsic feature maps, we apply a series of linear transformations with cheap cost to generate many ghost feature maps that could fully reveal information underlying intrinsic features. The proposed C-Ghost module can be taken as a plug-and-play component to upgrade existing convolutional neural networks. C-Ghost bottlenecks are designed to stack C-Ghost modules, and then the lightweight C-GhostNet can be easily established. We further consider the efficient networks for GPU devices. Without involving too many GPU-inefficient operations (e.g.,, depth-wise convolution) in a building stage, we propose to utilize the stage-wise feature redundancy to formulate GPU-efficient Ghost (G-Ghost) stage structure. The features in a stage are split into two parts where the first part is processed using the original block with fewer output channels for generating intrinsic features, and the other are generated using cheap operations by exploiting stage-wise redundancy. Experiments conducted on benchmarks demonstrate the effectiveness of the proposed C-Ghost module and the G-Ghost stage. C-GhostNet and G-GhostNet can achieve the optimal trade-off of accuracy and latency for CPU and GPU, respectively. Code is available at https://github.com/huawei-noah/CV-Backbones.
An Empirical Study of Adder Neural Networks for Object Detection
Dec 27, 2021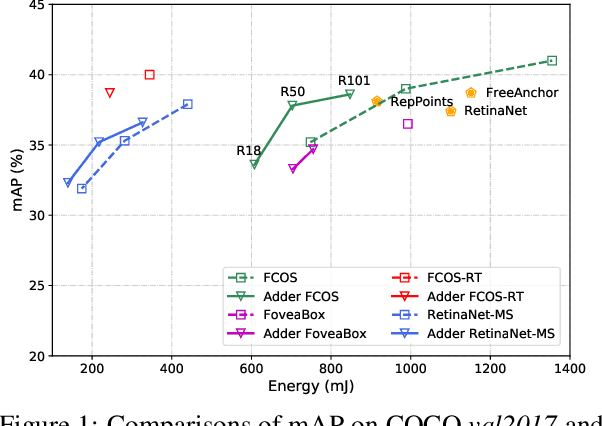
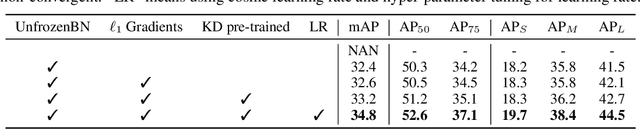
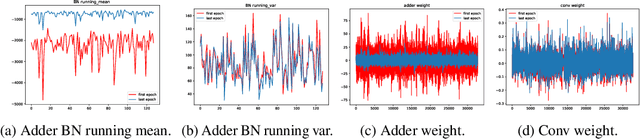
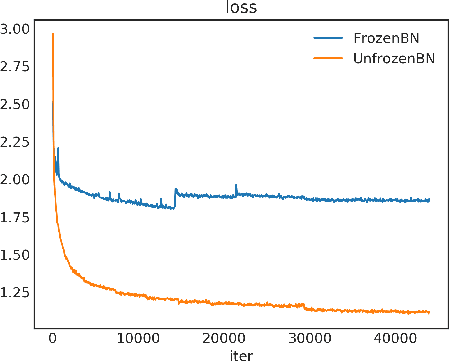
Adder neural networks (AdderNets) have shown impressive performance on image classification with only addition operations, which are more energy efficient than traditional convolutional neural networks built with multiplications. Compared with classification, there is a strong demand on reducing the energy consumption of modern object detectors via AdderNets for real-world applications such as autonomous driving and face detection. In this paper, we present an empirical study of AdderNets for object detection. We first reveal that the batch normalization statistics in the pre-trained adder backbone should not be frozen, since the relatively large feature variance of AdderNets. Moreover, we insert more shortcut connections in the neck part and design a new feature fusion architecture for avoiding the sparse features of adder layers. We present extensive ablation studies to explore several design choices of adder detectors. Comparisons with state-of-the-arts are conducted on COCO and PASCAL VOC benchmarks. Specifically, the proposed Adder FCOS achieves a 37.8\% AP on the COCO val set, demonstrating comparable performance to that of the convolutional counterpart with an about $1.4\times$ energy reduction.
FILIP: Fine-grained Interactive Language-Image Pre-Training
Nov 09, 2021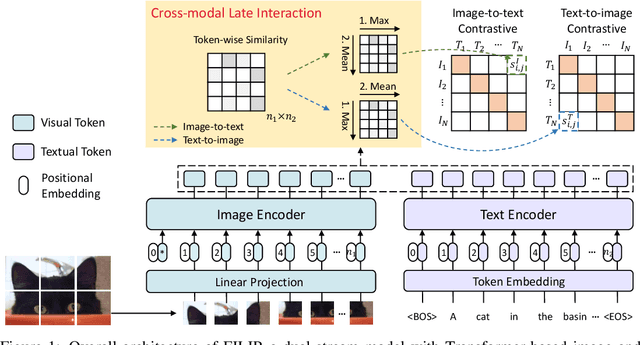
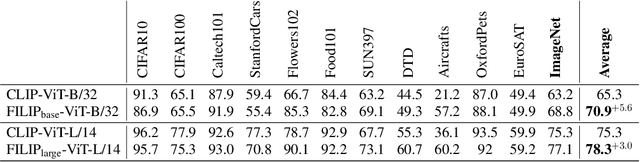
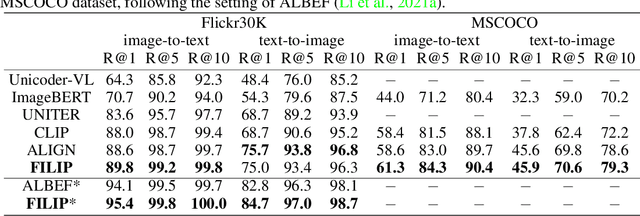

Unsupervised large-scale vision-language pre-training has shown promising advances on various downstream tasks. Existing methods often model the cross-modal interaction either via the similarity of the global feature of each modality which misses sufficient information, or finer-grained interactions using cross/self-attention upon visual and textual tokens. However, cross/self-attention suffers from inferior efficiency in both training and inference. In this paper, we introduce a large-scale Fine-grained Interactive Language-Image Pre-training (FILIP) to achieve finer-level alignment through a cross-modal late interaction mechanism, which uses a token-wise maximum similarity between visual and textual tokens to guide the contrastive objective. FILIP successfully leverages the finer-grained expressiveness between image patches and textual words by modifying only contrastive loss, while simultaneously gaining the ability to pre-compute image and text representations offline at inference, keeping both large-scale training and inference efficient. Furthermore, we construct a new large-scale image-text pair dataset called FILIP300M for pre-training. Experiments show that FILIP achieves state-of-the-art performance on multiple downstream vision-language tasks including zero-shot image classification and image-text retrieval. The visualization on word-patch alignment further shows that FILIP can learn meaningful fine-grained features with promising localization ability.
SOFT: Softmax-free Transformer with Linear Complexity
Oct 29, 2021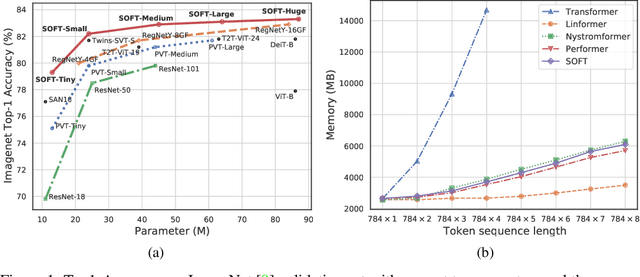
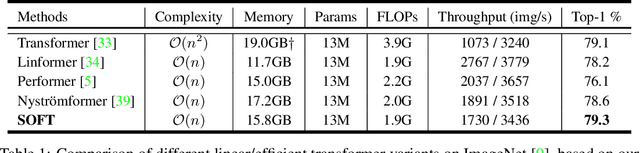
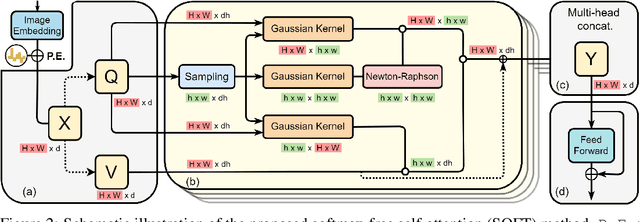
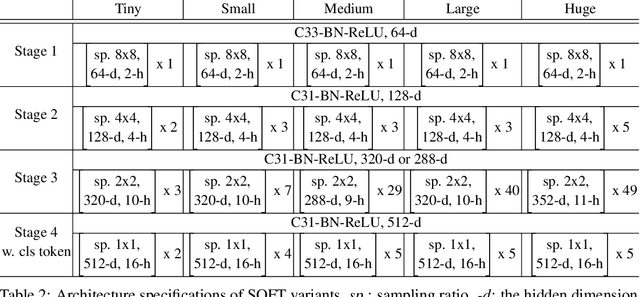
Vision transformers (ViTs) have pushed the state-of-the-art for various visual recognition tasks by patch-wise image tokenization followed by self-attention. However, the employment of self-attention modules results in a quadratic complexity in both computation and memory usage. Various attempts on approximating the self-attention computation with linear complexity have been made in Natural Language Processing. However, an in-depth analysis in this work shows that they are either theoretically flawed or empirically ineffective for visual recognition. We further identify that their limitations are rooted in keeping the softmax self-attention during approximations. Specifically, conventional self-attention is computed by normalizing the scaled dot-product between token feature vectors. Keeping this softmax operation challenges any subsequent linearization efforts. Based on this insight, for the first time, a softmax-free transformer or SOFT is proposed. To remove softmax in self-attention, Gaussian kernel function is used to replace the dot-product similarity without further normalization. This enables a full self-attention matrix to be approximated via a low-rank matrix decomposition. The robustness of the approximation is achieved by calculating its Moore-Penrose inverse using a Newton-Raphson method. Extensive experiments on ImageNet show that our SOFT significantly improves the computational efficiency of existing ViT variants. Crucially, with a linear complexity, much longer token sequences are permitted in SOFT, resulting in superior trade-off between accuracy and complexity.