 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMC-ITA: Sequential Monte Carlo Inference-Time Alignment for Video-to-Audio Generation
Jun 07, 2026Video-to-audio (V2A) generation must jointly satisfy audiovisual alignment, semantic consistency, temporal synchronization, and perceptual quality. While prior work has mainly focused on model architecture, multimodal conditioning, and training objectives, inference-time alignment for V2A remains underexplored. In this paper, we study inference-time alignment for flow-matching-based V2A generation and formulate it as a search problem. We propose Sequential Monte Carlo Inference-Time Alignment (SMC-ITA), which combines lookahead-based reward estimation and sequential Monte Carlo resampling to reallocate computation adaptively using multi-dimensional cross-modal rewards. SMC-ITA improves over naive single-trajectory sampling, achieving a 55.67% relative reduction in DeSync, a 20.23% improvement in IB-score, and a 15.44% improvement in Audio Quality. Under matched NFE budgets, it also achieves the best overall trade-off among the compared search baselines, outperforming Best-of-N and Beam Search. Ablation studies further show that lookahead improves the reliability of intermediate reward estimates and that systematic resampling is a strong practical default for V2A inference-time alignment.
Preserve, Reveal, Expand: Faithful 4D Video Editing with Region-Aware Conditioning
May 20, 2026Existing 4D-driven video diffusion models primarily target plausible generation, but faithful 4D editing requires preserving source-observed regions while synthesizing disoccluded or out-of-view content. We identify Evidence-Role Mismatch: reliable source-backed evidence, unreliable rendered cues, and unsupported regions are entangled in a single conditioning signal, causing preservation drift, ghosting, and unstable extrapolation. We propose PREX (Preserve, Reveal, Expand), a region-aware framework that decomposes the target spatiotemporal volume into Preserve, Reveal, and Expand roles according to observation support and scene extent. PREX builds observation-backed appearance cues with calibrated confidence and injects them into a frozen video diffusion backbone through a region-aware adapter, trained with proxy tasks without requiring paired edited videos. We further introduce PREBench, a diagnostic benchmark with curated edits, region-role masks, and human-aligned metrics that complement global video-quality and 4D-control evaluations. Experiments show that PREX reduces region-structured failures while maintaining strong visual quality and 4D edit control capability. Project Page: https://ricepastem.github.io/PREX-Open
MUSE: A Multi-agent Framework for Unconstrained Story Envisioning via Closed-Loop Cognitive Orchestration
Feb 03, 2026Generating long-form audio-visual stories from a short user prompt remains challenging due to an intent-execution gap, where high-level narrative intent must be preserved across coherent, shot-level multimodal generation over long horizons. Existing approaches typically rely on feed-forward pipelines or prompt-only refinement, which often leads to semantic drift and identity inconsistency as sequences grow longer. We address this challenge by formulating storytelling as a closed-loop constraint enforcement problem and propose MUSE, a multi-agent framework that coordinates generation through an iterative plan-execute-verify-revise loop. MUSE translates narrative intent into explicit, machine-executable controls over identity, spatial composition, and temporal continuity, and applies targeted multimodal feedback to correct violations during generation. To evaluate open-ended storytelling without ground-truth references, we introduce MUSEBench, a reference-free evaluation protocol validated by human judgments. Experiments demonstrate that MUSE substantially improves long-horizon narrative coherence, cross-modal identity consistency, and cinematic quality compared with representative baselines.
Mega-TTS 2: Zero-Shot Text-to-Speech with Arbitrary Length Speech Prompts
Jul 14, 2023



Zero-shot text-to-speech aims at synthesizing voices with unseen speech prompts. Previous large-scale multispeaker TTS models have successfully achieved this goal with an enrolled recording within 10 seconds. However, most of them are designed to utilize only short speech prompts. The limited information in short speech prompts significantly hinders the performance of fine-grained identity imitation. In this paper, we introduce Mega-TTS 2, a generic zero-shot multispeaker TTS model that is capable of synthesizing speech for unseen speakers with arbitrary-length prompts. Specifically, we 1) design a multi-reference timbre encoder to extract timbre information from multiple reference speeches; 2) and train a prosody language model with arbitrary-length speech prompts; With these designs, our model is suitable for prompts of different lengths, which extends the upper bound of speech quality for zero-shot text-to-speech. Besides arbitrary-length prompts, we introduce arbitrary-source prompts, which leverages the probabilities derived from multiple P-LLM outputs to produce expressive and controlled prosody. Furthermore, we propose a phoneme-level auto-regressive duration model to introduce in-context learning capabilities to duration modeling. Experiments demonstrate that our method could not only synthesize identity-preserving speech with a short prompt of an unseen speaker but also achieve improved performance with longer speech prompts. Audio samples can be found in https://mega-tts.github.io/mega2_demo/.
GenerTTS: Pronunciation Disentanglement for Timbre and Style Generalization in Cross-Lingual Text-to-Speech
Jun 27, 2023



Cross-lingual timbre and style generalizable text-to-speech (TTS) aims to synthesize speech with a specific reference timbre or style that is never trained in the target language. It encounters the following challenges: 1) timbre and pronunciation are correlated since multilingual speech of a specific speaker is usually hard to obtain; 2) style and pronunciation are mixed because the speech style contains language-agnostic and language-specific parts. To address these challenges, we propose GenerTTS, which mainly includes the following works: 1) we elaborately design a HuBERT-based information bottleneck to disentangle timbre and pronunciation/style; 2) we minimize the mutual information between style and language to discard the language-specific information in the style embedding. The experiments indicate that GenerTTS outperforms baseline systems in terms of style similarity and pronunciation accuracy, and enables cross-lingual timbre and style generalization.
Mega-TTS: Zero-Shot Text-to-Speech at Scale with Intrinsic Inductive Bias
Jun 06, 2023Scaling text-to-speech to a large and wild dataset has been proven to be highly effective in achieving timbre and speech style generalization, particularly in zero-shot TTS. However, previous works usually encode speech into latent using audio codec and use autoregressive language models or diffusion models to generate it, which ignores the intrinsic nature of speech and may lead to inferior or uncontrollable results. We argue that speech can be decomposed into several attributes (e.g., content, timbre, prosody, and phase) and each of them should be modeled using a module with appropriate inductive biases. From this perspective, we carefully design a novel and large zero-shot TTS system called Mega-TTS, which is trained with large-scale wild data and models different attributes in different ways: 1) Instead of using latent encoded by audio codec as the intermediate feature, we still choose spectrogram as it separates the phase and other attributes very well. Phase can be appropriately constructed by the GAN-based vocoder and does not need to be modeled by the language model. 2) We model the timbre using global vectors since timbre is a global attribute that changes slowly over time. 3) We further use a VQGAN-based acoustic model to generate the spectrogram and a latent code language model to fit the distribution of prosody, since prosody changes quickly over time in a sentence, and language models can capture both local and long-range dependencies. We scale Mega-TTS to multi-domain datasets with 20K hours of speech and evaluate its performance on unseen speakers. Experimental results demonstrate that Mega-TTS surpasses state-of-the-art TTS systems on zero-shot TTS, speech editing, and cross-lingual TTS tasks, with superior naturalness, robustness, and speaker similarity due to the proper inductive bias of each module. Audio samples are available at https://mega-tts.github.io/demo-page.
StyleS2ST: Zero-shot Style Transfer for Direct Speech-to-speech Translation
Jun 01, 2023Direct speech-to-speech translation (S2ST) has gradually become popular as it has many advantages compared with cascade S2ST. However, current research mainly focuses on the accuracy of semantic translation and ignores the speech style transfer from a source language to a target language. The lack of high-fidelity expressive parallel data makes such style transfer challenging, especially in more practical zero-shot scenarios. To solve this problem, we first build a parallel corpus using a multi-lingual multi-speaker text-to-speech synthesis (TTS) system and then propose the StyleS2ST model with cross-lingual speech style transfer ability based on a style adaptor on a direct S2ST system framework. Enabling continuous style space modeling of an acoustic model through parallel corpus training and non-parallel TTS data augmentation, StyleS2ST captures cross-lingual acoustic feature mapping from the source to the target language. Experiments show that StyleS2ST achieves good style similarity and naturalness in both in-set and out-of-set zero-shot scenarios.
LiteG2P: A fast, light and high accuracy model for grapheme-to-phoneme conversion
Mar 02, 2023



As a key component of automated speech recognition (ASR) and the front-end in text-to-speech (TTS), grapheme-to-phoneme (G2P) plays the role of converting letters to their corresponding pronunciations. Existing methods are either slow or poor in performance, and are limited in application scenarios, particularly in the process of on-device inference. In this paper, we integrate the advantages of both expert knowledge and connectionist temporal classification (CTC) based neural network and propose a novel method named LiteG2P which is fast, light and theoretically parallel. With the carefully leading design, LiteG2P can be applied both on cloud and on device. Experimental results on the CMU dataset show that the performance of the proposed method is superior to the state-of-the-art CTC based method with 10 times fewer parameters, and even comparable to the state-of-the-art Transformer-based sequence-to-sequence model with less parameters and 33 times less computation.
Overcoming Classifier Imbalance for Long-tail Object Detection with Balanced Group Softmax
Jun 18, 2020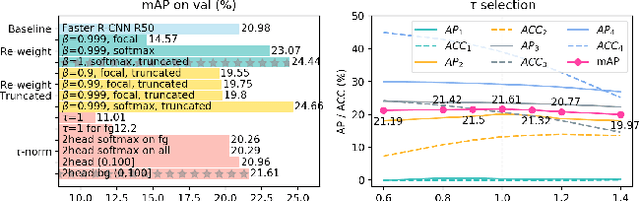
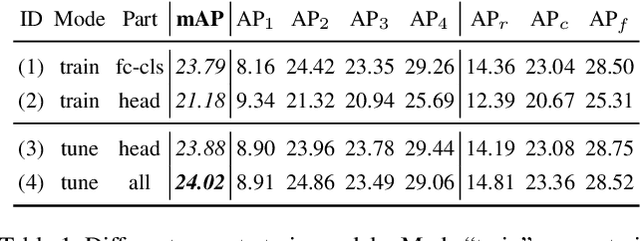
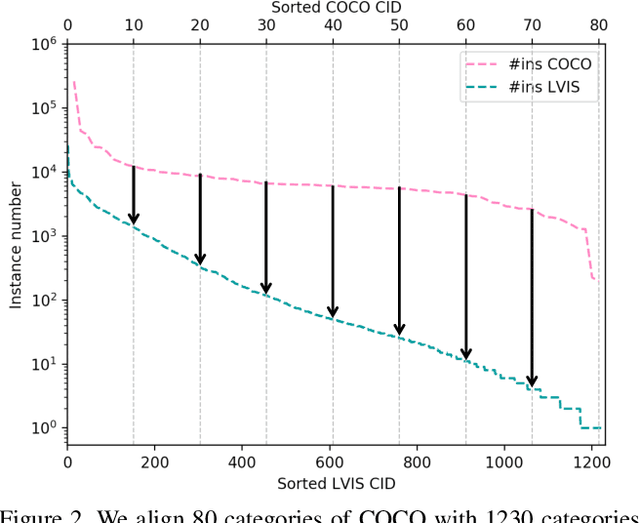
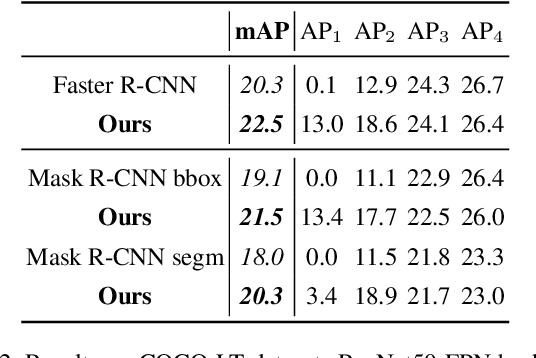
Solving long-tail large vocabulary object detection with deep learning based models is a challenging and demanding task, which is however under-explored.In this work, we provide the first systematic analysis on the underperformance of state-of-the-art models in front of long-tail distribution. We find existing detection methods are unable to model few-shot classes when the dataset is extremely skewed, which can result in classifier imbalance in terms of parameter magnitude. Directly adapting long-tail classification models to detection frameworks can not solve this problem due to the intrinsic difference between detection and classification.In this work, we propose a novel balanced group softmax (BAGS) module for balancing the classifiers within the detection frameworks through group-wise training. It implicitly modulates the training process for the head and tail classes and ensures they are both sufficiently trained, without requiring any extra sampling for the instances from the tail classes.Extensive experiments on the very recent long-tail large vocabulary object recognition benchmark LVIS show that our proposed BAGS significantly improves the performance of detectors with various backbones and frameworks on both object detection and instance segmentation. It beats all state-of-the-art methods transferred from long-tail image classification and establishes new state-of-the-art.Code is available at https://github.com/FishYuLi/BalancedGroupSoftmax.