 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudent Mental Health Screening via Fitbit Data Collected During the COVID-19 Pandemic
Jan 22, 2026College students experience many stressors, resulting in high levels of anxiety and depression. Wearable technology provides unobtrusive sensor data that can be used for the early detection of mental illness. However, current research is limited concerning the variety of psychological instruments administered, physiological modalities, and time series parameters. In this research, we collect the Student Mental and Environmental Health (StudentMEH) Fitbit dataset from students at our institution during the pandemic. We provide a comprehensive assessment of the ability of predictive machine learning models to screen for depression, anxiety, and stress using different Fitbit modalities. Our findings indicate potential in physiological modalities such as heart rate and sleep to screen for mental illness with the F1 scores as high as 0.79 for anxiety, the former modality reaching 0.77 for stress screening, and the latter modality achieving 0.78 for depression. This research highlights the potential of wearable devices to support continuous mental health monitoring, the importance of identifying best data aggregation levels and appropriate modalities for screening for different mental ailments.
The Impact of Generative AI on Architectural Conceptual Design: Performance, Creative Self-Efficacy and Cognitive Load
Jan 15, 2026Our study examines how generative AI (GenAI) influences performance, creative self-efficacy, and cognitive load in architectural conceptual design tasks. Thirty-six student participants from Architectural Engineering and other disciplines completed a two-phase architectural design task, first independently and then with external tools (GenAI-assisted condition and control condition using an online repository of existing architectural projects). Design outcomes were evaluated by expert raters, while self-efficacy and cognitive load were self-reported after each phase. Difference-in-differences analyses revealed no overall performance advantage of GenAI across participants; however, subgroup analyses showed that GenAI significantly improved design performance for novice designers. In contrast, general creative self-efficacy declined for students using GenAI. Cognitive load did not differ significantly between conditions, though prompt usage patterns showed that iterative idea generation and visual feedback prompts were linked to greater reductions in cognitive load. These findings suggest that GenAI effectiveness depends on users' prior expertise and interaction strategies through prompting.
PromptExp: Multi-granularity Prompt Explanation of Large Language Models
Oct 16, 2024



Large Language Models excel in tasks like natural language understanding and text generation. Prompt engineering plays a critical role in leveraging LLM effectively. However, LLMs black-box nature hinders its interpretability and effective prompting engineering. A wide range of model explanation approaches have been developed for deep learning models, However, these local explanations are designed for single-output tasks like classification and regression,and cannot be directly applied to LLMs, which generate sequences of tokens. Recent efforts in LLM explanation focus on natural language explanations, but they are prone to hallucinations and inaccuracies. To address this, we introduce OurTool, a framework for multi-granularity prompt explanations by aggregating token-level insights. OurTool introduces two token-level explanation approaches: 1.an aggregation-based approach combining local explanation techniques, and 2. a perturbation-based approach with novel techniques to evaluate token masking impact. OurTool supports both white-box and black-box explanations and extends explanations to higher granularity levels, enabling flexible analysis. We evaluate OurTool in case studies such as sentiment analysis, showing the perturbation-based approach performs best using semantic similarity to assess perturbation impact. Furthermore, we conducted a user study to confirm OurTool's accuracy and practical value, and demonstrate its potential to enhance LLM interpretability.
Adapting Differential Molecular Representation with Hierarchical Prompts for Multi-label Property Prediction
May 29, 2024



Accurate prediction of molecular properties is critical in the field of drug discovery. However, existing methods do not fully consider the fact that molecules in the real world usually possess multiple property labels, and complex high-order relationships may exist among these labels. Therefore, molecular representation learning models should generate differential molecular representations that consider multi-granularity correlation information among tasks. To this end, our research introduces a Hierarchical Prompted Molecular Representation Learning Framework (HiPM), which enhances the differential expression of tasks in molecular representations through task-aware prompts, and utilizes shared information among labels to mitigate negative transfer between different tasks. HiPM primarily consists of two core components: the Molecular Representation Encoder (MRE) and the Task-Aware Prompter (TAP). The MRE employs a hierarchical message-passing network architecture to capture molecular features at both the atomic and motif levels, while the TAP uses agglomerative hierarchical clustering to build a prompt tree that reflects the affinity and distinctiveness of tasks, enabling the model to effectively handle the complexity of multi-label property predictions. Extensive experiments demonstrate that HiPM achieves state-of-the-art performance across various multi-label datasets, offering a new perspective on multi-label molecular representation learning.
GenerTTS: Pronunciation Disentanglement for Timbre and Style Generalization in Cross-Lingual Text-to-Speech
Jun 27, 2023



Cross-lingual timbre and style generalizable text-to-speech (TTS) aims to synthesize speech with a specific reference timbre or style that is never trained in the target language. It encounters the following challenges: 1) timbre and pronunciation are correlated since multilingual speech of a specific speaker is usually hard to obtain; 2) style and pronunciation are mixed because the speech style contains language-agnostic and language-specific parts. To address these challenges, we propose GenerTTS, which mainly includes the following works: 1) we elaborately design a HuBERT-based information bottleneck to disentangle timbre and pronunciation/style; 2) we minimize the mutual information between style and language to discard the language-specific information in the style embedding. The experiments indicate that GenerTTS outperforms baseline systems in terms of style similarity and pronunciation accuracy, and enables cross-lingual timbre and style generalization.
LiteG2P: A fast, light and high accuracy model for grapheme-to-phoneme conversion
Mar 02, 2023



As a key component of automated speech recognition (ASR) and the front-end in text-to-speech (TTS), grapheme-to-phoneme (G2P) plays the role of converting letters to their corresponding pronunciations. Existing methods are either slow or poor in performance, and are limited in application scenarios, particularly in the process of on-device inference. In this paper, we integrate the advantages of both expert knowledge and connectionist temporal classification (CTC) based neural network and propose a novel method named LiteG2P which is fast, light and theoretically parallel. With the carefully leading design, LiteG2P can be applied both on cloud and on device. Experimental results on the CMU dataset show that the performance of the proposed method is superior to the state-of-the-art CTC based method with 10 times fewer parameters, and even comparable to the state-of-the-art Transformer-based sequence-to-sequence model with less parameters and 33 times less computation.
Hierarchical Graph Representation Learning for the Prediction of Drug-Target Binding Affinity
Mar 22, 2022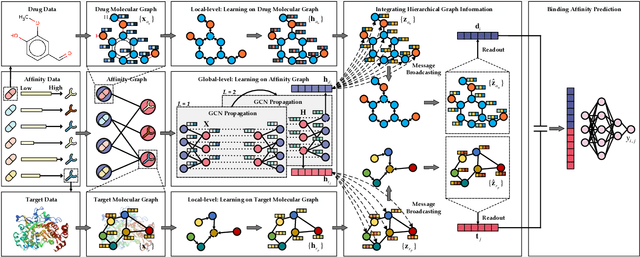
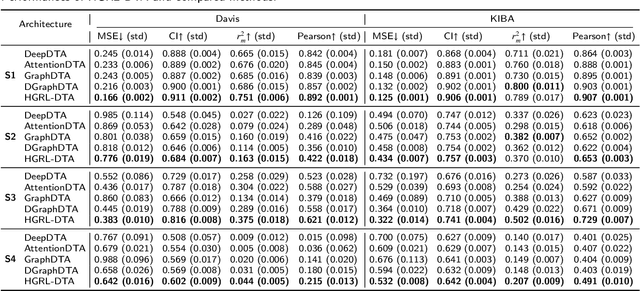
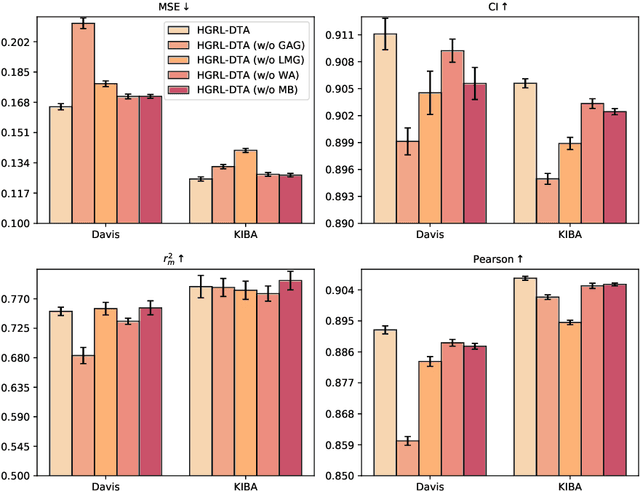
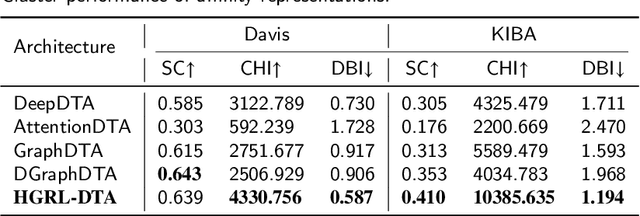
The identification of drug-target binding affinity (DTA) has attracted increasing attention in the drug discovery process due to the more specific interpretation than binary interaction prediction. Recently, numerous deep learning-based computational methods have been proposed to predict the binding affinities between drugs and targets benefiting from their satisfactory performance. However, the previous works mainly focus on encoding biological features and chemical structures of drugs and targets, with a lack of exploiting the essential topological information from the drug-target affinity network. In this paper, we propose a novel hierarchical graph representation learning model for the drug-target binding affinity prediction, namely HGRL-DTA. The main contribution of our model is to establish a hierarchical graph learning architecture to incorporate the intrinsic properties of drug/target molecules and the topological affinities of drug-target pairs. In this architecture, we adopt a message broadcasting mechanism to integrate the hierarchical representations learned from the global-level affinity graph and the local-level molecular graph. Besides, we design a similarity-based embedding map to solve the cold start problem of inferring representations for unseen drugs and targets. Comprehensive experimental results under different scenarios indicate that HGRL-DTA significantly outperforms the state-of-the-art models and shows better model generalization among all the scenarios.
2nd Place Solution for IJCAI-PRICAI 2020 3D AI Challenge: 3D Object Reconstruction from A Single Image
May 28, 2021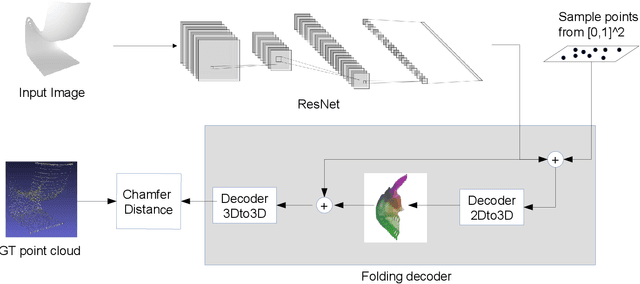



In this paper, we present our solution for the {\it IJCAI--PRICAI--20 3D AI Challenge: 3D Object Reconstruction from A Single Image}. We develop a variant of AtlasNet that consumes single 2D images and generates 3D point clouds through 2D to 3D mapping. To push the performance to the limit and present guidance on crucial implementation choices, we conduct extensive experiments to analyze the influence of decoder design and different settings on the normalization, projection, and sampling methods. Our method achieves 2nd place in the final track with a score of $70.88$, a chamfer distance of $36.87$, and a mean f-score of $59.18$. The source code of our method will be available at https://github.com/em-data/Enhanced_AtlasNet_3DReconstruction.
* 5 pages, 2 figures, 5 tables
A hybrid text normalization system using multi-head self-attention for mandarin
Nov 11, 2019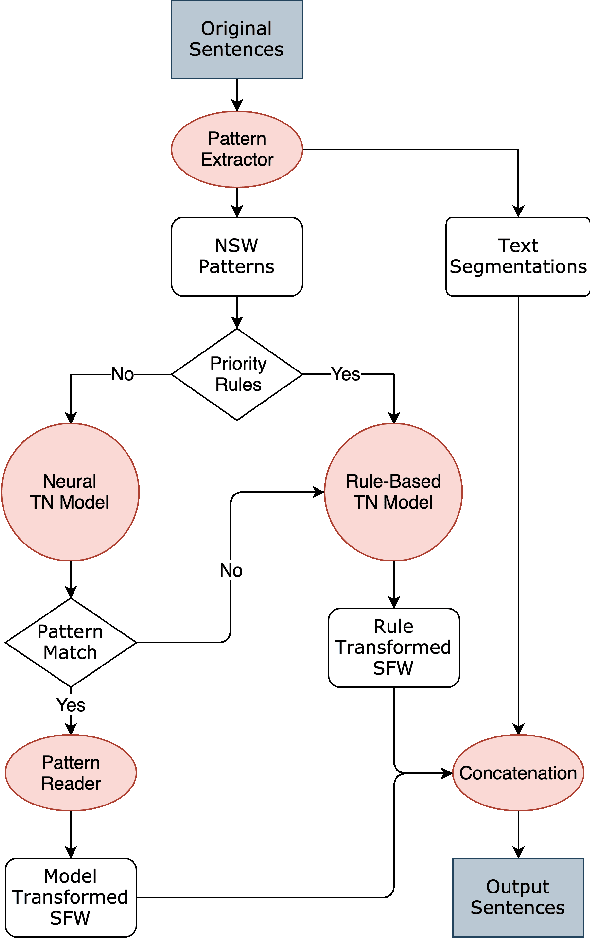
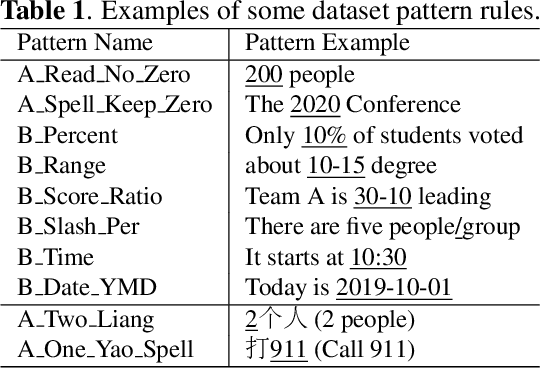
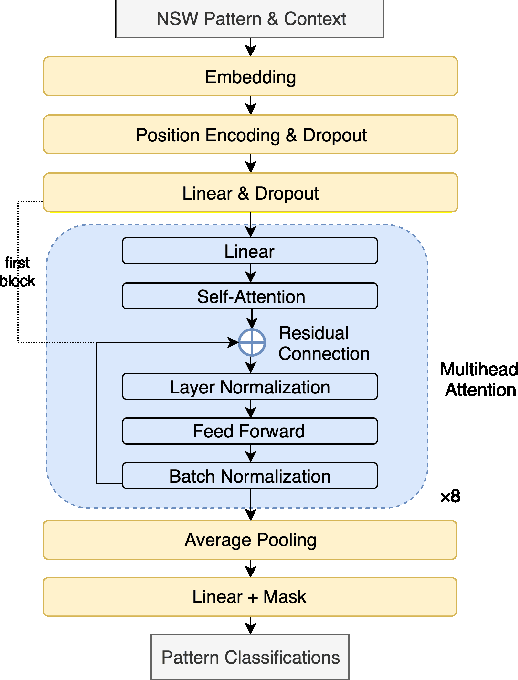
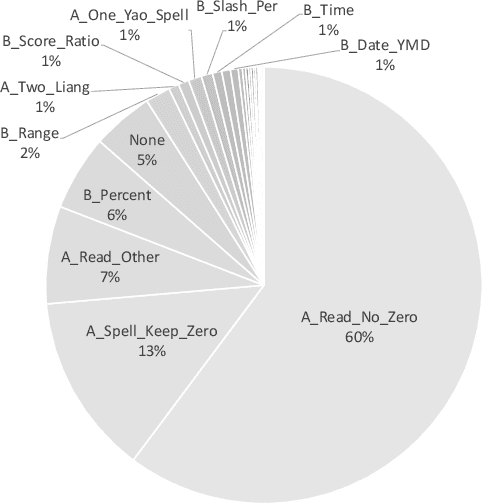
In this paper, we propose a hybrid text normalization system using multi-head self-attention. The system combines the advantages of a rule-based model and a neural model for text preprocessing tasks. Previous studies in Mandarin text normalization usually use a set of hand-written rules, which are hard to improve on general cases. The idea of our proposed system is motivated by the neural models from recent studies and has a better performance on our internal news corpus. This paper also includes different attempts to deal with imbalanced pattern distribution of the dataset. Overall, the performance of the system is improved by over 1.5% on sentence-level and it has a potential to improve further.
A unified sequence-to-sequence front-end model for Mandarin text-to-speech synthesis
Nov 11, 2019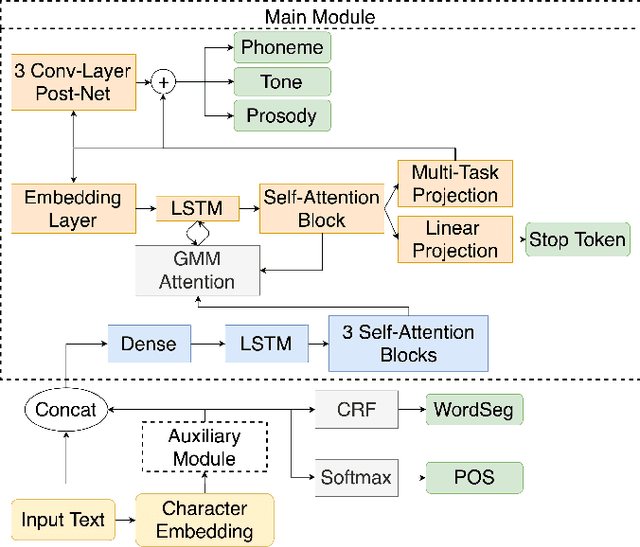

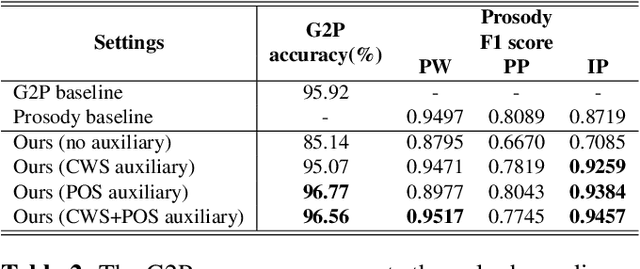
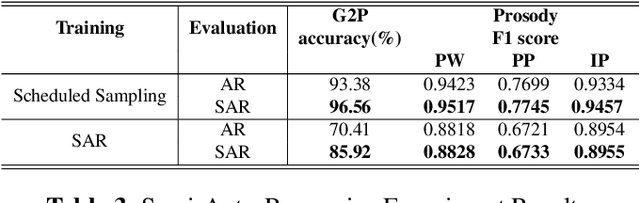
In Mandarin text-to-speech (TTS) system, the front-end text processing module significantly influences the intelligibility and naturalness of synthesized speech. Building a typical pipeline-based front-end which consists of multiple individual components requires extensive efforts. In this paper, we proposed a unified sequence-to-sequence front-end model for Mandarin TTS that converts raw texts to linguistic features directly. Compared to the pipeline-based front-end, our unified front-end can achieve comparable performance in polyphone disambiguation and prosody word prediction, and improve intonation phrase prediction by 0.0738 in F1 score. We also implemented the unified front-end with Tacotron and WaveRNN to build a Mandarin TTS system. The synthesized speech by that got a comparable MOS (4.38) with the pipeline-based front-end (4.37) and close to human recordings (4.49).