 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Semantic Features: Pixel-level Mapping for Generalized AI-Generated Image Detection
Dec 19, 2025



The rapid evolution of generative technologies necessitates reliable methods for detecting AI-generated images. A critical limitation of current detectors is their failure to generalize to images from unseen generative models, as they often overfit to source-specific semantic cues rather than learning universal generative artifacts. To overcome this, we introduce a simple yet remarkably effective pixel-level mapping pre-processing step to disrupt the pixel value distribution of images and break the fragile, non-essential semantic patterns that detectors commonly exploit as shortcuts. This forces the detector to focus on more fundamental and generalizable high-frequency traces inherent to the image generation process. Through comprehensive experiments on GAN and diffusion-based generators, we show that our approach significantly boosts the cross-generator performance of state-of-the-art detectors. Extensive analysis further verifies our hypothesis that the disruption of semantic cues is the key to generalization.
Quality-Diversity Red-Teaming: Automated Generation of High-Quality and Diverse Attackers for Large Language Models
Jun 08, 2025Ensuring safety of large language models (LLMs) is important. Red teaming--a systematic approach to identifying adversarial prompts that elicit harmful responses from target LLMs--has emerged as a crucial safety evaluation method. Within this framework, the diversity of adversarial prompts is essential for comprehensive safety assessments. We find that previous approaches to red-teaming may suffer from two key limitations. First, they often pursue diversity through simplistic metrics like word frequency or sentence embedding similarity, which may not capture meaningful variation in attack strategies. Second, the common practice of training a single attacker model restricts coverage across potential attack styles and risk categories. This paper introduces Quality-Diversity Red-Teaming (QDRT), a new framework designed to address these limitations. QDRT achieves goal-driven diversity through behavior-conditioned training and implements a behavioral replay buffer in an open-ended manner. Additionally, it trains multiple specialized attackers capable of generating high-quality attacks across diverse styles and risk categories. Our empirical evaluation demonstrates that QDRT generates attacks that are both more diverse and more effective against a wide range of target LLMs, including GPT-2, Llama-3, Gemma-2, and Qwen2.5. This work advances the field of LLM safety by providing a systematic and effective approach to automated red-teaming, ultimately supporting the responsible deployment of LLMs.
Attend to Not Attended: Structure-then-Detail Token Merging for Post-training DiT Acceleration
May 16, 2025Diffusion transformers have shown exceptional performance in visual generation but incur high computational costs. Token reduction techniques that compress models by sharing the denoising process among similar tokens have been introduced. However, existing approaches neglect the denoising priors of the diffusion models, leading to suboptimal acceleration and diminished image quality. This study proposes a novel concept: attend to prune feature redundancies in areas not attended by the diffusion process. We analyze the location and degree of feature redundancies based on the structure-then-detail denoising priors. Subsequently, we introduce SDTM, a structure-then-detail token merging approach that dynamically compresses feature redundancies. Specifically, we design dynamic visual token merging, compression ratio adjusting, and prompt reweighting for different stages. Served in a post-training way, the proposed method can be integrated seamlessly into any DiT architecture. Extensive experiments across various backbones, schedulers, and datasets showcase the superiority of our method, for example, it achieves 1.55 times acceleration with negligible impact on image quality. Project page: https://github.com/ICTMCG/SDTM.
Learning Monocular Depth from Events via Egomotion Compensation
Dec 26, 2024Event cameras are neuromorphically inspired sensors that sparsely and asynchronously report brightness changes. Their unique characteristics of high temporal resolution, high dynamic range, and low power consumption make them well-suited for addressing challenges in monocular depth estimation (e.g., high-speed or low-lighting conditions). However, current existing methods primarily treat event streams as black-box learning systems without incorporating prior physical principles, thus becoming over-parameterized and failing to fully exploit the rich temporal information inherent in event camera data. To address this limitation, we incorporate physical motion principles to propose an interpretable monocular depth estimation framework, where the likelihood of various depth hypotheses is explicitly determined by the effect of motion compensation. To achieve this, we propose a Focus Cost Discrimination (FCD) module that measures the clarity of edges as an essential indicator of focus level and integrates spatial surroundings to facilitate cost estimation. Furthermore, we analyze the noise patterns within our framework and improve it with the newly introduced Inter-Hypotheses Cost Aggregation (IHCA) module, where the cost volume is refined through cost trend prediction and multi-scale cost consistency constraints. Extensive experiments on real-world and synthetic datasets demonstrate that our proposed framework outperforms cutting-edge methods by up to 10\% in terms of the absolute relative error metric, revealing superior performance in predicting accuracy.
DragEntity: Trajectory Guided Video Generation using Entity and Positional Relationships
Oct 14, 2024In recent years, diffusion models have achieved tremendous success in the field of video generation, with controllable video generation receiving significant attention. However, existing control methods still face two limitations: Firstly, control conditions (such as depth maps, 3D Mesh) are difficult for ordinary users to obtain directly. Secondly, it's challenging to drive multiple objects through complex motions with multiple trajectories simultaneously. In this paper, we introduce DragEntity, a video generation model that utilizes entity representation for controlling the motion of multiple objects. Compared to previous methods, DragEntity offers two main advantages: 1) Our method is more user-friendly for interaction because it allows users to drag entities within the image rather than individual pixels. 2) We use entity representation to represent any object in the image, and multiple objects can maintain relative spatial relationships. Therefore, we allow multiple trajectories to control multiple objects in the image with different levels of complexity simultaneously. Our experiments validate the effectiveness of DragEntity, demonstrating its excellent performance in fine-grained control in video generation.
Topology-Preserving Adversarial Training
Nov 29, 2023



Despite the effectiveness in improving the robustness of neural networks, adversarial training has suffered from the natural accuracy degradation problem, i.e., accuracy on natural samples has reduced significantly. In this study, we reveal that natural accuracy degradation is highly related to the disruption of the natural sample topology in the representation space by quantitative and qualitative experiments. Based on this observation, we propose Topology-pReserving Adversarial traINing (TRAIN) to alleviate the problem by preserving the topology structure of natural samples from a standard model trained only on natural samples during adversarial training. As an additional regularization, our method can easily be combined with various popular adversarial training algorithms in a plug-and-play manner, taking advantage of both sides. Extensive experiments on CIFAR-10, CIFAR-100, and Tiny ImageNet show that our proposed method achieves consistent and significant improvements over various strong baselines in most cases. Specifically, without additional data, our proposed method achieves up to 8.78% improvement in natural accuracy and 4.50% improvement in robust accuracy.
Dance Your Latents: Consistent Dance Generation through Spatial-temporal Subspace Attention Guided by Motion Flow
Oct 20, 2023



The advancement of generative AI has extended to the realm of Human Dance Generation, demonstrating superior generative capacities. However, current methods still exhibit deficiencies in achieving spatiotemporal consistency, resulting in artifacts like ghosting, flickering, and incoherent motions. In this paper, we present Dance-Your-Latents, a framework that makes latents dance coherently following motion flow to generate consistent dance videos. Firstly, considering that each constituent element moves within a confined space, we introduce spatial-temporal subspace-attention blocks that decompose the global space into a combination of regular subspaces and efficiently model the spatiotemporal consistency within these subspaces. This module enables each patch pay attention to adjacent areas, mitigating the excessive dispersion of long-range attention. Furthermore, observing that body part's movement is guided by pose control, we design motion flow guided subspace align & restore. This method enables the attention to be computed on the irregular subspace along the motion flow. Experimental results in TikTok dataset demonstrate that our approach significantly enhances spatiotemporal consistency of the generated videos.
Progressive Open Space Expansion for Open-Set Model Attribution
Mar 13, 2023Despite the remarkable progress in generative technology, the Janus-faced issues of intellectual property protection and malicious content supervision have arisen. Efforts have been paid to manage synthetic images by attributing them to a set of potential source models. However, the closed-set classification setting limits the application in real-world scenarios for handling contents generated by arbitrary models. In this study, we focus on a challenging task, namely Open-Set Model Attribution (OSMA), to simultaneously attribute images to known models and identify those from unknown ones. Compared to existing open-set recognition (OSR) tasks focusing on semantic novelty, OSMA is more challenging as the distinction between images from known and unknown models may only lie in visually imperceptible traces. To this end, we propose a Progressive Open Space Expansion (POSE) solution, which simulates open-set samples that maintain the same semantics as closed-set samples but embedded with different imperceptible traces. Guided by a diversity constraint, the open space is simulated progressively by a set of lightweight augmentation models. We consider three real-world scenarios and construct an OSMA benchmark dataset, including unknown models trained with different random seeds, architectures, and datasets from known ones. Extensive experiments on the dataset demonstrate POSE is superior to both existing model attribution methods and off-the-shelf OSR methods.
Learning to Disentangle GAN Fingerprint for Fake Image Attribution
Jun 16, 2021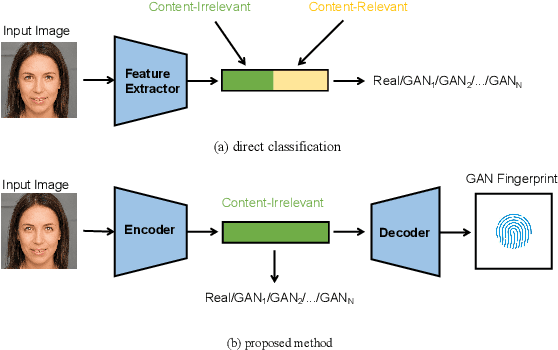
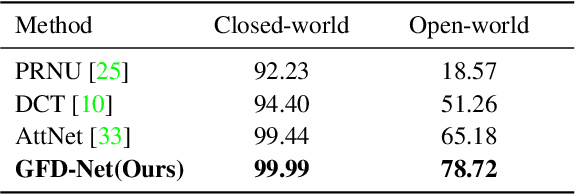
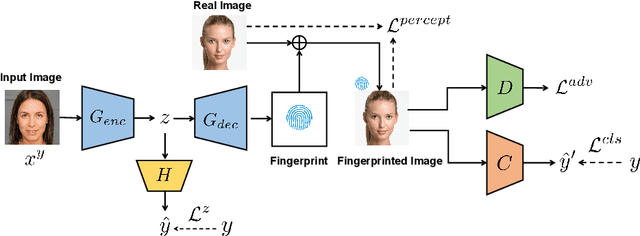

Rapid pace of generative models has brought about new threats to visual forensics such as malicious personation and digital copyright infringement, which promotes works on fake image attribution. Existing works on fake image attribution mainly rely on a direct classification framework. Without additional supervision, the extracted features could include many content-relevant components and generalize poorly. Meanwhile, how to obtain an interpretable GAN fingerprint to explain the decision remains an open question. Adopting a multi-task framework, we propose a GAN Fingerprint Disentangling Network (GFD-Net) to simultaneously disentangle the fingerprint from GAN-generated images and produce a content-irrelevant representation for fake image attribution. A series of constraints are provided to guarantee the stability and discriminability of the fingerprint, which in turn helps content-irrelevant feature extraction. Further, we perform comprehensive analysis on GAN fingerprint, providing some clues about the properties of GAN fingerprint and which factors dominate the fingerprint in GAN architecture. Experiments show that our GFD-Net achieves superior fake image attribution performance in both closed-world and open-world testing. We also apply our method in binary fake image detection and exhibit a significant generalization ability on unseen generators.
The Devil is in Classification: A Simple Framework for Long-tail Instance Segmentation
Jul 31, 2020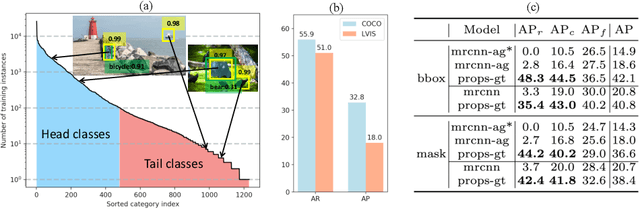

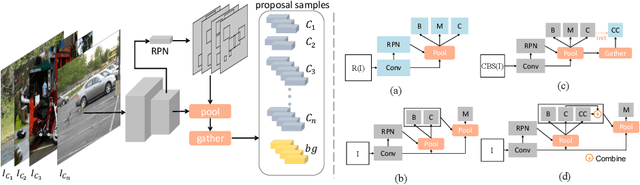
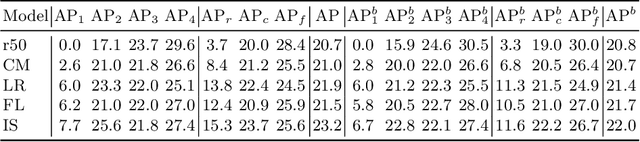
Most existing object instance detection and segmentation models only work well on fairly balanced benchmarks where per-category training sample numbers are comparable, such as COCO. They tend to suffer performance drop on realistic datasets that are usually long-tailed. This work aims to study and address such open challenges. Specifically, we systematically investigate performance drop of the state-of-the-art two-stage instance segmentation model Mask R-CNN on the recent long-tail LVIS dataset, and unveil that a major cause is the inaccurate classification of object proposals. Based on such an observation, we first consider various techniques for improving long-tail classification performance which indeed enhance instance segmentation results. We then propose a simple calibration framework to more effectively alleviate classification head bias with a bi-level class balanced sampling approach. Without bells and whistles, it significantly boosts the performance of instance segmentation for tail classes on the recent LVIS dataset and our sampled COCO-LT dataset. Our analysis provides useful insights for solving long-tail instance detection and segmentation problems, and the straightforward \emph{SimCal} method can serve as a simple but strong baseline. With the method we have won the 2019 LVIS challenge. Codes and models are available at \url{https://github.com/twangnh/SimCal}.