 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Latent Memory for Visual Multi-agent System
Jan 31, 2026While Visual Multi-Agent Systems (VMAS) promise to enhance comprehensive abilities through inter-agent collaboration, empirical evidence reveals a counter-intuitive "scaling wall": increasing agent turns often degrades performance while exponentially inflating token costs. We attribute this failure to the information bottleneck inherent in text-centric communication, where converting perceptual and thinking trajectories into discrete natural language inevitably induces semantic loss. To this end, we propose L$^{2}$-VMAS, a novel model-agnostic framework that enables inter-agent collaboration with dual latent memories. Furthermore, we decouple the perception and thinking while dynamically synthesizing dual latent memories. Additionally, we introduce an entropy-driven proactive triggering that replaces passive information transmission with efficient, on-demand memory access. Extensive experiments among backbones, sizes, and multi-agent structures demonstrate that our method effectively breaks the "scaling wall" with superb scalability, improving average accuracy by 2.7-5.4% while reducing token usage by 21.3-44.8%. Codes: https://github.com/YU-deep/L2-VMAS.
FFP-300K: Scaling First-Frame Propagation for Generalizable Video Editing
Jan 06, 2026First-Frame Propagation (FFP) offers a promising paradigm for controllable video editing, but existing methods are hampered by a reliance on cumbersome run-time guidance. We identify the root cause of this limitation as the inadequacy of current training datasets, which are often too short, low-resolution, and lack the task diversity required to teach robust temporal priors. To address this foundational data gap, we first introduce FFP-300K, a new large-scale dataset comprising 300K high-fidelity video pairs at 720p resolution and 81 frames in length, constructed via a principled two-track pipeline for diverse local and global edits. Building on this dataset, we propose a novel framework designed for true guidance-free FFP that resolves the critical tension between maintaining first-frame appearance and preserving source video motion. Architecturally, we introduce Adaptive Spatio-Temporal RoPE (AST-RoPE), which dynamically remaps positional encodings to disentangle appearance and motion references. At the objective level, we employ a self-distillation strategy where an identity propagation task acts as a powerful regularizer, ensuring long-term temporal stability and preventing semantic drift. Comprehensive experiments on the EditVerseBench benchmark demonstrate that our method significantly outperforming existing academic and commercial models by receiving about 0.2 PickScore and 0.3 VLM score improvement against these competitors.
LongVie 2: Multimodal Controllable Ultra-Long Video World Model
Dec 15, 2025Building video world models upon pretrained video generation systems represents an important yet challenging step toward general spatiotemporal intelligence. A world model should possess three essential properties: controllability, long-term visual quality, and temporal consistency. To this end, we take a progressive approach-first enhancing controllability and then extending toward long-term, high-quality generation. We present LongVie 2, an end-to-end autoregressive framework trained in three stages: (1) Multi-modal guidance, which integrates dense and sparse control signals to provide implicit world-level supervision and improve controllability; (2) Degradation-aware training on the input frame, bridging the gap between training and long-term inference to maintain high visual quality; and (3) History-context guidance, which aligns contextual information across adjacent clips to ensure temporal consistency. We further introduce LongVGenBench, a comprehensive benchmark comprising 100 high-resolution one-minute videos covering diverse real-world and synthetic environments. Extensive experiments demonstrate that LongVie 2 achieves state-of-the-art performance in long-range controllability, temporal coherence, and visual fidelity, and supports continuous video generation lasting up to five minutes, marking a significant step toward unified video world modeling.
VisMem: Latent Vision Memory Unlocks Potential of Vision-Language Models
Nov 14, 2025Despite the remarkable success of Vision-Language Models (VLMs), their performance on a range of complex visual tasks is often hindered by a "visual processing bottleneck": a propensity to lose grounding in visual evidence and exhibit a deficit in contextualized visual experience during prolonged generation. Drawing inspiration from human cognitive memory theory, which distinguishes short-term visually-dominant memory and long-term semantically-dominant memory, we propose VisMem, a cognitively-aligned framework that equips VLMs with dynamic latent vision memories, a short-term module for fine-grained perceptual retention and a long-term module for abstract semantic consolidation. These memories are seamlessly invoked during inference, allowing VLMs to maintain both perceptual fidelity and semantic consistency across thinking and generation. Extensive experiments across diverse visual benchmarks for understanding, reasoning, and generation reveal that VisMem delivers a significant average performance boost of 11.8% relative to the vanilla model and outperforms all counterparts, establishing a new paradigm for latent-space memory enhancement. The code will be available: https://github.com/YU-deep/VisMem.git.
SwiftVideo: A Unified Framework for Few-Step Video Generation through Trajectory-Distribution Alignment
Aug 08, 2025Diffusion-based or flow-based models have achieved significant progress in video synthesis but require multiple iterative sampling steps, which incurs substantial computational overhead. While many distillation methods that are solely based on trajectory-preserving or distribution-matching have been developed to accelerate video generation models, these approaches often suffer from performance breakdown or increased artifacts under few-step settings. To address these limitations, we propose \textbf{\emph{SwiftVideo}}, a unified and stable distillation framework that combines the advantages of trajectory-preserving and distribution-matching strategies. Our approach introduces continuous-time consistency distillation to ensure precise preservation of ODE trajectories. Subsequently, we propose a dual-perspective alignment that includes distribution alignment between synthetic and real data along with trajectory alignment across different inference steps. Our method maintains high-quality video generation while substantially reducing the number of inference steps. Quantitative evaluations on the OpenVid-1M benchmark demonstrate that our method significantly outperforms existing approaches in few-step video generation.
Transferable Adversarial Attacks on Black-Box Vision-Language Models
May 02, 2025
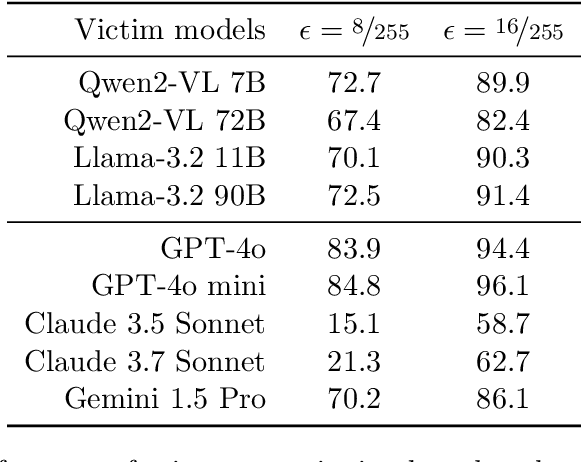
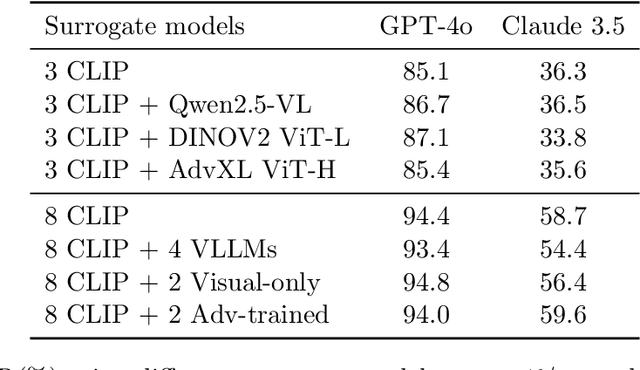
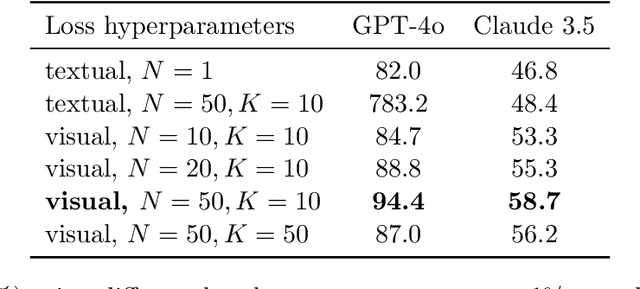
Vision Large Language Models (VLLMs) are increasingly deployed to offer advanced capabilities on inputs comprising both text and images. While prior research has shown that adversarial attacks can transfer from open-source to proprietary black-box models in text-only and vision-only contexts, the extent and effectiveness of such vulnerabilities remain underexplored for VLLMs. We present a comprehensive analysis demonstrating that targeted adversarial examples are highly transferable to widely-used proprietary VLLMs such as GPT-4o, Claude, and Gemini. We show that attackers can craft perturbations to induce specific attacker-chosen interpretations of visual information, such as misinterpreting hazardous content as safe, overlooking sensitive or restricted material, or generating detailed incorrect responses aligned with the attacker's intent. Furthermore, we discover that universal perturbations -- modifications applicable to a wide set of images -- can consistently induce these misinterpretations across multiple proprietary VLLMs. Our experimental results on object recognition, visual question answering, and image captioning show that this vulnerability is common across current state-of-the-art models, and underscore an urgent need for robust mitigations to ensure the safe and secure deployment of VLLMs.
Disentangle Identity, Cooperate Emotion: Correlation-Aware Emotional Talking Portrait Generation
Apr 25, 2025Recent advances in Talking Head Generation (THG) have achieved impressive lip synchronization and visual quality through diffusion models; yet existing methods struggle to generate emotionally expressive portraits while preserving speaker identity. We identify three critical limitations in current emotional talking head generation: insufficient utilization of audio's inherent emotional cues, identity leakage in emotion representations, and isolated learning of emotion correlations. To address these challenges, we propose a novel framework dubbed as DICE-Talk, following the idea of disentangling identity with emotion, and then cooperating emotions with similar characteristics. First, we develop a disentangled emotion embedder that jointly models audio-visual emotional cues through cross-modal attention, representing emotions as identity-agnostic Gaussian distributions. Second, we introduce a correlation-enhanced emotion conditioning module with learnable Emotion Banks that explicitly capture inter-emotion relationships through vector quantization and attention-based feature aggregation. Third, we design an emotion discrimination objective that enforces affective consistency during the diffusion process through latent-space classification. Extensive experiments on MEAD and HDTF datasets demonstrate our method's superiority, outperforming state-of-the-art approaches in emotion accuracy while maintaining competitive lip-sync performance. Qualitative results and user studies further confirm our method's ability to generate identity-preserving portraits with rich, correlated emotional expressions that naturally adapt to unseen identities.
CrossVTON: Mimicking the Logic Reasoning on Cross-category Virtual Try-on guided by Tri-zone Priors
Feb 20, 2025



Despite remarkable progress in image-based virtual try-on systems, generating realistic and robust fitting images for cross-category virtual try-on remains a challenging task. The primary difficulty arises from the absence of human-like reasoning, which involves addressing size mismatches between garments and models while recognizing and leveraging the distinct functionalities of various regions within the model images. To address this issue, we draw inspiration from human cognitive processes and disentangle the complex reasoning required for cross-category try-on into a structured framework. This framework systematically decomposes the model image into three distinct regions: try-on, reconstruction, and imagination zones. Each zone plays a specific role in accommodating the garment and facilitating realistic synthesis. To endow the model with robust reasoning capabilities for cross-category scenarios, we propose an iterative data constructor. This constructor encompasses diverse scenarios, including intra-category try-on, any-to-dress transformations (replacing any garment category with a dress), and dress-to-any transformations (replacing a dress with another garment category). Utilizing the generated dataset, we introduce a tri-zone priors generator that intelligently predicts the try-on, reconstruction, and imagination zones by analyzing how the input garment is expected to align with the model image. Guided by these tri-zone priors, our proposed method, CrossVTON, achieves state-of-the-art performance, surpassing existing baselines in both qualitative and quantitative evaluations. Notably, it demonstrates superior capability in handling cross-category virtual try-on, meeting the complex demands of real-world applications.
SVFR: A Unified Framework for Generalized Video Face Restoration
Jan 03, 2025



Face Restoration (FR) is a crucial area within image and video processing, focusing on reconstructing high-quality portraits from degraded inputs. Despite advancements in image FR, video FR remains relatively under-explored, primarily due to challenges related to temporal consistency, motion artifacts, and the limited availability of high-quality video data. Moreover, traditional face restoration typically prioritizes enhancing resolution and may not give as much consideration to related tasks such as facial colorization and inpainting. In this paper, we propose a novel approach for the Generalized Video Face Restoration (GVFR) task, which integrates video BFR, inpainting, and colorization tasks that we empirically show to benefit each other. We present a unified framework, termed as stable video face restoration (SVFR), which leverages the generative and motion priors of Stable Video Diffusion (SVD) and incorporates task-specific information through a unified face restoration framework. A learnable task embedding is introduced to enhance task identification. Meanwhile, a novel Unified Latent Regularization (ULR) is employed to encourage the shared feature representation learning among different subtasks. To further enhance the restoration quality and temporal stability, we introduce the facial prior learning and the self-referred refinement as auxiliary strategies used for both training and inference. The proposed framework effectively combines the complementary strengths of these tasks, enhancing temporal coherence and achieving superior restoration quality. This work advances the state-of-the-art in video FR and establishes a new paradigm for generalized video face restoration. Code and video demo are available at https://github.com/wangzhiyaoo/SVFR.git.
FitDiT: Advancing the Authentic Garment Details for High-fidelity Virtual Try-on
Nov 22, 2024



Although image-based virtual try-on has made considerable progress, emerging approaches still encounter challenges in producing high-fidelity and robust fitting images across diverse scenarios. These methods often struggle with issues such as texture-aware maintenance and size-aware fitting, which hinder their overall effectiveness. To address these limitations, we propose a novel garment perception enhancement technique, termed FitDiT, designed for high-fidelity virtual try-on using Diffusion Transformers (DiT) allocating more parameters and attention to high-resolution features. First, to further improve texture-aware maintenance, we introduce a garment texture extractor that incorporates garment priors evolution to fine-tune garment feature, facilitating to better capture rich details such as stripes, patterns, and text. Additionally, we introduce frequency-domain learning by customizing a frequency distance loss to enhance high-frequency garment details. To tackle the size-aware fitting issue, we employ a dilated-relaxed mask strategy that adapts to the correct length of garments, preventing the generation of garments that fill the entire mask area during cross-category try-on. Equipped with the above design, FitDiT surpasses all baselines in both qualitative and quantitative evaluations. It excels in producing well-fitting garments with photorealistic and intricate details, while also achieving competitive inference times of 4.57 seconds for a single 1024x768 image after DiT structure slimming, outperforming existing methods.