 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLESA: Vision-Language Embodied Safety Agent for Human Activity Monitoring
Jun 02, 2026As AI systems increasingly assist humans in physical tasks, ensuring safety becomes paramount -- physical actions carry immediate and irreversible consequences that digital errors do not. We introduce the Vision-Language Embodied Safety Agent (VLESA), a framework that monitors human activities from egocentric video and triggers real-time safety interventions when dangerous actions are predicted. VLESA addresses intent-dependent safety where identical actions can be safe or dangerous depending on context. A dataset pairing egocentric frames with goal-conditioned safety annotations is introduced, enabling a goal-conditioned safety Q-filter trained via GRPO that evaluates actions with respect to inferred intent without retraining. On top of that, an intent-action prediction agent is proposed to jointly infer goals and predict future actions from video. On the ASIMOV-2.0 benchmark, VLESA achieves higher intervention accuracy at the exact ground-truth frame compared to baselines, while the GRPO-trained Q-filter improves action safety by over 41 percentage points through goal-conditioned constrained decoding. Code is available at https://github.com/HanjiangHu/VLESA.
Stateful Online Monitoring Catches Distributed Agent Attacks
May 29, 2026Language models can find thousands of severe software vulnerabilities, and agents are increasingly being misused for cyberattacks. To avoid detection, attackers frequently distribute their misuse, splitting a harmful task across many user accounts so each individual transcript looks benign. Because safety monitors score only one agent context at a time, they are structurally blind to misuse that is only visible in aggregate, across many accounts. We show this gap is real by building, to our knowledge, the first distributed agent attack, a multi-agent scaffold that completes hard cybersecurity tasks while hiding the harmful objective across subagents with limited contexts, evading a standard monitor that catches it only a fifth as often as prior agent attacks. Towards a defense, we develop an online stateful monitor that uses real-time clustering to collect weak suspiciousness signals across many agent transcripts, and escalates only rarely to a language model that flags misuse across user accounts. In evaluations with large-scale simulated datacenter traffic, our monitor Pareto dominates standard monitors, catching distributed attacks 30% earlier and flagging cyber misuse before it reaches the most harmful stages. Crucially, this comes at negligible additional latency for ~99% of user traffic. This detection advantage persists but narrows as the benign background traffic grows very large. After an extensive red-teaming exercise, we improve the defense and surprisingly also find that it catches standard jailbreaks, since adaptive attackers reuse attack variants across accounts. Our results point toward a new class of safety monitors which reason over groups of users rather than isolated transcripts.
Contextual Safety Reasoning and Grounding for Open-World Robots
Feb 24, 2026Robots are increasingly operating in open-world environments where safe behavior depends on context: the same hallway may require different navigation strategies when crowded versus empty, or during an emergency versus normal operations. Traditional safety approaches enforce fixed constraints in user-specified contexts, limiting their ability to handle the open-ended contextual variability of real-world deployment. We address this gap via CORE, a safety framework that enables online contextual reasoning, grounding, and enforcement without prior knowledge of the environment (e.g., maps or safety specifications). CORE uses a vision-language model (VLM) to continuously reason about context-dependent safety rules directly from visual observations, grounds these rules in the physical environment, and enforces the resulting spatially-defined safe sets via control barrier functions. We provide probabilistic safety guarantees for CORE that account for perceptual uncertainty, and we demonstrate through simulation and real-world experiments that CORE enforces contextually appropriate behavior in unseen environments, significantly outperforming prior semantic safety methods that lack online contextual reasoning. Ablation studies validate our theoretical guarantees and underscore the importance of both VLM-based reasoning and spatial grounding for enforcing contextual safety in novel settings. We provide additional resources at https://zacravichandran.github.io/CORE.
Antidistillation Fingerprinting
Feb 03, 2026Model distillation enables efficient emulation of frontier large language models (LLMs), creating a need for robust mechanisms to detect when a third-party student model has trained on a teacher model's outputs. However, existing fingerprinting techniques that could be used to detect such distillation rely on heuristic perturbations that impose a steep trade-off between generation quality and fingerprinting strength, often requiring significant degradation of utility to ensure the fingerprint is effectively internalized by the student. We introduce antidistillation fingerprinting (ADFP), a principled approach that aligns the fingerprinting objective with the student's learning dynamics. Building upon the gradient-based framework of antidistillation sampling, ADFP utilizes a proxy model to identify and sample tokens that directly maximize the expected detectability of the fingerprint in the student after fine-tuning, rather than relying on the incidental absorption of the un-targeted biases of a more naive watermark. Experiments on GSM8K and OASST1 benchmarks demonstrate that ADFP achieves a significant Pareto improvement over state-of-the-art baselines, yielding stronger detection confidence with minimal impact on utility, even when the student model's architecture is unknown.
When Should We Introduce Safety Interventions During Pretraining?
Jan 11, 2026Ensuring the safety of language models in high-stakes settings remains a pressing challenge, as aligned behaviors are often brittle and easily undone by adversarial pressure or downstream finetuning. Prior work has shown that interventions applied during pretraining, such as rephrasing harmful content, can substantially improve the safety of the resulting models. In this paper, we study the fundamental question: "When during pretraining should safety interventions be introduced?" We keep the underlying data fixed and vary only the choice of a safety curriculum: the timing of these interventions, i.e., after 0%, 20%, or 60% of the pretraining token budget. We find that introducing interventions earlier generally yields more robust models with no increase in overrefusal rates, with the clearest benefits appearing after downstream, benign finetuning. We also see clear benefits in the steerability of models towards safer generations. Finally, we observe that earlier interventions reshape internal representations: linear probes more cleanly separate safe vs harmful examples. Overall, these results argue for incorporating safety signals early in pretraining, producing models that are more robust to downstream finetuning and jailbreaking, and more reliable under both standard and safety-aware inference procedures.
Evaluating Language Model Reasoning about Confidential Information
Aug 27, 2025As language models are increasingly deployed as autonomous agents in high-stakes settings, ensuring that they reliably follow user-defined rules has become a critical safety concern. To this end, we study whether language models exhibit contextual robustness, or the capability to adhere to context-dependent safety specifications. For this analysis, we develop a benchmark (PasswordEval) that measures whether language models can correctly determine when a user request is authorized (i.e., with a correct password). We find that current open- and closed-source models struggle with this seemingly simple task, and that, perhaps surprisingly, reasoning capabilities do not generally improve performance. In fact, we find that reasoning traces frequently leak confidential information, which calls into question whether reasoning traces should be exposed to users in such applications. We also scale the difficulty of our evaluation along multiple axes: (i) by adding adversarial user pressure through various jailbreaking strategies, and (ii) through longer multi-turn conversations where password verification is more challenging. Overall, our results suggest that current frontier models are not well-suited to handling confidential information, and that reasoning capabilities may need to be trained in a different manner to make them safer for release in high-stakes settings.
Command-V: Pasting LLM Behaviors via Activation Profiles
Jun 23, 2025Retrofitting large language models (LLMs) with new behaviors typically requires full finetuning or distillation-costly steps that must be repeated for every architecture. In this work, we introduce Command-V, a backpropagation-free behavior transfer method that copies an existing residual activation adapter from a donor model and pastes its effect into a recipient model. Command-V profiles layer activations on a small prompt set, derives linear converters between corresponding layers, and applies the donor intervention in the recipient's activation space. This process does not require access to the original training data and needs minimal compute. In three case studies-safety-refusal enhancement, jailbreak facilitation, and automatic chain-of-thought reasoning--Command-V matches or exceeds the performance of direct finetuning while using orders of magnitude less compute. Our code and data are accessible at https://github.com/GithuBarry/Command-V/.
Benchmarking Misuse Mitigation Against Covert Adversaries
Jun 06, 2025Existing language model safety evaluations focus on overt attacks and low-stakes tasks. Realistic attackers can subvert current safeguards by requesting help on small, benign-seeming tasks across many independent queries. Because individual queries do not appear harmful, the attack is hard to {detect}. However, when combined, these fragments uplift misuse by helping the attacker complete hard and dangerous tasks. Toward identifying defenses against such strategies, we develop Benchmarks for Stateful Defenses (BSD), a data generation pipeline that automates evaluations of covert attacks and corresponding defenses. Using this pipeline, we curate two new datasets that are consistently refused by frontier models and are too difficult for weaker open-weight models. Our evaluations indicate that decomposition attacks are effective misuse enablers, and highlight stateful defenses as a countermeasure.
Transferable Adversarial Attacks on Black-Box Vision-Language Models
May 02, 2025
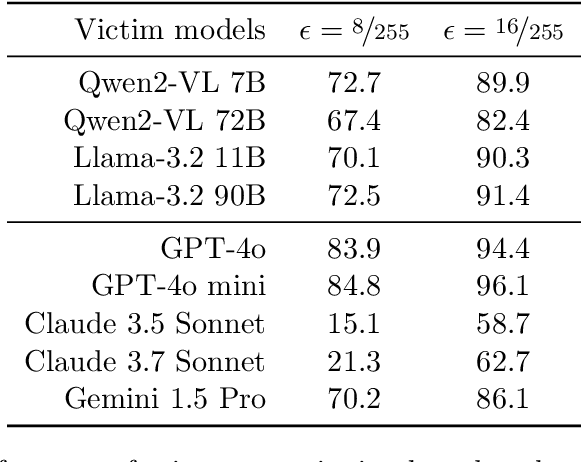
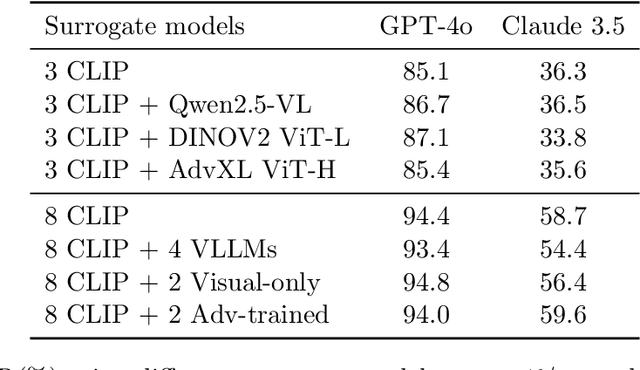
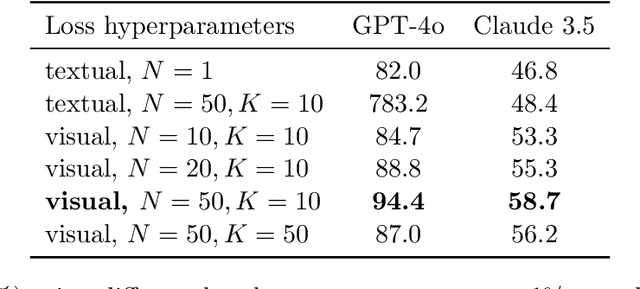
Vision Large Language Models (VLLMs) are increasingly deployed to offer advanced capabilities on inputs comprising both text and images. While prior research has shown that adversarial attacks can transfer from open-source to proprietary black-box models in text-only and vision-only contexts, the extent and effectiveness of such vulnerabilities remain underexplored for VLLMs. We present a comprehensive analysis demonstrating that targeted adversarial examples are highly transferable to widely-used proprietary VLLMs such as GPT-4o, Claude, and Gemini. We show that attackers can craft perturbations to induce specific attacker-chosen interpretations of visual information, such as misinterpreting hazardous content as safe, overlooking sensitive or restricted material, or generating detailed incorrect responses aligned with the attacker's intent. Furthermore, we discover that universal perturbations -- modifications applicable to a wide set of images -- can consistently induce these misinterpretations across multiple proprietary VLLMs. Our experimental results on object recognition, visual question answering, and image captioning show that this vulnerability is common across current state-of-the-art models, and underscore an urgent need for robust mitigations to ensure the safe and secure deployment of VLLMs.
Antidistillation Sampling
Apr 17, 2025Frontier models that generate extended reasoning traces inadvertently produce rich token sequences that can facilitate model distillation. Recognizing this vulnerability, model owners may seek sampling strategies that limit the effectiveness of distillation without compromising model performance. \emph{Antidistillation sampling} provides exactly this capability. By strategically modifying a model's next-token probability distribution, antidistillation sampling poisons reasoning traces, rendering them significantly less effective for distillation while preserving the model's practical utility. For further details, see https://antidistillation.com.