 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Unstructured Text into Causal Inference: Empirical Evidence from Real Data
Feb 15, 2026Causal inference, a critical tool for informing business decisions, traditionally relies heavily on structured data. However, in many real-world scenarios, such data can be incomplete or unavailable. This paper presents a framework that leverages transformer-based language models to perform causal inference using unstructured text. We demonstrate the effectiveness of our framework by comparing causal estimates derived from unstructured text against those obtained from structured data across population, group, and individual levels. Our findings show consistent results between the two approaches, validating the potential of unstructured text in causal inference tasks. Our approach extends the applicability of causal inference methods to scenarios where only textual data is available, enabling data-driven business decision-making when structured tabular data is scarce.
LipNeXt: Scaling up Lipschitz-based Certified Robustness to Billion-parameter Models
Jan 26, 2026Lipschitz-based certification offers efficient, deterministic robustness guarantees but has struggled to scale in model size, training efficiency, and ImageNet performance. We introduce \emph{LipNeXt}, the first \emph{constraint-free} and \emph{convolution-free} 1-Lipschitz architecture for certified robustness. LipNeXt is built using two techniques: (1) a manifold optimization procedure that updates parameters directly on the orthogonal manifold and (2) a \emph{Spatial Shift Module} to model spatial pattern without convolutions. The full network uses orthogonal projections, spatial shifts, a simple 1-Lipschitz $β$-Abs nonlinearity, and $L_2$ spatial pooling to maintain tight Lipschitz control while enabling expressive feature mixing. Across CIFAR-10/100 and Tiny-ImageNet, LipNeXt achieves state-of-the-art clean and certified robust accuracy (CRA), and on ImageNet it scales to 1-2B large models, improving CRA over prior Lipschitz models (e.g., up to $+8\%$ at $\varepsilon{=}1$) while retaining efficient, stable low-precision training. These results demonstrate that Lipschitz-based certification can benefit from modern scaling trends without sacrificing determinism or efficiency.
Transferable Adversarial Attacks on Black-Box Vision-Language Models
May 02, 2025
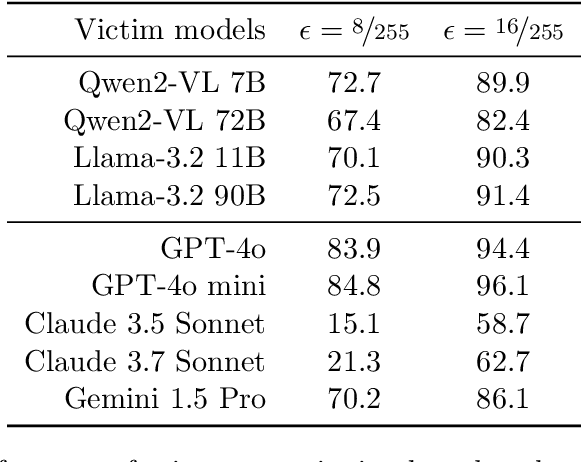
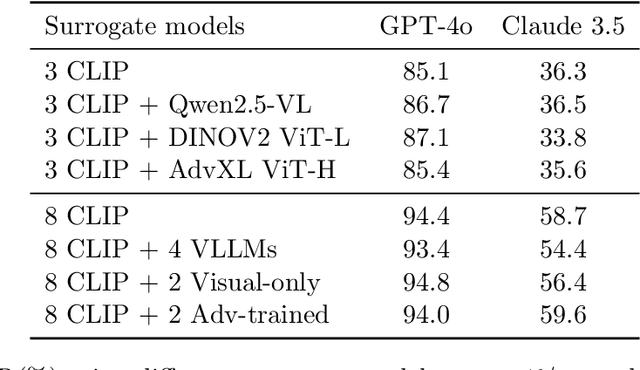
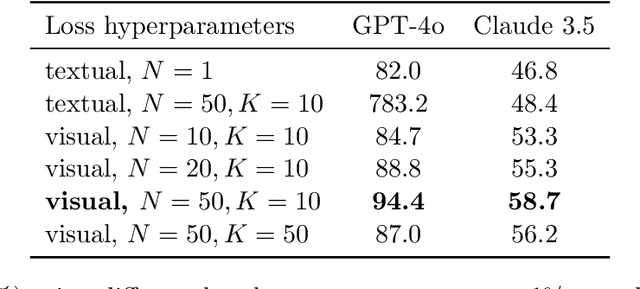
Vision Large Language Models (VLLMs) are increasingly deployed to offer advanced capabilities on inputs comprising both text and images. While prior research has shown that adversarial attacks can transfer from open-source to proprietary black-box models in text-only and vision-only contexts, the extent and effectiveness of such vulnerabilities remain underexplored for VLLMs. We present a comprehensive analysis demonstrating that targeted adversarial examples are highly transferable to widely-used proprietary VLLMs such as GPT-4o, Claude, and Gemini. We show that attackers can craft perturbations to induce specific attacker-chosen interpretations of visual information, such as misinterpreting hazardous content as safe, overlooking sensitive or restricted material, or generating detailed incorrect responses aligned with the attacker's intent. Furthermore, we discover that universal perturbations -- modifications applicable to a wide set of images -- can consistently induce these misinterpretations across multiple proprietary VLLMs. Our experimental results on object recognition, visual question answering, and image captioning show that this vulnerability is common across current state-of-the-art models, and underscore an urgent need for robust mitigations to ensure the safe and secure deployment of VLLMs.