 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$τ_0$-WM: A Unified Video-Action World Model for Robotic Manipulation
May 31, 2026Robotic manipulation requires models that generate executable actions while anticipating and evaluating their future consequences before physical execution. We present $τ_0$-World Model ($τ_0$-WM), a unified video-action world model that integrates policy learning, video prediction, and action evaluation within a single future-predictive framework. Built on a shared video diffusion backbone, $τ_0$-WM provides two complementary interfaces. First, a video action model jointly predicts future visual latents and continuous action chunks from multi-view observations, language instructions, and robot state. Second, an action-conditioned video simulator rolls out candidate action chunks into multi-view futures and predicts dense task-progress scores. The model is trained on approximately $27{,}300$ hours of real-robot teleoperation, UMI-style interaction, egocentric human videos, and rollout or failure trajectories using modality-specific supervision masks. At inference time, $τ_0$-WM uses test-time computation to sample action candidates, rank them with re-denoising consistency, and invoke simulator-based rectification for low-quality candidates. On challenging long-horizon and fine-grained robotic manipulation tasks, $τ_0$-WM shows superior performance over other relevant baselines.
What Semantics Survive the Connector? Diagnosing VLM-to-DiT Alignment in Video Editing
May 20, 2026Flow matching based video generative models have been increasingly relying on prepended Vision-Language Models (VLMs) to handle complex, instruction-based video editing. The prevailing assumption underlying this paradigm is that a connector module can seamlessly align the VLM's rich multi-modal reasoning with the original text embedding space of DiTs. However, we hypothesize that this alignment acts as a severe semantic bottleneck, degrading fine-grained structural variables. Verifying this is challenging, as end-to-end evaluations conflate alignment failures with generation errors, and natural datasets lack disentangled annotations. To rigorously investigate this, we propose a controlled data processing pipeline based on video composition that results in TRACE-Edit, a diagnostic dataset focusing on relation-based editing. Leveraging this dataset, we propose a comprehensive diagnostic protocol to analyze two important designs of meta-query and connector in the existing video editing models. Systematic evaluation of four representative model cases reveals that fine-grained structural semantics can be severely degraded during alignment. Our findings overturn the assumption of lossless semantic transfer, identifying the VLM-to-DiT alignment as a major bottleneck and providing a new diagnostic foundation for future multi-modal alignment architectures.
Bridging Brain and Semantics: A Hierarchical Framework for Semantically Enhanced fMRI-to-Video Reconstruction
May 14, 2026Reconstructing dynamic visual experiences as videos from functional magnetic resonance imaging (fMRI) is pivotal for advancing the understanding of neural processes. However, current fMRI-to-video reconstruction methods are hindered by a semantic gap between noisy fMRI signals and the rich content of videos, stemming from a reliance on incomplete semantic embeddings that neither capture video-specific cues (e.g., actions) nor integrate prior knowledge. To this end, we draw inspiration from the dual-pathway processing mechanism in human brain and introduce CineNeuron, a novel hierarchical framework for semantically enhanced video reconstruction from fMRI signals with two synergistic stages. First, a bottom-up semantic enrichment stage maps fMRI signals to a rich embedding space that comprehensively captures textual semantics, image contents, action concepts, and object categories. Second, a top-down memory integration stage utilizes the proposed Mixture-of-Memories method to dynamically select relevant "memories" from previously seen data and fuse them with the fMRI embedding to refine the video reconstruction. Extensive experimental results on two fMRI-to-video benchmarks demonstrate that CineNeuron surpasses state-of-the-art methods across various metrics.
Modeling Spatiotemporal Neural Frames for High Resolution Brain Dynamic
Mar 25, 2026Capturing dynamic spatiotemporal neural activity is essential for understanding large-scale brain mechanisms. Functional magnetic resonance imaging (fMRI) provides high-resolution cortical representations that form a strong basis for characterizing fine-grained brain activity patterns. The high acquisition cost of fMRI limits large-scale applications, therefore making high-quality fMRI reconstruction a crucial task. Electroencephalography (EEG) offers millisecond-level temporal cues that complement fMRI. Leveraging this complementarity, we present an EEG-conditioned framework for reconstructing dynamic fMRI as continuous neural sequences with high spatial fidelity and strong temporal coherence at the cortical-vertex level. To address sampling irregularities common in real fMRI acquisitions, we incorporate a null-space intermediate-frame reconstruction, enabling measurement-consistent completion of arbitrary intermediate frames and improving sequence continuity and practical applicability. Experiments on the CineBrain dataset demonstrate superior voxel-wise reconstruction quality and robust temporal consistency across whole-brain and functionally specific regions. The reconstructed fMRI also preserves essential functional information, supporting downstream visual decoding tasks. This work provides a new pathway for estimating high-resolution fMRI dynamics from EEG and advances multimodal neuroimaging toward more dynamic brain activity modeling.
EchoGen: Cycle-Consistent Learning for Unified Layout-Image Generation and Understanding
Mar 18, 2026In this work, we present EchoGen, a unified framework for layout-to-image generation and image grounding, capable of generating images with accurate layouts and high fidelity to text descriptions (e.g., spatial relationships), while grounding the image robustly at the same time. We believe that image grounding possesses strong text and layout understanding abilities, which can compensate for the corresponding limitations in layout-to-image generation. At the same time, images generated from layouts exhibit high diversity in content, thereby enhancing the robustness of image grounding. Jointly training both tasks within a unified model can promote performance improvements for each. However, we identify that this joint training paradigm encounters several optimization challenges and results in restricted performance. To address these issues, we propose progressive training strategies. First, the Parallel Multi-Task Pre-training (PMTP) stage equips the model with basic abilities for both tasks, leveraging shared tokens to accelerate training. Next, the Dual Joint Optimization (DJO) stage exploits task duality to sequentially integrate the two tasks, enabling unified optimization. Finally, the Cycle RL stage eliminates reliance on visual supervision by using consistency constraints as rewards, significantly enhancing the model's unified capabilities via the GRPO strategy. Extensive experiments demonstrate state-of-the-art results on both layout-to-image generation and image grounding benchmarks, and reveal clear synergistic gains from optimizing the two tasks together.
* 9 pages, Accepted at the 40th AAAI Conference on Artificial Intelligence (AAAI 2026)
LongVie 2: Multimodal Controllable Ultra-Long Video World Model
Dec 15, 2025Building video world models upon pretrained video generation systems represents an important yet challenging step toward general spatiotemporal intelligence. A world model should possess three essential properties: controllability, long-term visual quality, and temporal consistency. To this end, we take a progressive approach-first enhancing controllability and then extending toward long-term, high-quality generation. We present LongVie 2, an end-to-end autoregressive framework trained in three stages: (1) Multi-modal guidance, which integrates dense and sparse control signals to provide implicit world-level supervision and improve controllability; (2) Degradation-aware training on the input frame, bridging the gap between training and long-term inference to maintain high visual quality; and (3) History-context guidance, which aligns contextual information across adjacent clips to ensure temporal consistency. We further introduce LongVGenBench, a comprehensive benchmark comprising 100 high-resolution one-minute videos covering diverse real-world and synthetic environments. Extensive experiments demonstrate that LongVie 2 achieves state-of-the-art performance in long-range controllability, temporal coherence, and visual fidelity, and supports continuous video generation lasting up to five minutes, marking a significant step toward unified video world modeling.
SafeRBench: A Comprehensive Benchmark for Safety Assessment in Large Reasoning Models
Nov 19, 2025Large Reasoning Models (LRMs) improve answer quality through explicit chain-of-thought, yet this very capability introduces new safety risks: harmful content can be subtly injected, surface gradually, or be justified by misleading rationales within the reasoning trace. Existing safety evaluations, however, primarily focus on output-level judgments and rarely capture these dynamic risks along the reasoning process. In this paper, we present SafeRBench, the first benchmark that assesses LRM safety end-to-end -- from inputs and intermediate reasoning to final outputs. (1) Input Characterization: We pioneer the incorporation of risk categories and levels into input design, explicitly accounting for affected groups and severity, and thereby establish a balanced prompt suite reflecting diverse harm gradients. (2) Fine-Grained Output Analysis: We introduce a micro-thought chunking mechanism to segment long reasoning traces into semantically coherent units, enabling fine-grained evaluation across ten safety dimensions. (3) Human Safety Alignment: We validate LLM-based evaluations against human annotations specifically designed to capture safety judgments. Evaluations on 19 LRMs demonstrate that SafeRBench enables detailed, multidimensional safety assessment, offering insights into risks and protective mechanisms from multiple perspectives.
CineBrain: A Large-Scale Multi-Modal Brain Dataset During Naturalistic Audiovisual Narrative Processing
Mar 10, 2025

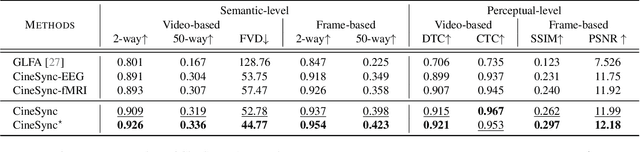

In this paper, we introduce CineBrain, the first large-scale dataset featuring simultaneous EEG and fMRI recordings during dynamic audiovisual stimulation. Recognizing the complementary strengths of EEG's high temporal resolution and fMRI's deep-brain spatial coverage, CineBrain provides approximately six hours of narrative-driven content from the popular television series The Big Bang Theory for each of six participants. Building upon this unique dataset, we propose CineSync, an innovative multimodal decoding framework integrates a Multi-Modal Fusion Encoder with a diffusion-based Neural Latent Decoder. Our approach effectively fuses EEG and fMRI signals, significantly improving the reconstruction quality of complex audiovisual stimuli. To facilitate rigorous evaluation, we introduce Cine-Benchmark, a comprehensive evaluation protocol that assesses reconstructions across semantic and perceptual dimensions. Experimental results demonstrate that CineSync achieves state-of-the-art video reconstruction performance and highlight our initial success in combining fMRI and EEG for reconstructing both video and audio stimuli. Project Page: https://jianxgao.github.io/CineBrain.
Making Your Dreams A Reality: Decoding the Dreams into a Coherent Video Story from fMRI Signals
Jan 16, 2025



This paper studies the brave new idea for Multimedia community, and proposes a novel framework to convert dreams into coherent video narratives using fMRI data. Essentially, dreams have intrigued humanity for centuries, offering glimpses into our subconscious minds. Recent advancements in brain imaging, particularly functional magnetic resonance imaging (fMRI), have provided new ways to explore the neural basis of dreaming. By combining subjective dream experiences with objective neurophysiological data, we aim to understand the visual aspects of dreams and create complete video narratives. Our process involves three main steps: reconstructing visual perception, decoding dream imagery, and integrating dream stories. Using innovative techniques in fMRI analysis and language modeling, we seek to push the boundaries of dream research and gain deeper insights into visual experiences during sleep. This technical report introduces a novel approach to visually decoding dreams using fMRI signals and weaving dream visuals into narratives using language models. We gather a dataset of dreams along with descriptions to assess the effectiveness of our framework.
Factorized Visual Tokenization and Generation
Nov 25, 2024



Visual tokenizers are fundamental to image generation. They convert visual data into discrete tokens, enabling transformer-based models to excel at image generation. Despite their success, VQ-based tokenizers like VQGAN face significant limitations due to constrained vocabulary sizes. Simply expanding the codebook often leads to training instability and diminishing performance gains, making scalability a critical challenge. In this work, we introduce Factorized Quantization (FQ), a novel approach that revitalizes VQ-based tokenizers by decomposing a large codebook into multiple independent sub-codebooks. This factorization reduces the lookup complexity of large codebooks, enabling more efficient and scalable visual tokenization. To ensure each sub-codebook captures distinct and complementary information, we propose a disentanglement regularization that explicitly reduces redundancy, promoting diversity across the sub-codebooks. Furthermore, we integrate representation learning into the training process, leveraging pretrained vision models like CLIP and DINO to infuse semantic richness into the learned representations. This design ensures our tokenizer captures diverse semantic levels, leading to more expressive and disentangled representations. Experiments show that the proposed FQGAN model substantially improves the reconstruction quality of visual tokenizers, achieving state-of-the-art performance. We further demonstrate that this tokenizer can be effectively adapted into auto-regressive image generation. https://showlab.github.io/FQGAN