 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefAny3D: 3D Asset-Referenced Diffusion Models for Image Generation
Jan 29, 2026In this paper, we propose a 3D asset-referenced diffusion model for image generation, exploring how to integrate 3D assets into image diffusion models. Existing reference-based image generation methods leverage large-scale pretrained diffusion models and demonstrate strong capability in generating diverse images conditioned on a single reference image. However, these methods are limited to single-image references and cannot leverage 3D assets, constraining their practical versatility. To address this gap, we present a cross-domain diffusion model with dual-branch perception that leverages multi-view RGB images and point maps of 3D assets to jointly model their colors and canonical-space coordinates, achieving precise consistency between generated images and the 3D references. Our spatially aligned dual-branch generation architecture and domain-decoupled generation mechanism ensure the simultaneous generation of two spatially aligned but content-disentangled outputs, RGB images and point maps, linking 2D image attributes with 3D asset attributes. Experiments show that our approach effectively uses 3D assets as references to produce images consistent with the given assets, opening new possibilities for combining diffusion models with 3D content creation.
TrackingWorld: World-centric Monocular 3D Tracking of Almost All Pixels
Dec 09, 2025Monocular 3D tracking aims to capture the long-term motion of pixels in 3D space from a single monocular video and has witnessed rapid progress in recent years. However, we argue that the existing monocular 3D tracking methods still fall short in separating the camera motion from foreground dynamic motion and cannot densely track newly emerging dynamic subjects in the videos. To address these two limitations, we propose TrackingWorld, a novel pipeline for dense 3D tracking of almost all pixels within a world-centric 3D coordinate system. First, we introduce a tracking upsampler that efficiently lifts the arbitrary sparse 2D tracks into dense 2D tracks. Then, to generalize the current tracking methods to newly emerging objects, we apply the upsampler to all frames and reduce the redundancy of 2D tracks by eliminating the tracks in overlapped regions. Finally, we present an efficient optimization-based framework to back-project dense 2D tracks into world-centric 3D trajectories by estimating the camera poses and the 3D coordinates of these 2D tracks. Extensive evaluations on both synthetic and real-world datasets demonstrate that our system achieves accurate and dense 3D tracking in a world-centric coordinate frame.
Every Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model
Oct 21, 2025



We present Ring-1T, the first open-source, state-of-the-art thinking model with a trillion-scale parameter. It features 1 trillion total parameters and activates approximately 50 billion per token. Training such models at a trillion-parameter scale introduces unprecedented challenges, including train-inference misalignment, inefficiencies in rollout processing, and bottlenecks in the RL system. To address these, we pioneer three interconnected innovations: (1) IcePop stabilizes RL training via token-level discrepancy masking and clipping, resolving instability from training-inference mismatches; (2) C3PO++ improves resource utilization for long rollouts under a token budget by dynamically partitioning them, thereby obtaining high time efficiency; and (3) ASystem, a high-performance RL framework designed to overcome the systemic bottlenecks that impede trillion-parameter model training. Ring-1T delivers breakthrough results across critical benchmarks: 93.4 on AIME-2025, 86.72 on HMMT-2025, 2088 on CodeForces, and 55.94 on ARC-AGI-v1. Notably, it attains a silver medal-level result on the IMO-2025, underscoring its exceptional reasoning capabilities. By releasing the complete 1T parameter MoE model to the community, we provide the research community with direct access to cutting-edge reasoning capabilities. This contribution marks a significant milestone in democratizing large-scale reasoning intelligence and establishes a new baseline for open-source model performance.
PartSAM: A Scalable Promptable Part Segmentation Model Trained on Native 3D Data
Sep 26, 2025Segmenting 3D objects into parts is a long-standing challenge in computer vision. To overcome taxonomy constraints and generalize to unseen 3D objects, recent works turn to open-world part segmentation. These approaches typically transfer supervision from 2D foundation models, such as SAM, by lifting multi-view masks into 3D. However, this indirect paradigm fails to capture intrinsic geometry, leading to surface-only understanding, uncontrolled decomposition, and limited generalization. We present PartSAM, the first promptable part segmentation model trained natively on large-scale 3D data. Following the design philosophy of SAM, PartSAM employs an encoder-decoder architecture in which a triplane-based dual-branch encoder produces spatially structured tokens for scalable part-aware representation learning. To enable large-scale supervision, we further introduce a model-in-the-loop annotation pipeline that curates over five million 3D shape-part pairs from online assets, providing diverse and fine-grained labels. This combination of scalable architecture and diverse 3D data yields emergent open-world capabilities: with a single prompt, PartSAM achieves highly accurate part identification, and in a Segment-Every-Part mode, it automatically decomposes shapes into both surface and internal structures. Extensive experiments show that PartSAM outperforms state-of-the-art methods by large margins across multiple benchmarks, marking a decisive step toward foundation models for 3D part understanding. Our code and model will be released soon.
MOSPA: Human Motion Generation Driven by Spatial Audio
Jul 16, 2025Enabling virtual humans to dynamically and realistically respond to diverse auditory stimuli remains a key challenge in character animation, demanding the integration of perceptual modeling and motion synthesis. Despite its significance, this task remains largely unexplored. Most previous works have primarily focused on mapping modalities like speech, audio, and music to generate human motion. As of yet, these models typically overlook the impact of spatial features encoded in spatial audio signals on human motion. To bridge this gap and enable high-quality modeling of human movements in response to spatial audio, we introduce the first comprehensive Spatial Audio-Driven Human Motion (SAM) dataset, which contains diverse and high-quality spatial audio and motion data. For benchmarking, we develop a simple yet effective diffusion-based generative framework for human MOtion generation driven by SPatial Audio, termed MOSPA, which faithfully captures the relationship between body motion and spatial audio through an effective fusion mechanism. Once trained, MOSPA could generate diverse realistic human motions conditioned on varying spatial audio inputs. We perform a thorough investigation of the proposed dataset and conduct extensive experiments for benchmarking, where our method achieves state-of-the-art performance on this task. Our model and dataset will be open-sourced upon acceptance. Please refer to our supplementary video for more details.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
Multi-Type Context-Aware Conversational Recommender Systems via Mixture-of-Experts
Apr 18, 2025Conversational recommender systems enable natural language conversations and thus lead to a more engaging and effective recommendation scenario. As the conversations for recommender systems usually contain limited contextual information, many existing conversational recommender systems incorporate external sources to enrich the contextual information. However, how to combine different types of contextual information is still a challenge. In this paper, we propose a multi-type context-aware conversational recommender system, called MCCRS, effectively fusing multi-type contextual information via mixture-of-experts to improve conversational recommender systems. MCCRS incorporates both structured information and unstructured information, including the structured knowledge graph, unstructured conversation history, and unstructured item reviews. It consists of several experts, with each expert specialized in a particular domain (i.e., one specific contextual information). Multiple experts are then coordinated by a ChairBot to generate the final results. Our proposed MCCRS model takes advantage of different contextual information and the specialization of different experts followed by a ChairBot breaks the model bottleneck on a single contextual information. Experimental results demonstrate that our proposed MCCRS method achieves significantly higher performance compared to existing baselines.
CADDreamer: CAD object Generation from Single-view Images
Feb 28, 2025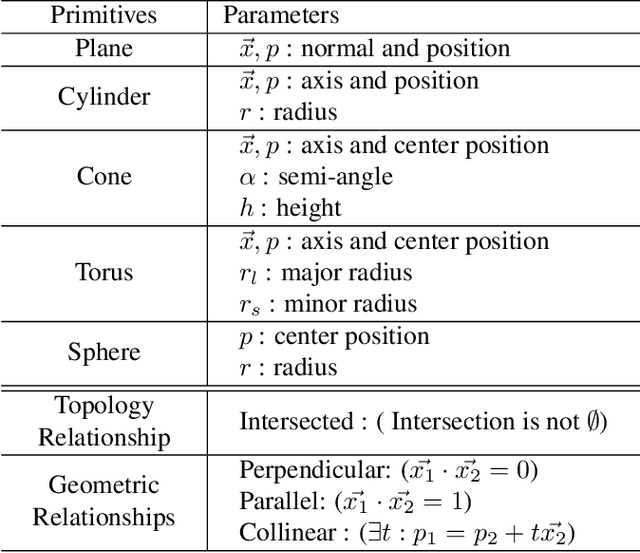
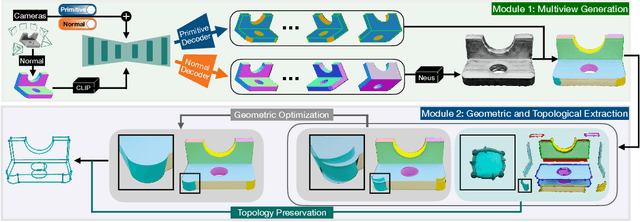

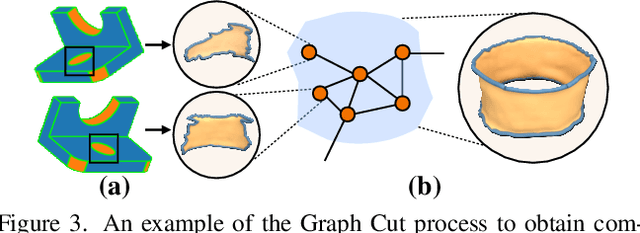
Diffusion-based 3D generation has made remarkable progress in recent years. However, existing 3D generative models often produce overly dense and unstructured meshes, which stand in stark contrast to the compact, structured, and sharply-edged Computer-Aided Design (CAD) models crafted by human designers. To address this gap, we introduce CADDreamer, a novel approach for generating boundary representations (B-rep) of CAD objects from a single image. CADDreamer employs a primitive-aware multi-view diffusion model that captures both local geometric details and high-level structural semantics during the generation process. By encoding primitive semantics into the color domain, the method leverages the strong priors of pre-trained diffusion models to align with well-defined primitives. This enables the inference of multi-view normal maps and semantic maps from a single image, facilitating the reconstruction of a mesh with primitive labels. Furthermore, we introduce geometric optimization techniques and topology-preserving extraction methods to mitigate noise and distortion in the generated primitives. These enhancements result in a complete and seamless B-rep of the CAD model. Experimental results demonstrate that our method effectively recovers high-quality CAD objects from single-view images. Compared to existing 3D generation techniques, the B-rep models produced by CADDreamer are compact in representation, clear in structure, sharp in edges, and watertight in topology.
WonderHuman: Hallucinating Unseen Parts in Dynamic 3D Human Reconstruction
Feb 03, 2025In this paper, we present WonderHuman to reconstruct dynamic human avatars from a monocular video for high-fidelity novel view synthesis. Previous dynamic human avatar reconstruction methods typically require the input video to have full coverage of the observed human body. However, in daily practice, one typically has access to limited viewpoints, such as monocular front-view videos, making it a cumbersome task for previous methods to reconstruct the unseen parts of the human avatar. To tackle the issue, we present WonderHuman, which leverages 2D generative diffusion model priors to achieve high-quality, photorealistic reconstructions of dynamic human avatars from monocular videos, including accurate rendering of unseen body parts. Our approach introduces a Dual-Space Optimization technique, applying Score Distillation Sampling (SDS) in both canonical and observation spaces to ensure visual consistency and enhance realism in dynamic human reconstruction. Additionally, we present a View Selection strategy and Pose Feature Injection to enforce the consistency between SDS predictions and observed data, ensuring pose-dependent effects and higher fidelity in the reconstructed avatar. In the experiments, our method achieves SOTA performance in producing photorealistic renderings from the given monocular video, particularly for those challenging unseen parts. The project page and source code can be found at https://wyiguanw.github.io/WonderHuman/.
Diffusion as Shader: 3D-aware Video Diffusion for Versatile Video Generation Control
Jan 07, 2025



Diffusion models have demonstrated impressive performance in generating high-quality videos from text prompts or images. However, precise control over the video generation process, such as camera manipulation or content editing, remains a significant challenge. Existing methods for controlled video generation are typically limited to a single control type, lacking the flexibility to handle diverse control demands. In this paper, we introduce Diffusion as Shader (DaS), a novel approach that supports multiple video control tasks within a unified architecture. Our key insight is that achieving versatile video control necessitates leveraging 3D control signals, as videos are fundamentally 2D renderings of dynamic 3D content. Unlike prior methods limited to 2D control signals, DaS leverages 3D tracking videos as control inputs, making the video diffusion process inherently 3D-aware. This innovation allows DaS to achieve a wide range of video controls by simply manipulating the 3D tracking videos. A further advantage of using 3D tracking videos is their ability to effectively link frames, significantly enhancing the temporal consistency of the generated videos. With just 3 days of fine-tuning on 8 H800 GPUs using less than 10k videos, DaS demonstrates strong control capabilities across diverse tasks, including mesh-to-video generation, camera control, motion transfer, and object manipulation.