 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Classifiers Without Fair Training: An Influence-Guided Data Sampling Approach
Feb 20, 2024



A fair classifier should ensure the benefit of people from different groups, while the group information is often sensitive and unsuitable for model training. Therefore, learning a fair classifier but excluding sensitive attributes in the training dataset is important. In this paper, we study learning fair classifiers without implementing fair training algorithms to avoid possible leakage of sensitive information. Our theoretical analyses validate the possibility of this approach, that traditional training on a dataset with an appropriate distribution shift can reduce both the upper bound for fairness disparity and model generalization error, indicating that fairness and accuracy can be improved simultaneously with simply traditional training. We then propose a tractable solution to progressively shift the original training data during training by sampling influential data, where the sensitive attribute of new data is not accessed in sampling or used in training. Extensive experiments on real-world data demonstrate the effectiveness of our proposed algorithm.
MetaTra: Meta-Learning for Generalized Trajectory Prediction in Unseen Domain
Feb 13, 2024
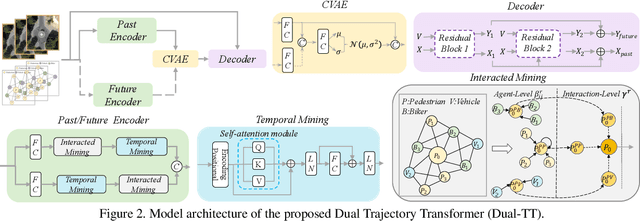


Trajectory prediction has garnered widespread attention in different fields, such as autonomous driving and robotic navigation. However, due to the significant variations in trajectory patterns across different scenarios, models trained in known environments often falter in unseen ones. To learn a generalized model that can directly handle unseen domains without requiring any model updating, we propose a novel meta-learning-based trajectory prediction method called MetaTra. This approach incorporates a Dual Trajectory Transformer (Dual-TT), which enables a thorough exploration of the individual intention and the interactions within group motion patterns in diverse scenarios. Building on this, we propose a meta-learning framework to simulate the generalization process between source and target domains. Furthermore, to enhance the stability of our prediction outcomes, we propose a Serial and Parallel Training (SPT) strategy along with a feature augmentation method named MetaMix. Experimental results on several real-world datasets confirm that MetaTra not only surpasses other state-of-the-art methods but also exhibits plug-and-play capabilities, particularly in the realm of domain generalization.
Lens: A Foundation Model for Network Traffic in Cybersecurity
Feb 09, 2024Network traffic refers to the amount of data being sent and received over the internet or any system that connects computers. Analyzing and understanding network traffic is vital for improving network security and management. However, the analysis of network traffic is challenging due to the diverse nature of data packets, which often feature heterogeneous headers and encrypted payloads lacking semantics. To capture the latent semantics of traffic, a few studies have adopted pre-training techniques based on the Transformer encoder or decoder to learn the representations from massive traffic data. However, these methods typically excel in traffic understanding (classification) or traffic generation tasks. To address this issue, we develop Lens, a foundation model for network traffic that leverages the T5 architecture to learn the pre-trained representations from large-scale unlabeled data. Harnessing the strength of the encoder-decoder framework, which captures the global information while preserving the generative ability, our model can better learn the representations from raw data. To further enhance pre-training effectiveness, we design a novel loss that combines three distinct tasks: Masked Span Prediction (MSP), Packet Order Prediction (POP), and Homologous Traffic Prediction (HTP). Evaluation results across various benchmark datasets demonstrate that the proposed Lens outperforms the baselines in most downstream tasks related to both traffic understanding and generation. Notably, it also requires much less labeled data for fine-tuning compared to current methods.
DiffSpeaker: Speech-Driven 3D Facial Animation with Diffusion Transformer
Feb 08, 2024



Speech-driven 3D facial animation is important for many multimedia applications. Recent work has shown promise in using either Diffusion models or Transformer architectures for this task. However, their mere aggregation does not lead to improved performance. We suspect this is due to a shortage of paired audio-4D data, which is crucial for the Transformer to effectively perform as a denoiser within the Diffusion framework. To tackle this issue, we present DiffSpeaker, a Transformer-based network equipped with novel biased conditional attention modules. These modules serve as substitutes for the traditional self/cross-attention in standard Transformers, incorporating thoughtfully designed biases that steer the attention mechanisms to concentrate on both the relevant task-specific and diffusion-related conditions. We also explore the trade-off between accurate lip synchronization and non-verbal facial expressions within the Diffusion paradigm. Experiments show our model not only achieves state-of-the-art performance on existing benchmarks, but also fast inference speed owing to its ability to generate facial motions in parallel.
Topology-Aware Latent Diffusion for 3D Shape Generation
Jan 31, 2024We introduce a new generative model that combines latent diffusion with persistent homology to create 3D shapes with high diversity, with a special emphasis on their topological characteristics. Our method involves representing 3D shapes as implicit fields, then employing persistent homology to extract topological features, including Betti numbers and persistence diagrams. The shape generation process consists of two steps. Initially, we employ a transformer-based autoencoding module to embed the implicit representation of each 3D shape into a set of latent vectors. Subsequently, we navigate through the learned latent space via a diffusion model. By strategically incorporating topological features into the diffusion process, our generative module is able to produce a richer variety of 3D shapes with different topological structures. Furthermore, our framework is flexible, supporting generation tasks constrained by a variety of inputs, including sparse and partial point clouds, as well as sketches. By modifying the persistence diagrams, we can alter the topology of the shapes generated from these input modalities.
From GPT-4 to Gemini and Beyond: Assessing the Landscape of MLLMs on Generalizability, Trustworthiness and Causality through Four Modalities
Jan 29, 2024



Multi-modal Large Language Models (MLLMs) have shown impressive abilities in generating reasonable responses with respect to multi-modal contents. However, there is still a wide gap between the performance of recent MLLM-based applications and the expectation of the broad public, even though the most powerful OpenAI's GPT-4 and Google's Gemini have been deployed. This paper strives to enhance understanding of the gap through the lens of a qualitative study on the generalizability, trustworthiness, and causal reasoning capabilities of recent proprietary and open-source MLLMs across four modalities: ie, text, code, image, and video, ultimately aiming to improve the transparency of MLLMs. We believe these properties are several representative factors that define the reliability of MLLMs, in supporting various downstream applications. To be specific, we evaluate the closed-source GPT-4 and Gemini and 6 open-source LLMs and MLLMs. Overall we evaluate 230 manually designed cases, where the qualitative results are then summarized into 12 scores (ie, 4 modalities times 3 properties). In total, we uncover 14 empirical findings that are useful to understand the capabilities and limitations of both proprietary and open-source MLLMs, towards more reliable downstream multi-modal applications.
Not All Steps are Equal: Efficient Generation with Progressive Diffusion Models
Jan 02, 2024



Diffusion models have demonstrated remarkable efficacy in various generative tasks with the predictive prowess of denoising model. Currently, these models employ a uniform denoising approach across all timesteps. However, the inherent variations in noisy latents at each timestep lead to conflicts during training, constraining the potential of diffusion models. To address this challenge, we propose a novel two-stage training strategy termed Step-Adaptive Training. In the initial stage, a base denoising model is trained to encompass all timesteps. Subsequently, we partition the timesteps into distinct groups, fine-tuning the model within each group to achieve specialized denoising capabilities. Recognizing that the difficulties of predicting noise at different timesteps vary, we introduce a diverse model size requirement. We dynamically adjust the model size for each timestep by estimating task difficulty based on its signal-to-noise ratio before fine-tuning. This adjustment is facilitated by a proxy-based structural importance assessment mechanism, enabling precise and efficient pruning of the base denoising model. Our experiments validate the effectiveness of the proposed training strategy, demonstrating an improvement in the FID score on CIFAR10 by over 0.3 while utilizing only 80\% of the computational resources. This innovative approach not only enhances model performance but also significantly reduces computational costs, opening new avenues for the development and application of diffusion models.
Experiential Co-Learning of Software-Developing Agents
Dec 29, 2023


Recent advancements in large language models (LLMs) have brought significant changes to various domains, especially through LLM-driven autonomous agents. These agents are now capable of collaborating seamlessly, splitting tasks and enhancing accuracy, thus minimizing the need for human involvement. However, these agents often approach a diverse range of tasks in isolation, without benefiting from past experiences. This isolation can lead to repeated mistakes and inefficient trials in task solving. To this end, this paper introduces Experiential Co-Learning, a novel framework in which instructor and assistant agents gather shortcut-oriented experiences from their historical trajectories and use these past experiences for mutual reasoning. This paradigm, enriched with previous experiences, equips agents to more effectively address unseen tasks.
Robust Geometry and Reflectance Disentanglement for 3D Face Reconstruction from Sparse-view Images
Dec 11, 2023



This paper presents a novel two-stage approach for reconstructing human faces from sparse-view images, a task made challenging by the unique geometry and complex skin reflectance of each individual. Our method focuses on decomposing key facial attributes, including geometry, diffuse reflectance, and specular reflectance, from ambient light. Initially, we create a general facial template from a diverse collection of individual faces, capturing essential geometric and reflectance characteristics. Guided by this template, we refine each specific face model in the second stage, which further considers the interaction between geometry and reflectance, as well as the subsurface scattering effects on facial skin. Our method enables the reconstruction of high-quality facial representations from as few as three images, offering improved geometric accuracy and reflectance detail. Through comprehensive evaluations and comparisons, our method demonstrates superiority over existing techniques. Our method effectively disentangles geometry and reflectance components, leading to enhanced quality in synthesizing new views and opening up possibilities for applications such as relighting and reflectance editing. We will make the code publicly available.
You Only Learn One Query: Learning Unified Human Query for Single-Stage Multi-Person Multi-Task Human-Centric Perception
Dec 09, 2023Human-centric perception (e.g. pedetrian detection, segmentation, pose estimation, and attribute analysis) is a long-standing problem for computer vision. This paper introduces a unified and versatile framework (HQNet) for single-stage multi-person multi-task human-centric perception (HCP). Our approach centers on learning a unified human query representation, denoted as Human Query, which captures intricate instance-level features for individual persons and disentangles complex multi-person scenarios. Although different HCP tasks have been well-studied individually, single-stage multi-task learning of HCP tasks has not been fully exploited in the literature due to the absence of a comprehensive benchmark dataset. To address this gap, we propose COCO-UniHuman benchmark dataset to enable model development and comprehensive evaluation. Experimental results demonstrate the proposed method's state-of-the-art performance among multi-task HCP models and its competitive performance compared to task-specific HCP models. Moreover, our experiments underscore Human Query's adaptability to new HCP tasks, thus demonstrating its robust generalization capability. Codes and data will be publicly accessible.