 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoCTS: Automated Correlated Time Series Forecasting -- Extended Version
Dec 21, 2021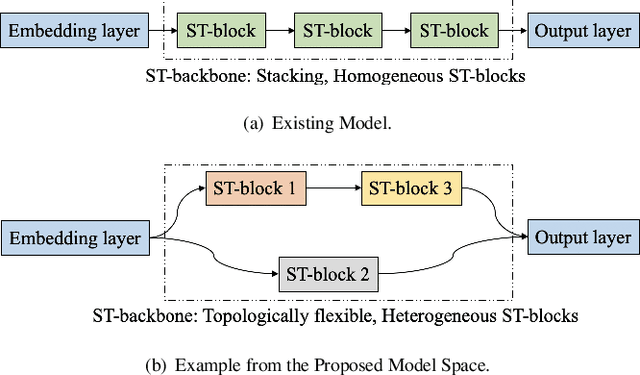
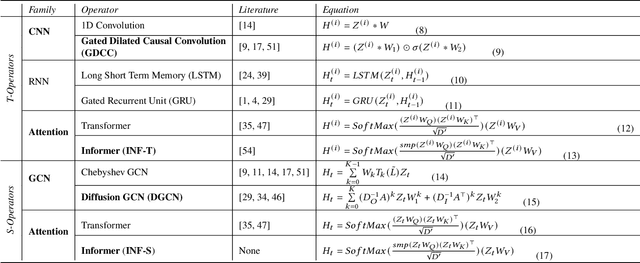
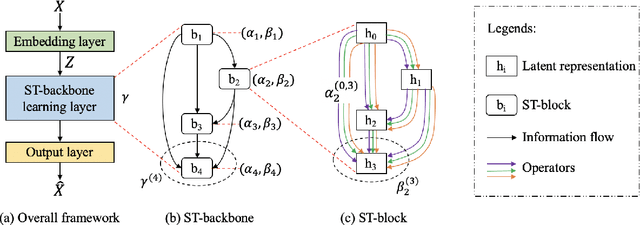

Correlated time series (CTS) forecasting plays an essential role in many cyber-physical systems, where multiple sensors emit time series that capture interconnected processes. Solutions based on deep learning that deliver state-of-the-art CTS forecasting performance employ a variety of spatio-temporal (ST) blocks that are able to model temporal dependencies and spatial correlations among time series. However, two challenges remain. First, ST-blocks are designed manually, which is time consuming and costly. Second, existing forecasting models simply stack the same ST-blocks multiple times, which limits the model potential. To address these challenges, we propose AutoCTS that is able to automatically identify highly competitive ST-blocks as well as forecasting models with heterogeneous ST-blocks connected using diverse topologies, as opposed to the same ST-blocks connected using simple stacking. Specifically, we design both a micro and a macro search space to model possible architectures of ST-blocks and the connections among heterogeneous ST-blocks, and we provide a search strategy that is able to jointly explore the search spaces to identify optimal forecasting models. Extensive experiments on eight commonly used CTS forecasting benchmark datasets justify our design choices and demonstrate that AutoCTS is capable of automatically discovering forecasting models that outperform state-of-the-art human-designed models. This is an extended version of ``AutoCTS: Automated Correlated Time Series Forecasting'', to appear in PVLDB 2022.
FedCV: A Federated Learning Framework for Diverse Computer Vision Tasks
Nov 22, 2021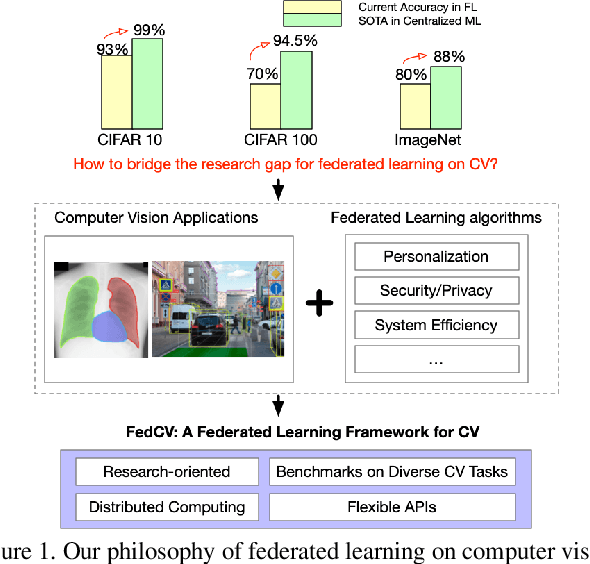
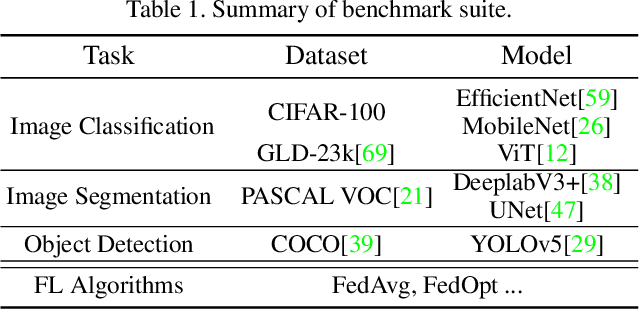
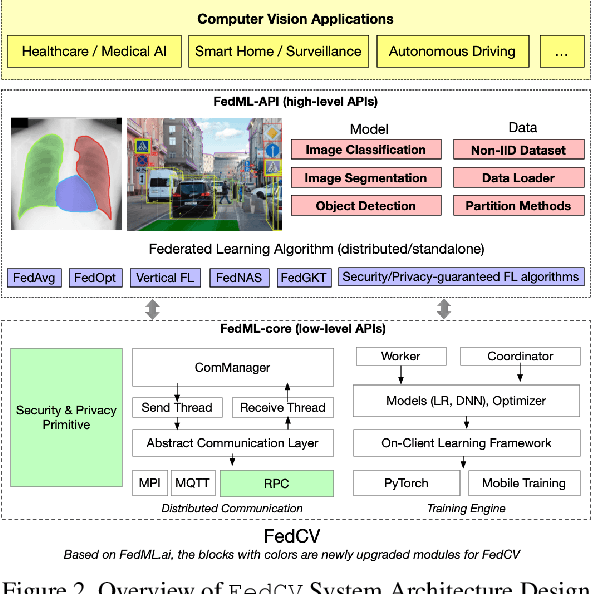
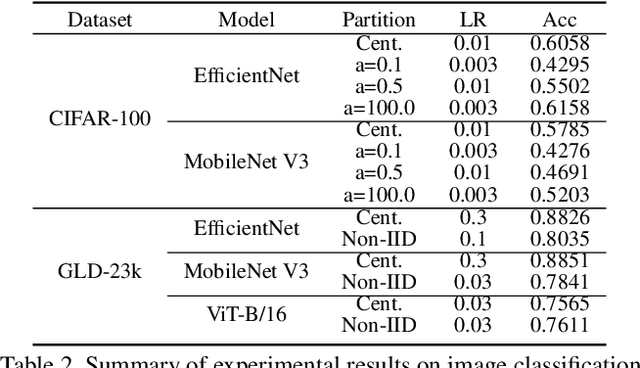
Federated Learning (FL) is a distributed learning paradigm that can learn a global or personalized model from decentralized datasets on edge devices. However, in the computer vision domain, model performance in FL is far behind centralized training due to the lack of exploration in diverse tasks with a unified FL framework. FL has rarely been demonstrated effectively in advanced computer vision tasks such as object detection and image segmentation. To bridge the gap and facilitate the development of FL for computer vision tasks, in this work, we propose a federated learning library and benchmarking framework, named FedCV, to evaluate FL on the three most representative computer vision tasks: image classification, image segmentation, and object detection. We provide non-I.I.D. benchmarking datasets, models, and various reference FL algorithms. Our benchmark study suggests that there are multiple challenges that deserve future exploration: centralized training tricks may not be directly applied to FL; the non-I.I.D. dataset actually downgrades the model accuracy to some degree in different tasks; improving the system efficiency of federated training is challenging given the huge number of parameters and the per-client memory cost. We believe that such a library and benchmark, along with comparable evaluation settings, is necessary to make meaningful progress in FL on computer vision tasks. FedCV is publicly available: https://github.com/FedML-AI/FedCV.
Federated Learning for Internet of Things: Applications, Challenges, and Opportunities
Nov 15, 2021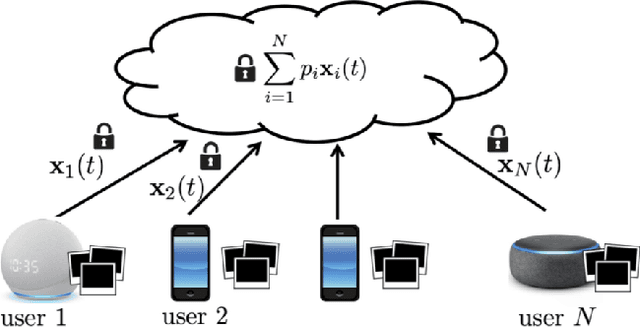
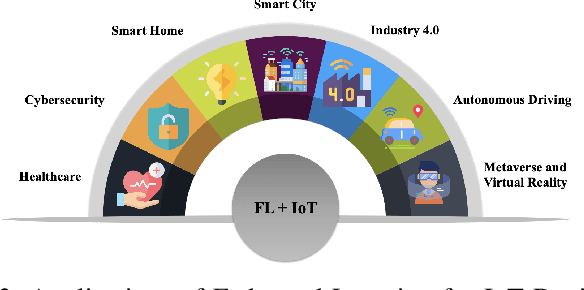
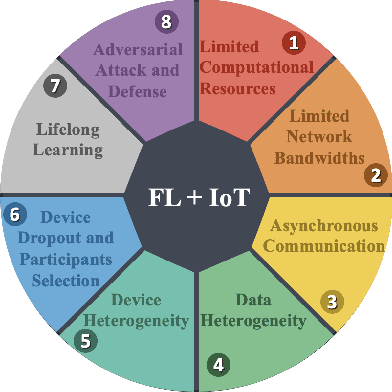
Billions of IoT devices will be deployed in the near future, taking advantage of the faster Internet speed and the possibility of orders of magnitude more endpoints brought by 5G/6G. With the blooming of IoT devices, vast quantities of data that may contain private information of users will be generated. The high communication and storage costs, mixed with privacy concerns, will increasingly be challenging the traditional ecosystem of centralized over-the-cloud learning and processing for IoT platforms. Federated Learning (FL) has emerged as the most promising alternative approach to this problem. In FL, training of data-driven machine learning models is an act of collaboration between multiple clients without requiring the data to be brought to a central point, hence alleviating communication and storage costs and providing a great degree of user-level privacy. We discuss the opportunities and challenges of FL for IoT platforms, as well as how it can enable future IoT applications.
MEST: Accurate and Fast Memory-Economic Sparse Training Framework on the Edge
Oct 26, 2021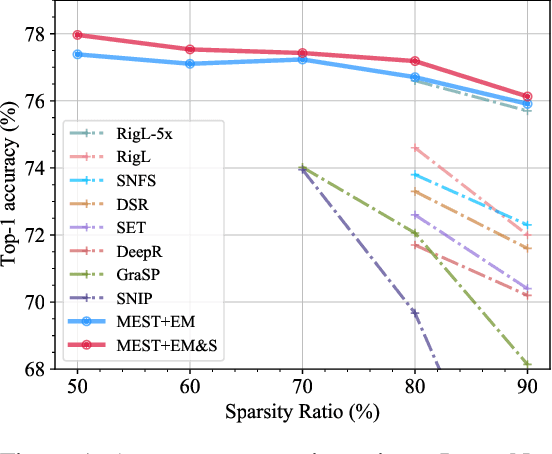
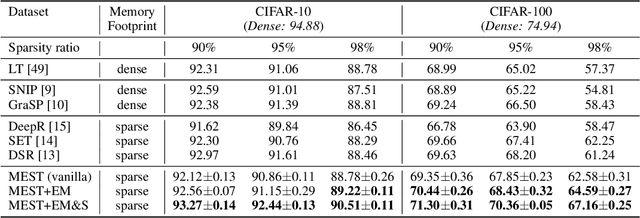
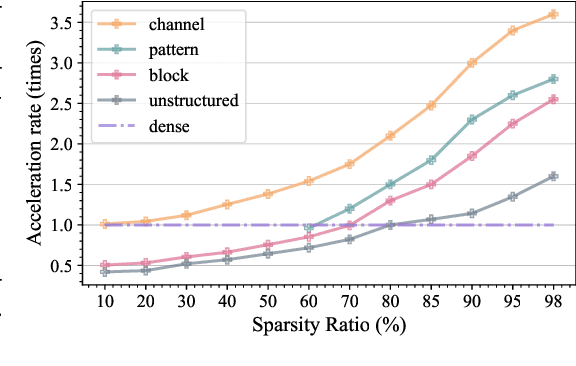
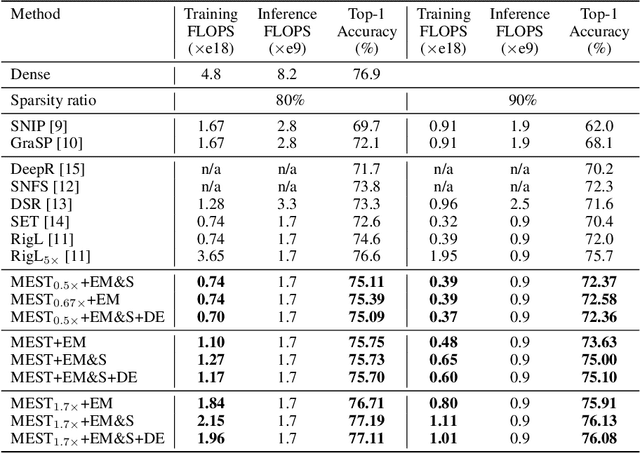
Recently, a new trend of exploring sparsity for accelerating neural network training has emerged, embracing the paradigm of training on the edge. This paper proposes a novel Memory-Economic Sparse Training (MEST) framework targeting for accurate and fast execution on edge devices. The proposed MEST framework consists of enhancements by Elastic Mutation (EM) and Soft Memory Bound (&S) that ensure superior accuracy at high sparsity ratios. Different from the existing works for sparse training, this current work reveals the importance of sparsity schemes on the performance of sparse training in terms of accuracy as well as training speed on real edge devices. On top of that, the paper proposes to employ data efficiency for further acceleration of sparse training. Our results suggest that unforgettable examples can be identified in-situ even during the dynamic exploration of sparsity masks in the sparse training process, and therefore can be removed for further training speedup on edge devices. Comparing with state-of-the-art (SOTA) works on accuracy, our MEST increases Top-1 accuracy significantly on ImageNet when using the same unstructured sparsity scheme. Systematical evaluation on accuracy, training speed, and memory footprint are conducted, where the proposed MEST framework consistently outperforms representative SOTA works. A reviewer strongly against our work based on his false assumptions and misunderstandings. On top of the previous submission, we employ data efficiency for further acceleration of sparse training. And we explore the impact of model sparsity, sparsity schemes, and sparse training algorithms on the number of removable training examples. Our codes are publicly available at: https://github.com/boone891214/MEST.
Layer-wise Adaptive Model Aggregation for Scalable Federated Learning
Oct 19, 2021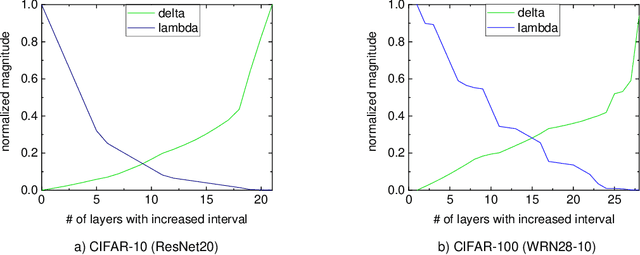

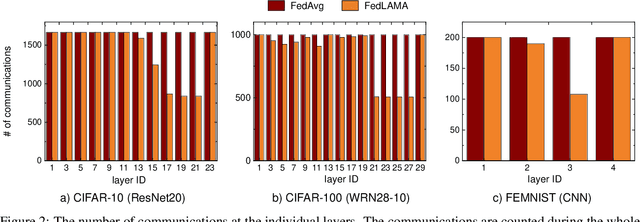

In Federated Learning, a common approach for aggregating local models across clients is periodic averaging of the full model parameters. It is, however, known that different layers of neural networks can have a different degree of model discrepancy across the clients. The conventional full aggregation scheme does not consider such a difference and synchronizes the whole model parameters at once, resulting in inefficient network bandwidth consumption. Aggregating the parameters that are similar across the clients does not make meaningful training progress while increasing the communication cost. We propose FedLAMA, a layer-wise model aggregation scheme for scalable Federated Learning. FedLAMA adaptively adjusts the aggregation interval in a layer-wise manner, jointly considering the model discrepancy and the communication cost. The layer-wise aggregation method enables to finely control the aggregation interval to relax the aggregation frequency without a significant impact on the model accuracy. Our empirical study shows that FedLAMA reduces the communication cost by up to 60% for IID data and 70% for non-IID data while achieving a comparable accuracy to FedAvg.
SSFL: Tackling Label Deficiency in Federated Learning via Personalized Self-Supervision
Oct 06, 2021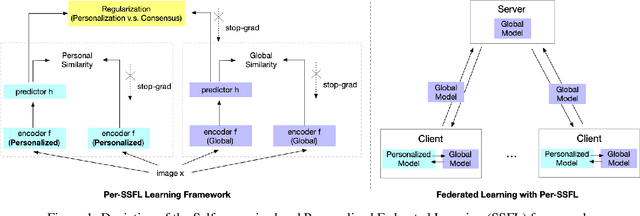

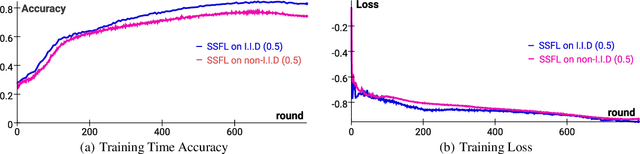
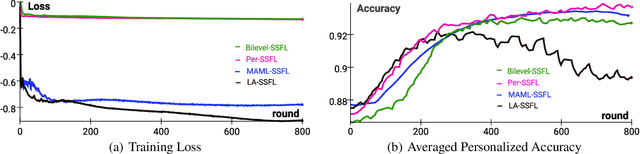
Federated Learning (FL) is transforming the ML training ecosystem from a centralized over-the-cloud setting to distributed training over edge devices in order to strengthen data privacy. An essential but rarely studied challenge in FL is label deficiency at the edge. This problem is even more pronounced in FL compared to centralized training due to the fact that FL users are often reluctant to label their private data. Furthermore, due to the heterogeneous nature of the data at edge devices, it is crucial to develop personalized models. In this paper we propose self-supervised federated learning (SSFL), a unified self-supervised and personalized federated learning framework, and a series of algorithms under this framework which work towards addressing these challenges. First, under the SSFL framework, we demonstrate that the standard FedAvg algorithm is compatible with recent breakthroughs in centralized self-supervised learning such as SimSiam networks. Moreover, to deal with data heterogeneity at the edge devices in this framework, we have innovated a series of algorithms that broaden existing supervised personalization algorithms into the setting of self-supervised learning. We further propose a novel personalized federated self-supervised learning algorithm, Per-SSFL, which balances personalization and consensus by carefully regulating the distance between the local and global representations of data. To provide a comprehensive comparative analysis of all proposed algorithms, we also develop a distributed training system and related evaluation protocol for SSFL. Our findings show that the gap of evaluation accuracy between supervised learning and unsupervised learning in FL is both small and reasonable. The performance comparison indicates the representation regularization-based personalization method is able to outperform other variants.
FairFed: Enabling Group Fairness in Federated Learning
Oct 02, 2021
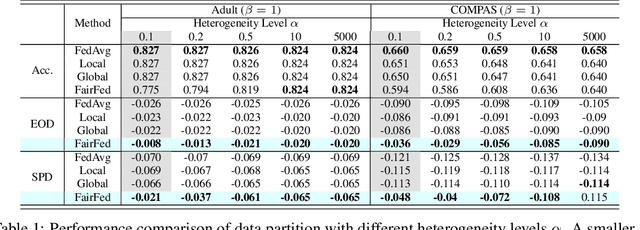
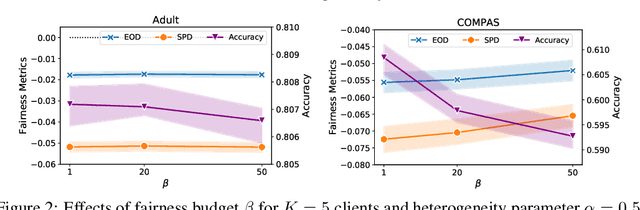
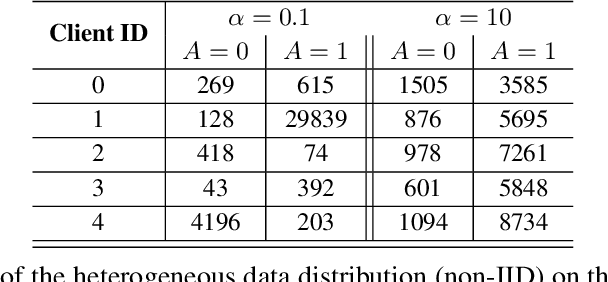
As machine learning becomes increasingly incorporated in crucial decision-making scenarios such as healthcare, recruitment, and loan assessment, there have been increasing concerns about the privacy and fairness of such systems. Federated learning has been viewed as a promising solution for collaboratively learning machine learning models among multiple parties while maintaining the privacy of their local data. However, federated learning also poses new challenges in mitigating the potential bias against certain populations (e.g., demographic groups), which typically requires centralized access to the sensitive information (e.g., race, gender) of each data point. Motivated by the importance and challenges of group fairness in federated learning, in this work, we propose FairFed, a novel algorithm to enhance group fairness via a fairness-aware aggregation method, aiming to provide fair model performance across different sensitive groups (e.g., racial, gender groups) while maintaining high utility. The formulation can potentially provide more flexibility in the customized local debiasing strategies for each client. When running federated training on two widely investigated fairness datasets, Adult and COMPAS, our proposed method outperforms the state-of-the-art fair federated learning frameworks under a high heterogeneous sensitive attribute distribution.
LightSecAgg: Rethinking Secure Aggregation in Federated Learning
Sep 29, 2021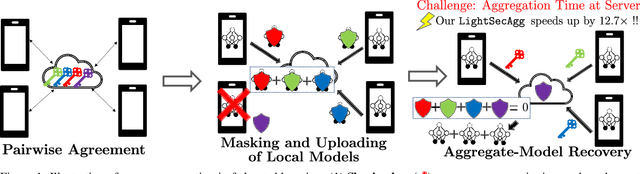
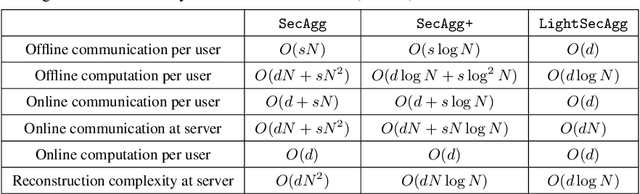
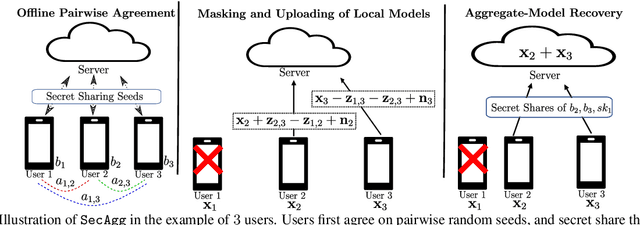
Secure model aggregation is a key component of federated learning (FL) that aims at protecting the privacy of each user's individual model, while allowing their global aggregation. It can be applied to any aggregation-based approaches, including algorithms for training a global model, as well as personalized FL frameworks. Model aggregation needs to also be resilient to likely user dropouts in FL system, making its design substantially more complex. State-of-the-art secure aggregation protocols essentially rely on secret sharing of the random-seeds that are used for mask generations at the users, in order to enable the reconstruction and cancellation of those belonging to dropped users. The complexity of such approaches, however, grows substantially with the number of dropped users. We propose a new approach, named LightSecAgg, to overcome this bottleneck by turning the focus from "random-seed reconstruction of the dropped users" to "one-shot aggregate-mask reconstruction of the active users". More specifically, in LightSecAgg each user protects its local model by generating a single random mask. This mask is then encoded and shared to other users, in such a way that the aggregate-mask of any sufficiently large set of active users can be reconstructed directly at the server via encoded masks. We show that LightSecAgg achieves the same privacy and dropout-resiliency guarantees as the state-of-the-art protocols, while significantly reducing the overhead for resiliency to dropped users. Furthermore, our system optimization helps to hide the runtime cost of offline processing by parallelizing it with model training. We evaluate LightSecAgg via extensive experiments for training diverse models on various datasets in a realistic FL system, and demonstrate that LightSecAgg significantly reduces the total training time, achieving a performance gain of up to $12.7\times$ over baselines.
A Field Guide to Federated Optimization
Jul 14, 2021


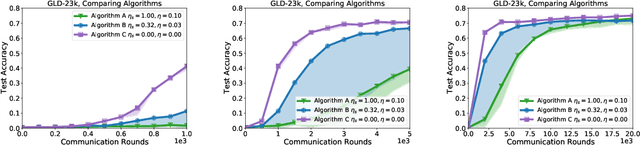
Federated learning and analytics are a distributed approach for collaboratively learning models (or statistics) from decentralized data, motivated by and designed for privacy protection. The distributed learning process can be formulated as solving federated optimization problems, which emphasize communication efficiency, data heterogeneity, compatibility with privacy and system requirements, and other constraints that are not primary considerations in other problem settings. This paper provides recommendations and guidelines on formulating, designing, evaluating and analyzing federated optimization algorithms through concrete examples and practical implementation, with a focus on conducting effective simulations to infer real-world performance. The goal of this work is not to survey the current literature, but to inspire researchers and practitioners to design federated learning algorithms that can be used in various practical applications.
Federated Learning for Internet of Things: A Federated Learning Framework for On-device Anomaly Data Detection
Jun 15, 2021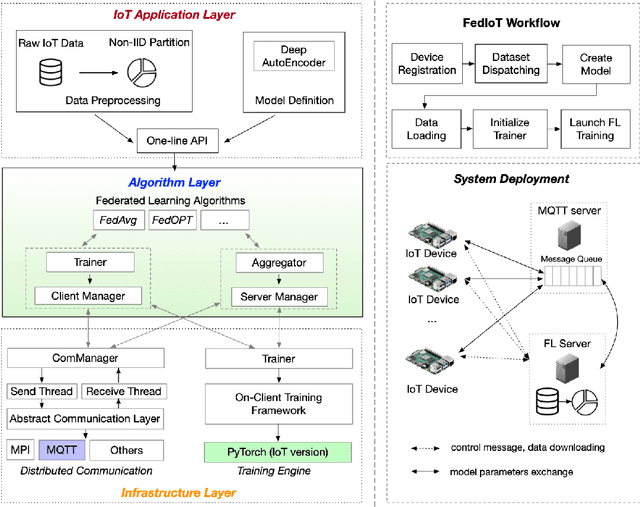
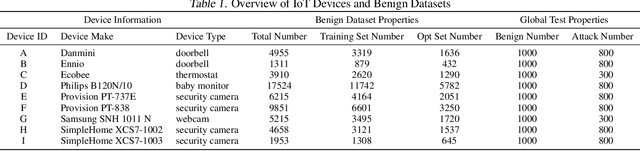

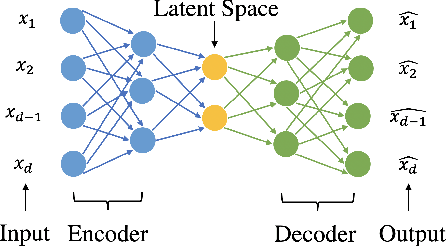
Federated learning can be a promising solution for enabling IoT cybersecurity (i.e., anomaly detection in the IoT environment) while preserving data privacy and mitigating the high communication/storage overhead (e.g., high-frequency data from time-series sensors) of centralized over-the-cloud approaches. In this paper, to further push forward this direction with a comprehensive study in both algorithm and system design, we build FedIoT platform that contains a synthesized dataset using N-BaIoT, FedDetect algorithm, and a system design for IoT devices. Furthermore, the proposed FedDetect learning framework improves the performance by utilizing an adaptive optimizer (e.g., Adam) and a cross-round learning rate scheduler. In a network of realistic IoT devices (Raspberry PI), we evaluate FedIoT platform and FedDetect algorithm in both model and system performance. Our results demonstrate the efficacy of federated learning in detecting a large range of attack types. The system efficiency analysis indicates that both end-to-end training time and memory cost are affordable and promising for resource-constrained IoT devices. The source code is publicly available.