 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLing and Ring 2.6 Technical Report: Efficient and Instant Agentic Intelligence at Trillion-Parameter Scale
Jun 13, 2026Efficient and scalable agentic intelligence requires models that can deliver both low-latency responses and strong reasoning capabilities while remaining practical to train, serve, and deploy. In this report, we present Ling-2.6 and Ring-2.6, a family of models designed to address this challenge at scale. Ling-2.6 is optimized for instant response generation and high capability per output token, whereas Ring-2.6 is tailored for deeper reasoning and more advanced agentic workflows. Instead of training from scratch, we upgrade the Ling-2.0 base model through architectural migration pre-training and large-scale post-training. This upgrade is guided by a unified co-design of model architecture, optimization objectives, serving systems, and agent training environments, enabling improvements in both model capability and deployment efficiency. At the architectural level, we introduce a hybrid linear attention design that integrates Lightning Attention with MLA, improving the efficiency of long-context training and decoding. To further enhance token efficiency, we optimize capability per output token through Evolutionary Chain-of-Thought, Linguistic Unit Policy Optimization, bidirectional preference alignment, and shortest-correct-response distillation. For agentic capabilities, we propose KPop, a reinforcement learning framework designed to support stable training of Ring-2.6-1T on large-scale environment-grounded data. KPop improves training efficiency through asynchronous scheduling across coding, search, tool use, and workflow execution, enabling scalable learning from complex agent-environment interactions. Together, Ling-2.6 and Ring-2.6 provide a practical pathway toward efficient, scalable, and open agentic systems. We open-source all checkpoints in the 2.6 family to support further research and development in practical agentic intelligence.
Video2Sim2Real: Full-Stack Autonomous Dexterous Skill Acquisition from a Single Human Video
Jun 07, 2026Human manipulation videos are a convenient and intuitive source for robot learning. However, directly transferring human dexterity to robots remains challenging due to perception errors and embodiment gap. To address this, we introduce Video2Sim2Real, a full-stack framework for autonomous skill acquisition from a single human manipulation video. Our framework first uses off-the-shelf foundation models to reconstruct a simulator-ready digital twin and extract robot and object motion priors. Rather than treating the extracted robot motion as a reliable reference throughout execution, our key idea is to recover and leverage the most fundamental sources of supervision from the demonstrated skill: We identify object-centric keyframes to optimize the corresponding robot configurations using object information from the simulator, and use these configurations as anchors that refine the robot motion such that it ultimately has the desired impact on the environment. To bridge the remaining sim-to-real gap, we introduce a sim-to-real strategy that decouples robustness to noisy and incomplete perception from variations in hand-object interaction dynamics. Specifically, we learn to recalibrate robot configurations from noisy real-world point clouds via IL, and leverage residual RL to perform local finger-level adaptations to ensure for robust and effective interactions. Finally, a collision-aware motion planning module enables spatial generalization to novel object configurations. Across several everyday manipulation tasks, Video2Sim2Real improves simulated task success, safety, and trajectory coherence over numerous baselines, and achieves better sim-to-real transfer than existing techniques. These results demonstrate a promising path toward autonomous dexterous skill acquisition from human videos.
Hidden in Plain Sight: Visual-to-Symbolic Analytical Solution Inference from Field Visualizations
Apr 10, 2026Recovering analytical solutions of physical fields from visual observations is a fundamental yet underexplored capability for AI-assisted scientific reasoning. We study visual-to-symbolic analytical solution inference (ViSA) for two-dimensional linear steady-state fields: given field visualizations (and first-order derivatives) plus minimal auxiliary metadata, the model must output a single executable SymPy expression with fully instantiated numeric constants. We introduce ViSA-R2 and align it with a self-verifying, solution-centric chain-of-thought pipeline that follows a physicist-like pathway: structural pattern recognition solution-family (ansatz) hypothesis parameter derivation consistency verification. We also release ViSA-Bench, a VLM-ready synthetic benchmark covering 30 linear steady-state scenarios with verifiable analytical/symbolic annotations, and evaluate predictions by numerical accuracy, expression-structure similarity, and character-level accuracy. Using an 8B open-weight Qwen3-VL backbone, ViSA-R2 outperforms strong open-source baselines and the evaluated closed-source frontier VLMs under a standardized protocol.
AI-for-Science Low-code Platform with Bayesian Adversarial Multi-Agent Framework
Mar 03, 2026Large Language Models (LLMs) demonstrate potentials for automating scientific code generation but face challenges in reliability, error propagation in multi-agent workflows, and evaluation in domains with ill-defined success metrics. We present a Bayesian adversarial multi-agent framework specifically designed for AI for Science (AI4S) tasks in the form of a Low-code Platform (LCP). Three LLM-based agents are coordinated under the Bayesian framework: a Task Manager that structures user inputs into actionable plans and adaptive test cases, a Code Generator that produces candidate solutions, and an Evaluator providing comprehensive feedback. The framework employs an adversarial loop where the Task Manager iteratively refines test cases to challenge the Code Generator, while prompt distributions are dynamically updated using Bayesian principles by integrating code quality metrics: functional correctness, structural alignment, and static analysis. This co-optimization of tests and code reduces dependence on LLM reliability and addresses evaluation uncertainty inherent to scientific tasks. LCP also streamlines human-AI collaboration by translating non-expert prompts into domain-specific requirements, bypassing the need for manual prompt engineering by practitioners without coding backgrounds. Benchmark evaluations demonstrate LCP's effectiveness in generating robust code while minimizing error propagation. The proposed platform is also tested on an Earth Science cross-disciplinary task and demonstrates strong reliability, outperforming competing models.
FedNLP: A Research Platform for Federated Learning in Natural Language Processing
Apr 18, 2021
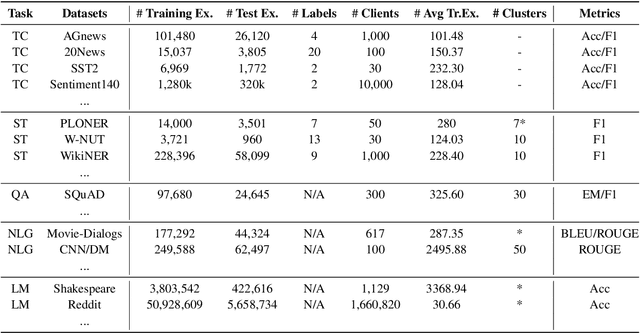
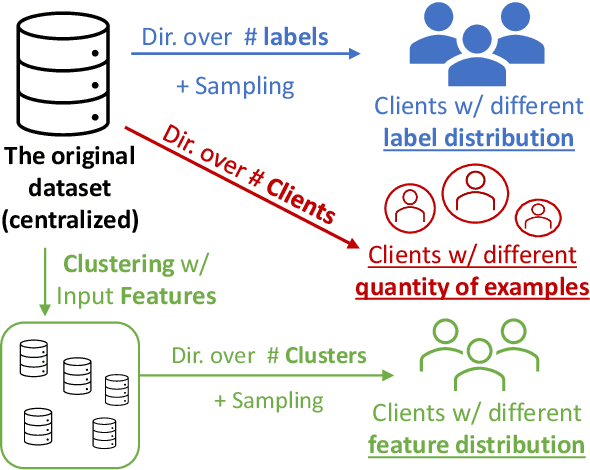
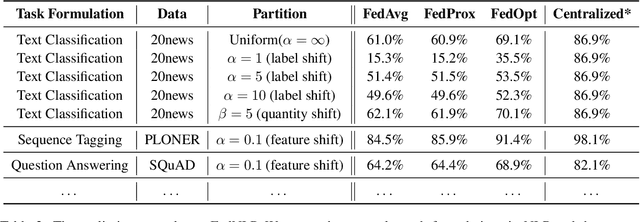
Increasing concerns and regulations about data privacy, necessitate the study of privacy-preserving methods for natural language processing (NLP) applications. Federated learning (FL) provides promising methods for a large number of clients (i.e., personal devices or organizations) to collaboratively learn a shared global model to benefit all clients, while allowing users to keep their data locally. To facilitate FL research in NLP, we present the FedNLP, a research platform for federated learning in NLP. FedNLP supports various popular task formulations in NLP such as text classification, sequence tagging, question answering, seq2seq generation, and language modeling. We also implement an interface between Transformer language models (e.g., BERT) and FL methods (e.g., FedAvg, FedOpt, etc.) for distributed training. The evaluation protocol of this interface supports a comprehensive collection of non-IID partitioning strategies. Our preliminary experiments with FedNLP reveal that there exists a large performance gap between learning on decentralized and centralized datasets -- opening intriguing and exciting future research directions aimed at developing FL methods suited to NLP tasks.