 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUSIC: MUlti-Step Instruction Contrast for Multi-Turn Reward Models
Dec 31, 2025Evaluating the quality of multi-turn conversations is crucial for developing capable Large Language Models (LLMs), yet remains a significant challenge, often requiring costly human evaluation. Multi-turn reward models (RMs) offer a scalable alternative and can provide valuable signals for guiding LLM training. While recent work has advanced multi-turn \textit{training} techniques, effective automated \textit{evaluation} specifically for multi-turn interactions lags behind. We observe that standard preference datasets, typically contrasting responses based only on the final conversational turn, provide insufficient signal to capture the nuances of multi-turn interactions. Instead, we find that incorporating contrasts spanning \textit{multiple} turns is critical for building robust multi-turn RMs. Motivated by this finding, we propose \textbf{MU}lti-\textbf{S}tep \textbf{I}nstruction \textbf{C}ontrast (MUSIC), an unsupervised data augmentation strategy that synthesizes contrastive conversation pairs exhibiting differences across multiple turns. Leveraging MUSIC on the Skywork preference dataset, we train a multi-turn RM based on the Gemma-2-9B-Instruct model. Empirical results demonstrate that our MUSIC-augmented RM outperforms baseline methods, achieving higher alignment with judgments from advanced proprietary LLM judges on multi-turn conversations, crucially, without compromising performance on standard single-turn RM benchmarks.
Fantastic Reasoning Behaviors and Where to Find Them: Unsupervised Discovery of the Reasoning Process
Dec 30, 2025Despite the growing reasoning capabilities of recent large language models (LLMs), their internal mechanisms during the reasoning process remain underexplored. Prior approaches often rely on human-defined concepts (e.g., overthinking, reflection) at the word level to analyze reasoning in a supervised manner. However, such methods are limited, as it is infeasible to capture the full spectrum of potential reasoning behaviors, many of which are difficult to define in token space. In this work, we propose an unsupervised framework (namely, RISE: Reasoning behavior Interpretability via Sparse auto-Encoder) for discovering reasoning vectors, which we define as directions in the activation space that encode distinct reasoning behaviors. By segmenting chain-of-thought traces into sentence-level 'steps' and training sparse auto-encoders (SAEs) on step-level activations, we uncover disentangled features corresponding to interpretable behaviors such as reflection and backtracking. Visualization and clustering analyses show that these behaviors occupy separable regions in the decoder column space. Moreover, targeted interventions on SAE-derived vectors can controllably amplify or suppress specific reasoning behaviors, altering inference trajectories without retraining. Beyond behavior-specific disentanglement, SAEs capture structural properties such as response length, revealing clusters of long versus short reasoning traces. More interestingly, SAEs enable the discovery of novel behaviors beyond human supervision. We demonstrate the ability to control response confidence by identifying confidence-related vectors in the SAE decoder space. These findings underscore the potential of unsupervised latent discovery for both interpreting and controllably steering reasoning in LLMs.
Eliciting Behaviors in Multi-Turn Conversations
Dec 29, 2025Identifying specific and often complex behaviors from large language models (LLMs) in conversational settings is crucial for their evaluation. Recent work proposes novel techniques to find natural language prompts that induce specific behaviors from a target model, yet they are mainly studied in single-turn settings. In this work, we study behavior elicitation in the context of multi-turn conversations. We first offer an analytical framework that categorizes existing methods into three families based on their interactions with the target model: those that use only prior knowledge, those that use offline interactions, and those that learn from online interactions. We then introduce a generalized multi-turn formulation of the online method, unifying single-turn and multi-turn elicitation. We evaluate all three families of methods on automatically generating multi-turn test cases. We investigate the efficiency of these approaches by analyzing the trade-off between the query budget, i.e., the number of interactions with the target model, and the success rate, i.e., the discovery rate of behavior-eliciting inputs. We find that online methods can achieve an average success rate of 45/19/77% with just a few thousand queries over three tasks where static methods from existing multi-turn conversation benchmarks find few or even no failure cases. Our work highlights a novel application of behavior elicitation methods in multi-turn conversation evaluation and the need for the community to move towards dynamic benchmarks.
Principled Foundations for Preference Optimization
Jul 10, 2025In this paper, we show that direct preference optimization (DPO) is a very specific form of a connection between two major theories in the ML context of learning from preferences: loss functions (Savage) and stochastic choice (Doignon-Falmagne and Machina). The connection is established for all of Savage's losses and at this level of generality, (i) it includes support for abstention on the choice theory side, (ii) it includes support for non-convex objectives on the ML side, and (iii) it allows to frame for free some notable extensions of the DPO setting, including margins and corrections for length. Getting to understand how DPO operates from a general principled perspective is crucial because of the huge and diverse application landscape of models, because of the current momentum around DPO, but also -- and importantly -- because many state of the art variations on DPO definitely occupy a small region of the map that we cover. It also helps to understand the pitfalls of departing from this map, and figure out workarounds.
Learning from straggler clients in federated learning
Mar 14, 2024



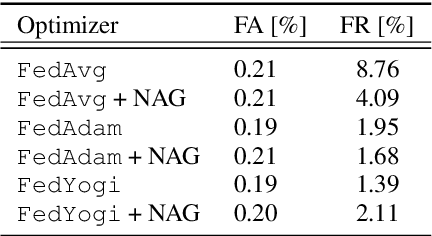
How well do existing federated learning algorithms learn from client devices that return model updates with a significant time delay? Is it even possible to learn effectively from clients that report back minutes, hours, or days after being scheduled? We answer these questions by developing Monte Carlo simulations of client latency that are guided by real-world applications. We study synchronous optimization algorithms like FedAvg and FedAdam as well as the asynchronous FedBuff algorithm, and observe that all these existing approaches struggle to learn from severely delayed clients. To improve upon this situation, we experiment with modifications, including distillation regularization and exponential moving averages of model weights. Finally, we introduce two new algorithms, FARe-DUST and FeAST-on-MSG, based on distillation and averaging, respectively. Experiments with the EMNIST, CIFAR-100, and StackOverflow benchmark federated learning tasks demonstrate that our new algorithms outperform existing ones in terms of accuracy for straggler clients, while also providing better trade-offs between training time and total accuracy.
Mixed Federated Learning: Joint Decentralized and Centralized Learning
May 26, 2022
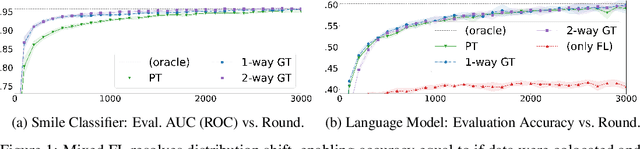
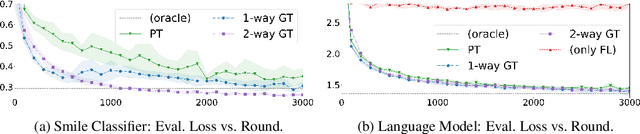
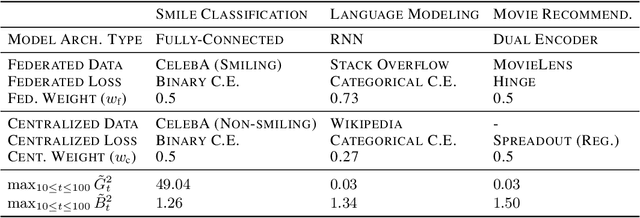
Federated learning (FL) enables learning from decentralized privacy-sensitive data, with computations on raw data confined to take place at edge clients. This paper introduces mixed FL, which incorporates an additional loss term calculated at the coordinating server (while maintaining FL's private data restrictions). There are numerous benefits. For example, additional datacenter data can be leveraged to jointly learn from centralized (datacenter) and decentralized (federated) training data and better match an expected inference data distribution. Mixed FL also enables offloading some intensive computations (e.g., embedding regularization) to the server, greatly reducing communication and client computation load. For these and other mixed FL use cases, we present three algorithms: PARALLEL TRAINING, 1-WAY GRADIENT TRANSFER, and 2-WAY GRADIENT TRANSFER. We state convergence bounds for each, and give intuition on which are suited to particular mixed FL problems. Finally we perform extensive experiments on three tasks, demonstrating that mixed FL can blend training data to achieve an oracle's accuracy on an inference distribution, and can reduce communication and computation overhead by over 90%. Our experiments confirm theoretical predictions of how algorithms perform under different mixed FL problem settings.
Production federated keyword spotting via distillation, filtering, and joint federated-centralized training
Apr 11, 2022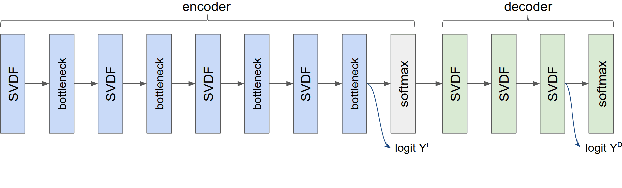
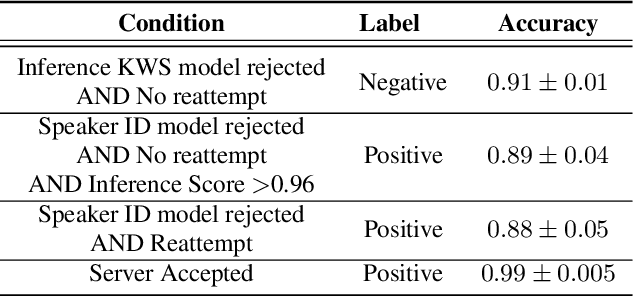

We trained a keyword spotting model using federated learning on real user devices and observed significant improvements when the model was deployed for inference on phones. To compensate for data domains that are missing from on-device training caches, we employed joint federated-centralized training. And to learn in the absence of curated labels on-device, we formulated a confidence filtering strategy based on user-feedback signals for federated distillation. These techniques created models that significantly improved quality metrics in offline evaluations and user-experience metrics in live A/B experiments.
Jointly Learning from Decentralized (Federated) and Centralized Data to Mitigate Distribution Shift
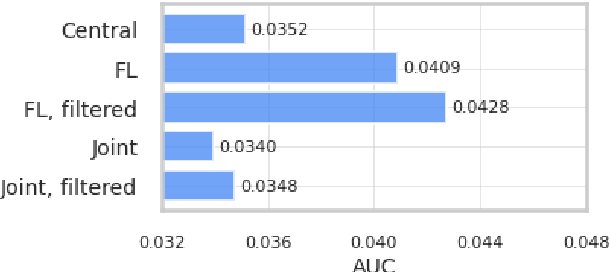
Nov 23, 2021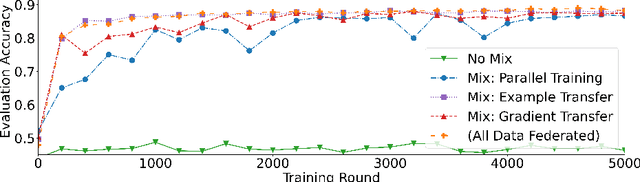
With privacy as a motivation, Federated Learning (FL) is an increasingly used paradigm where learning takes place collectively on edge devices, each with a cache of user-generated training examples that remain resident on the local device. These on-device training examples are gathered in situ during the course of users' interactions with their devices, and thus are highly reflective of at least part of the inference data distribution. Yet a distribution shift may still exist; the on-device training examples may lack for some data inputs expected to be encountered at inference time. This paper proposes a way to mitigate this shift: selective usage of datacenter data, mixed in with FL. By mixing decentralized (federated) and centralized (datacenter) data, we can form an effective training data distribution that better matches the inference data distribution, resulting in more useful models while still meeting the private training data access constraints imposed by FL.
A Field Guide to Federated Optimization
Jul 14, 2021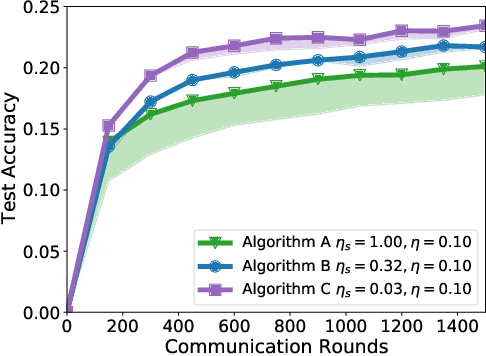


Federated learning and analytics are a distributed approach for collaboratively learning models (or statistics) from decentralized data, motivated by and designed for privacy protection. The distributed learning process can be formulated as solving federated optimization problems, which emphasize communication efficiency, data heterogeneity, compatibility with privacy and system requirements, and other constraints that are not primary considerations in other problem settings. This paper provides recommendations and guidelines on formulating, designing, evaluating and analyzing federated optimization algorithms through concrete examples and practical implementation, with a focus on conducting effective simulations to infer real-world performance. The goal of this work is not to survey the current literature, but to inspire researchers and practitioners to design federated learning algorithms that can be used in various practical applications.
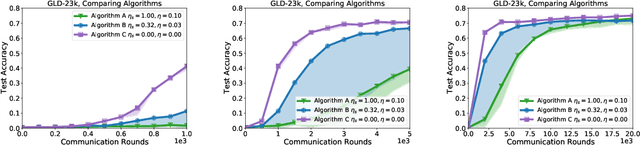
Training Keyword Spotting Models on Non-IID Data with Federated Learning
Jun 04, 2020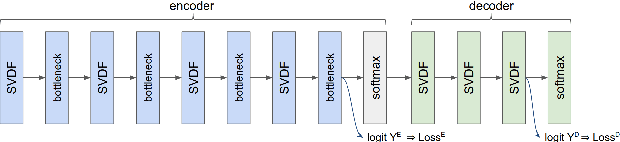

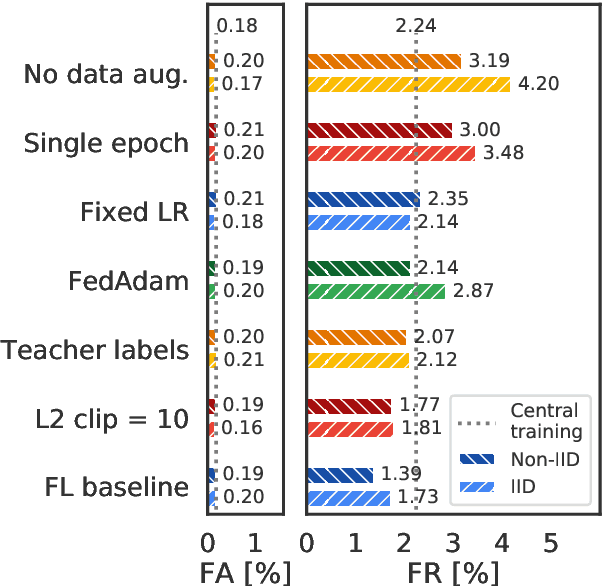
We demonstrate that a production-quality keyword-spotting model can be trained on-device using federated learning and achieve comparable false accept and false reject rates to a centrally-trained model. To overcome the algorithmic constraints associated with fitting on-device data (which are inherently non-independent and identically distributed), we conduct thorough empirical studies of optimization algorithms and hyperparameter configurations using large-scale federated simulations. To overcome resource constraints, we replace memory intensive MTR data augmentation with SpecAugment, which reduces the false reject rate by 56%. Finally, to label examples (given the zero visibility into on-device data), we explore teacher-student training.