 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFALCON: An ML Framework for Fully Automated Layout-Constrained Analog Circuit Design
May 28, 2025Designing analog circuits from performance specifications is a complex, multi-stage process encompassing topology selection, parameter inference, and layout feasibility. We introduce FALCON, a unified machine learning framework that enables fully automated, specification-driven analog circuit synthesis through topology selection and layout-constrained optimization. Given a target performance, FALCON first selects an appropriate circuit topology using a performance-driven classifier guided by human design heuristics. Next, it employs a custom, edge-centric graph neural network trained to map circuit topology and parameters to performance, enabling gradient-based parameter inference through the learned forward model. This inference is guided by a differentiable layout cost, derived from analytical equations capturing parasitic and frequency-dependent effects, and constrained by design rules. We train and evaluate FALCON on a large-scale custom dataset of 1M analog mm-wave circuits, generated and simulated using Cadence Spectre across 20 expert-designed topologies. Through this evaluation, FALCON demonstrates >99\% accuracy in topology inference, <10\% relative error in performance prediction, and efficient layout-aware design that completes in under 1 second per instance. Together, these results position FALCON as a practical and extensible foundation model for end-to-end analog circuit design automation.
One Model to Unite Them All: Personalized Federated Learning of Multi-Contrast MRI Synthesis
Jul 13, 2022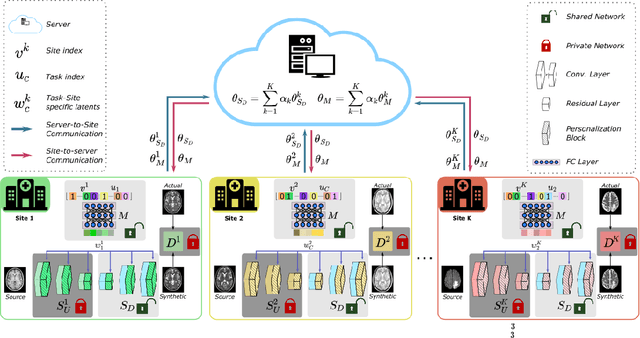
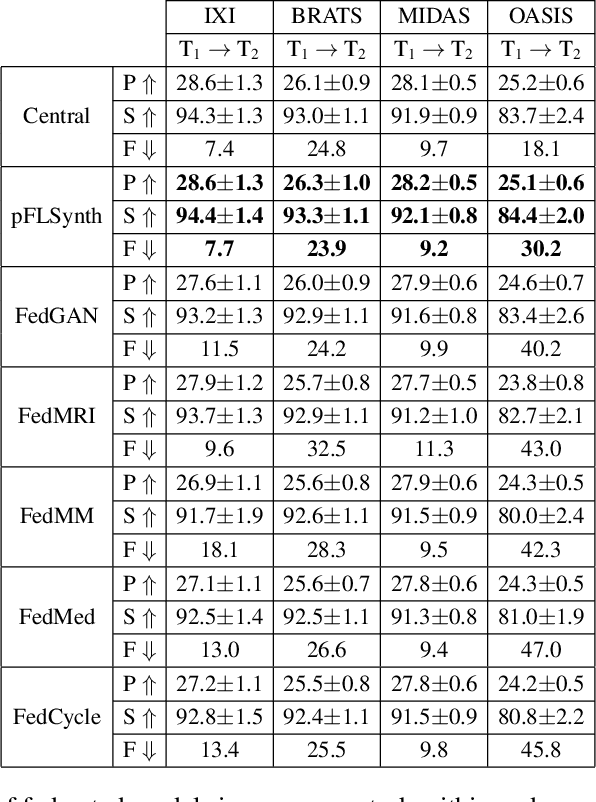
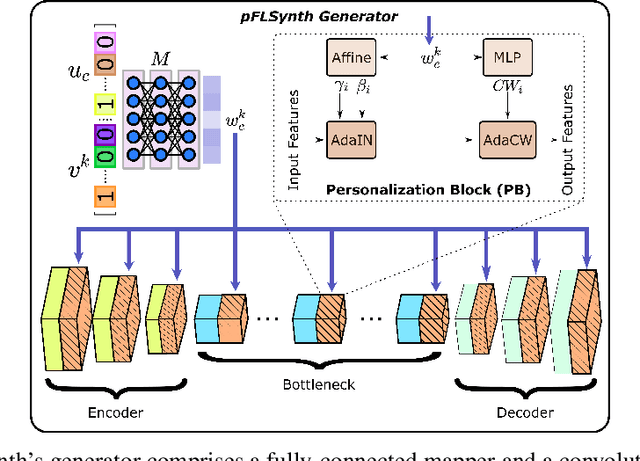
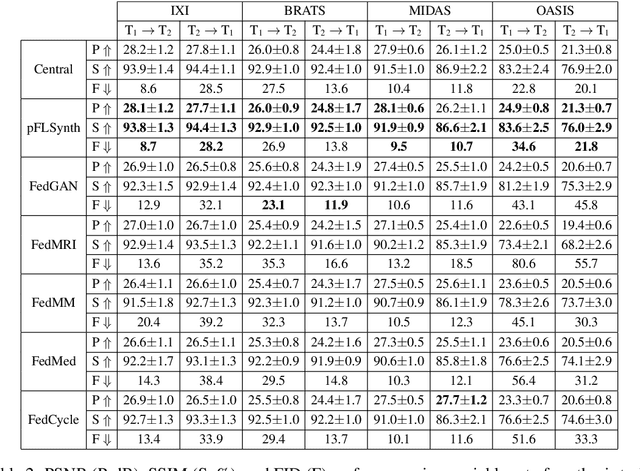
Learning-based MRI translation involves a synthesis model that maps a source-contrast onto a target-contrast image. Multi-institutional collaborations are key to training synthesis models across broad datasets, yet centralized training involves privacy risks. Federated learning (FL) is a collaboration framework that instead adopts decentralized training to avoid sharing imaging data and mitigate privacy concerns. However, FL-trained models can be impaired by the inherent heterogeneity in the distribution of imaging data. On the one hand, implicit shifts in image distribution are evident across sites, even for a common translation task with fixed source-target configuration. Conversely, explicit shifts arise within and across sites when diverse translation tasks with varying source-target configurations are prescribed. To improve reliability against domain shifts, here we introduce the first personalized FL method for MRI Synthesis (pFLSynth). pFLSynth is based on an adversarial model equipped with a mapper that produces latents specific to individual sites and source-target contrasts. It leverages novel personalization blocks that adaptively tune the statistics and weighting of feature maps across the generator based on these latents. To further promote site-specificity, partial model aggregation is employed over downstream layers of the generator while upstream layers are retained locally. As such, pFLSynth enables training of a unified synthesis model that can reliably generalize across multiple sites and translation tasks. Comprehensive experiments on multi-site datasets clearly demonstrate the enhanced performance of pFLSynth against prior federated methods in multi-contrast MRI synthesis.
Federated Learning of Generative Image Priors for MRI Reconstruction
Feb 08, 2022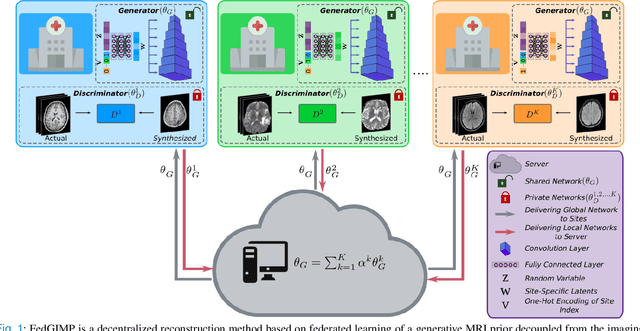
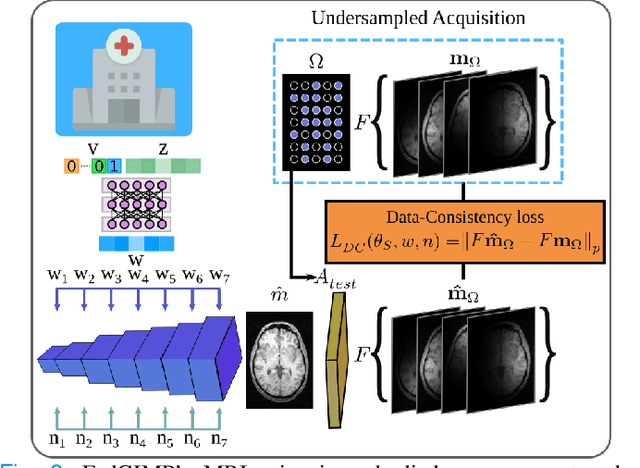
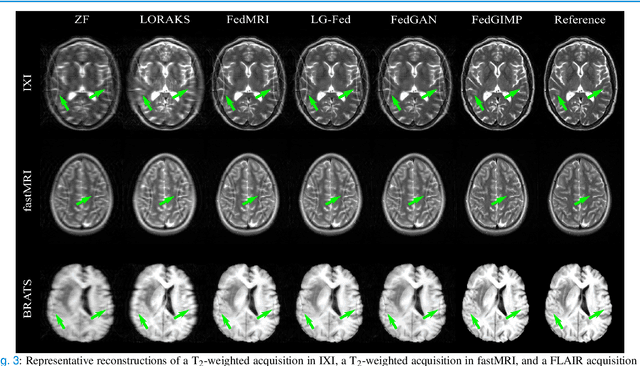
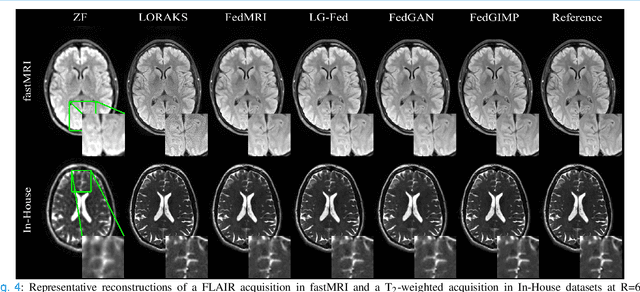
Multi-institutional efforts can facilitate training of deep MRI reconstruction models, albeit privacy risks arise during cross-site sharing of imaging data. Federated learning (FL) has recently been introduced to address privacy concerns by enabling distributed training without transfer of imaging data. Existing FL methods for MRI reconstruction employ conditional models to map from undersampled to fully-sampled acquisitions via explicit knowledge of the imaging operator. Since conditional models generalize poorly across different acceleration rates or sampling densities, imaging operators must be fixed between training and testing, and they are typically matched across sites. To improve generalization and flexibility in multi-institutional collaborations, here we introduce a novel method for MRI reconstruction based on Federated learning of Generative IMage Priors (FedGIMP). FedGIMP leverages a two-stage approach: cross-site learning of a generative MRI prior, and subject-specific injection of the imaging operator. The global MRI prior is learned via an unconditional adversarial model that synthesizes high-quality MR images based on latent variables. Specificity in the prior is preserved via a mapper subnetwork that produces site-specific latents. During inference, the prior is combined with subject-specific imaging operators to enable reconstruction, and further adapted to individual test samples by minimizing data-consistency loss. Comprehensive experiments on multi-institutional datasets clearly demonstrate enhanced generalization performance of FedGIMP against site-specific and federated methods based on conditional models, as well as traditional reconstruction methods.
SpreadGNN: Serverless Multi-task Federated Learning for Graph Neural Networks
Jun 04, 2021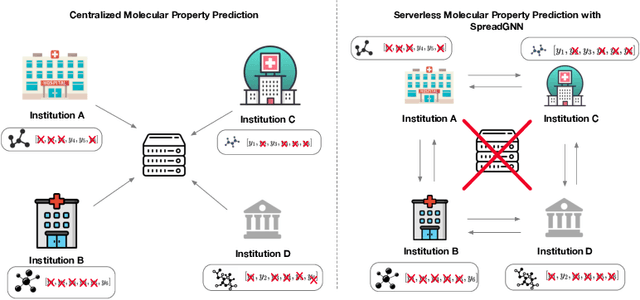
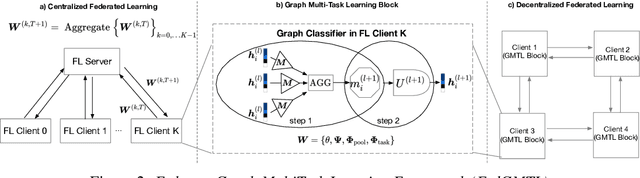
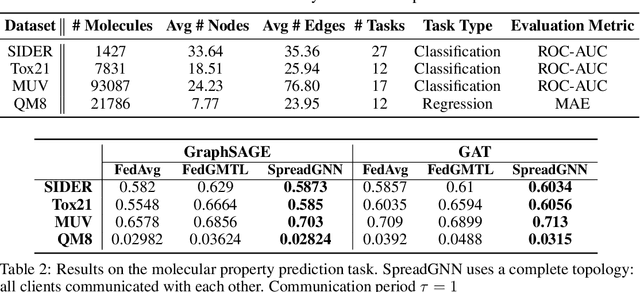
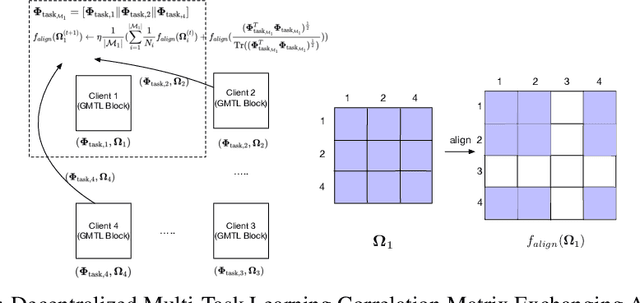
Graph Neural Networks (GNNs) are the first choice methods for graph machine learning problems thanks to their ability to learn state-of-the-art level representations from graph-structured data. However, centralizing a massive amount of real-world graph data for GNN training is prohibitive due to user-side privacy concerns, regulation restrictions, and commercial competition. Federated Learning is the de-facto standard for collaborative training of machine learning models over many distributed edge devices without the need for centralization. Nevertheless, training graph neural networks in a federated setting is vaguely defined and brings statistical and systems challenges. This work proposes SpreadGNN, a novel multi-task federated training framework capable of operating in the presence of partial labels and absence of a central server for the first time in the literature. SpreadGNN extends federated multi-task learning to realistic serverless settings for GNNs, and utilizes a novel optimization algorithm with a convergence guarantee, Decentralized Periodic Averaging SGD (DPA-SGD), to solve decentralized multi-task learning problems. We empirically demonstrate the efficacy of our framework on a variety of non-I.I.D. distributed graph-level molecular property prediction datasets with partial labels. Our results show that SpreadGNN outperforms GNN models trained over a central server-dependent federated learning system, even in constrained topologies. The source code is publicly available at https://github.com/FedML-AI/SpreadGNN
FedGraphNN: A Federated Learning System and Benchmark for Graph Neural Networks
Apr 14, 2021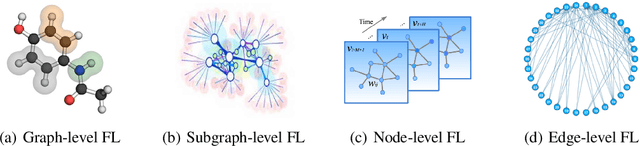
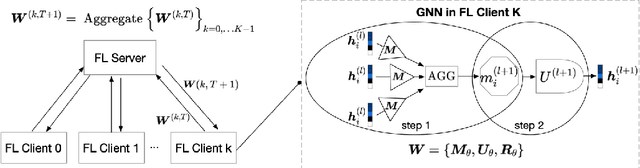
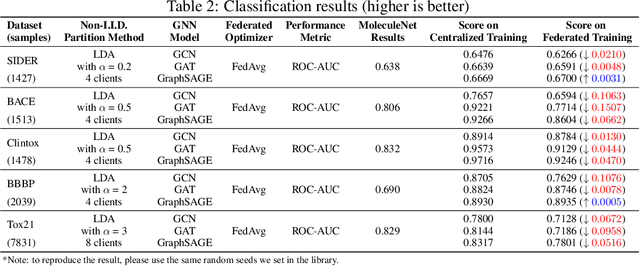
Graph Neural Network (GNN) research is rapidly growing thanks to the capacity of GNNs to learn representations from graph-structured data. However, centralizing a massive amount of real-world graph data for GNN training is prohibitive due to user-side privacy concerns, regulation restrictions, and commercial competition. Federated learning (FL), a trending distributed learning paradigm, aims to solve this challenge while preserving privacy. Despite recent advances in vision and language domains, there is no suitable platform for the federated training of GNNs. To this end, we introduce FedGraphNN, an open research federated learning system and a benchmark to facilitate GNN-based FL research. FedGraphNN is built on a unified formulation of federated GNNs and supports commonly used datasets, GNN models, FL algorithms, and flexible APIs. We also contribute a new molecular dataset, hERG, to promote research exploration. Our experimental results present significant challenges in federated GNN training: federated GNNs perform worse in most datasets with a non-I.I.D split than centralized GNNs; the GNN model that attains the best result in the centralized setting may not hold its advantage in the federated setting. These results imply that more research efforts are needed to unravel the mystery behind federated GNN training. Moreover, our system performance analysis demonstrates that the FedGraphNN system is computationally affordable to most research labs with limited GPUs. We maintain the source code at https://github.com/FedML-AI/FedGraphNN.