 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Both Layers Learn: Training Dynamics of Representing Linear Models via ReLU Networks
Jun 03, 2026In this paper, we study the gradient descent dynamics for jointly training both layers of a one-hidden-layer ReLU network to fit a linear target function. Concretely, we consider a realizable setting where inputs are drawn i.i.d. from a Gaussian distribution and labels follow a planted linear model. This stylized framework captures salient features of end-to-end training in inverse problems and certain auto-encoder models. Despite its apparent simplicity, the dynamics remain poorly understood, in part because the loss landscape contains multiple non-strict saddle points, making it unclear why gradient descent from random initialization reliably escapes bad stationary regions. We provide a detailed characterization of the optimization landscape and prove that gradient descent from a moderately small random initialization-simultaneously training both layers-converges to a global minimizer at a linear rate with order-wise optimal sample complexity. Our analysis tracks the trajectory through three phases: an alignment phase in which hidden weights progressively align with the planted direction while the output weights maintain the correct sign pattern; a growth phase in which the norms of both layers increase while preserving alignment; and a local refinement phase in which the aligned neurons rapidly converge to the planted direction, yielding fast local convergence. To rigorously show that GD avoids non-strict saddles, we develop trajectory-level control arguments for the end-to-end dynamics. In addition, we establish novel uniform concentration results that hold along the entire trajectory, and are essential for obtaining order-wise optimal sample complexity. We corroborate our theory with extensive experiments across a range of configurations.
MosaicMRI: A Diverse Dataset and Benchmark for Raw Musculoskeletal MRI
Apr 13, 2026Deep learning underpins a wide range of applications in MRI, including reconstruction, artifact removal, and segmentation. However, progress has been driven largely by public datasets focused on brain and knee imaging, shaping how models are trained and evaluated. As a result, careful studies of the reliability of these models across diverse anatomical settings remain limited. In this work, we introduce MosaicMRI, a large and diverse collection of fully sampled raw musculoskeletal (MSK) MR measurements designed for training and evaluating machine-learning-based methods. MosaicMRI is the largest open-source raw MSK MRI dataset to date, comprising 2,671 volumes and 80,156 slices. The dataset offers substantial diversity in volume orientation (e.g., axial, sagittal), imaging contrasts (e.g., PD, T1, T2), anatomies (e.g., spine, knee, hip, ankle, and others), and numbers of acquisition coils. Using VarNet as a baseline for accelerated reconstruction task, we perform a comprehensive set of experiments to study scaling behavior with respect to both model capacity and dataset size. Interestingly, models trained on the combined anatomies significantly outperform anatomy-specific models in low-sample regimes, highlighting the benefits of anatomical diversity and the presence of exploitable cross-anatomical correlations. We further evaluate robustness and cross-anatomy generalization by training models on one anatomy (e.g., spine) and testing them on another (e.g., knee). Notably, we identify groups of body parts (e.g., foot and elbow) that generalize well with each other, and highlight that performance under domain shifts depends on both training set size, anatomy, and protocol-specific factors.
ATHENA: Adaptive Test-Time Steering for Improving Count Fidelity in Diffusion Models
Mar 20, 2026Text-to-image diffusion models achieve high visual fidelity but surprisingly exhibit systematic failures in numerical control when prompts specify explicit object counts. To address this limitation, we introduce ATHENA, a model-agnostic, test-time adaptive steering framework that improves object count fidelity without modifying model architectures or requiring retraining. ATHENA leverages intermediate representations during sampling to estimate object counts and applies count-aware noise corrections early in the denoising process, steering the generation trajectory before structural errors become difficult to revise. We present three progressively more advanced variants of ATHENA that trade additional computation for improved numerical accuracy, ranging from static prompt-based steering to dynamically adjusted count-aware control. Experiments on established benchmarks and a new visually and semantically complex dataset show that ATHENA consistently improves count fidelity, particularly at higher target counts, while maintaining favorable accuracy-runtime trade-offs across multiple diffusion backbones.
Learning to Recall with Transformers Beyond Orthogonal Embeddings
Mar 16, 2026Modern large language models (LLMs) excel at tasks that require storing and retrieving knowledge, such as factual recall and question answering. Transformers are central to this capability because they can encode information during training and retrieve it at inference. Existing theoretical analyses typically study transformers under idealized assumptions such as infinite data or orthogonal embeddings. In realistic settings, however, models are trained on finite datasets with non-orthogonal (random) embeddings. We address this gap by analyzing a single-layer transformer with random embeddings trained with (empirical) gradient descent on a simple token-retrieval task, where the model must identify an informative token within a length-$L$ sequence and learn a one-to-one mapping from tokens to labels. Our analysis tracks the ``early phase'' of gradient descent and yields explicit formulas for the model's storage capacity -- revealing a multiplicative dependence between sample size $N$, embedding dimension $d$, and sequence length $L$. We validate these scalings numerically and further complement them with a lower bound for the underlying statistical problem, demonstrating that this multiplicative scaling is intrinsic under non-orthogonal embeddings.
Training Dynamics of Softmax Self-Attention: Fast Global Convergence via Preconditioning
Mar 02, 2026We study the training dynamics of gradient descent in a softmax self-attention layer trained to perform linear regression and show that a simple first-order optimization algorithm can converge to the globally optimal self-attention parameters at a geometric rate. Our analysis proceeds in two steps. First, we show that in the infinite-data limit the regression problem solved by the self-attention layer is equivalent to a nonconvex matrix factorization problem. Second, we exploit this connection to design a novel "structure-aware" variant of gradient descent which efficiently optimizes the original finite-data regression objective. Our optimization algorithm features several innovations over standard gradient descent, including a preconditioner and regularizer which help avoid spurious stationary points, and a data-dependent spectral initialization of parameters which lie near the manifold of global minima with high probability.
CrispEdit: Low-Curvature Projections for Scalable Non-Destructive LLM Editing
Feb 17, 2026A central challenge in large language model (LLM) editing is capability preservation: methods that successfully change targeted behavior can quietly game the editing proxy and corrupt general capabilities, producing degenerate behaviors reminiscent of proxy/reward hacking. We present CrispEdit, a scalable and principled second-order editing algorithm that treats capability preservation as an explicit constraint, unifying and generalizing several existing editing approaches. CrispEdit formulates editing as constrained optimization and enforces the constraint by projecting edit updates onto the low-curvature subspace of the capability-loss landscape. At the crux of CrispEdit is expressing capability constraint via Bregman divergence, whose quadratic form yields the Gauss-Newton Hessian exactly and even when the base model is not trained to convergence. We make this second-order procedure efficient at the LLM scale using Kronecker-factored approximate curvature (K-FAC) and a novel matrix-free projector that exploits Kronecker structure to avoid constructing massive projection matrices. Across standard model-editing benchmarks, CrispEdit achieves high edit success while keeping capability degradation below 1% on average across datasets, significantly improving over prior editors.
Asymmetric Prompt Weighting for Reinforcement Learning with Verifiable Rewards
Feb 11, 2026Reinforcement learning with verifiable rewards has driven recent advances in LLM post-training, in particular for reasoning. Policy optimization algorithms generate a number of responses for a given prompt and then effectively weight the corresponding gradients depending on the rewards. The most popular algorithms including GRPO, DAPO, and RLOO focus on ambiguous prompts, i.e., prompts with intermediate success probability, while downgrading gradients with very easy and very hard prompts. In this paper, we consider asymmetric prompt weightings that assign higher weights to prompts with low, or even zero, empirical success probability. We find that asymmetric weighting particularly benefits from-scratch RL (as in R1-Zero), where training traverses a wide accuracy range, and less so in post-SFT RL where the model already starts at high accuracy. We also provide theory that characterizes prompt weights which minimize the time needed to raise success probability from an initial level to a target accuracy under a fixed update budget. In low-success regimes, where informative responses are rare and response cost dominates, these optimal weights become asymmetric, upweighting low success probabilities and thereby accelerating effective-time convergence.
Full-Batch Gradient Descent Outperforms One-Pass SGD: Sample Complexity Separation in Single-Index Learning
Feb 02, 2026It is folklore that reusing training data more than once can improve the statistical efficiency of gradient-based learning. However, beyond linear regression, the theoretical advantage of full-batch gradient descent (GD, which always reuses all the data) over one-pass stochastic gradient descent (online SGD, which uses each data point only once) remains unclear. In this work, we consider learning a $d$-dimensional single-index model with a quadratic activation, for which it is known that one-pass SGD requires $n\gtrsim d\log d$ samples to achieve weak recovery. We first show that this $\log d$ factor in the sample complexity persists for full-batch spherical GD on the correlation loss; however, by simply truncating the activation, full-batch GD exhibits a favorable optimization landscape at $n \simeq d$ samples, thereby outperforming one-pass SGD (with the same activation) in statistical efficiency. We complement this result with a trajectory analysis of full-batch GD on the squared loss from small initialization, showing that $n \gtrsim d$ samples and $T \gtrsim\log d$ gradient steps suffice to achieve strong (exact) recovery.
Hyperphantasia: A Benchmark for Evaluating the Mental Visualization Capabilities of Multimodal LLMs
Jul 16, 2025


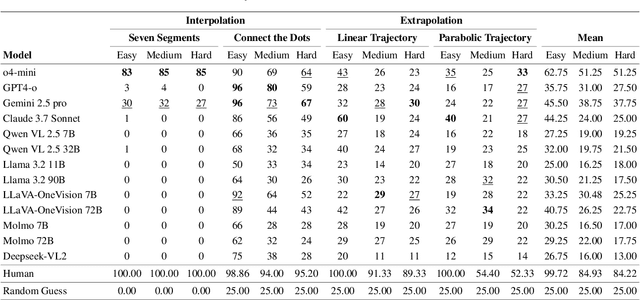
Mental visualization, the ability to construct and manipulate visual representations internally, is a core component of human cognition and plays a vital role in tasks involving reasoning, prediction, and abstraction. Despite the rapid progress of Multimodal Large Language Models (MLLMs), current benchmarks primarily assess passive visual perception, offering limited insight into the more active capability of internally constructing visual patterns to support problem solving. Yet mental visualization is a critical cognitive skill in humans, supporting abilities such as spatial navigation, predicting physical trajectories, and solving complex visual problems through imaginative simulation. To bridge this gap, we introduce Hyperphantasia, a synthetic benchmark designed to evaluate the mental visualization abilities of MLLMs through four carefully constructed puzzles. Each task is procedurally generated and presented at three difficulty levels, enabling controlled analysis of model performance across increasing complexity. Our comprehensive evaluation of state-of-the-art models reveals a substantial gap between the performance of humans and MLLMs. Additionally, we explore the potential of reinforcement learning to improve visual simulation capabilities. Our findings suggest that while some models exhibit partial competence in recognizing visual patterns, robust mental visualization remains an open challenge for current MLLMs.
The Rich and the Simple: On the Implicit Bias of Adam and SGD
May 29, 2025



Adam is the de facto optimization algorithm for several deep learning applications, but an understanding of its implicit bias and how it differs from other algorithms, particularly standard first-order methods such as (stochastic) gradient descent (GD), remains limited. In practice, neural networks trained with SGD are known to exhibit simplicity bias -- a tendency to find simple solutions. In contrast, we show that Adam is more resistant to such simplicity bias. To demystify this phenomenon, in this paper, we investigate the differences in the implicit biases of Adam and GD when training two-layer ReLU neural networks on a binary classification task involving synthetic data with Gaussian clusters. We find that GD exhibits a simplicity bias, resulting in a linear decision boundary with a suboptimal margin, whereas Adam leads to much richer and more diverse features, producing a nonlinear boundary that is closer to the Bayes' optimal predictor. This richer decision boundary also allows Adam to achieve higher test accuracy both in-distribution and under certain distribution shifts. We theoretically prove these results by analyzing the population gradients. To corroborate our theoretical findings, we present empirical results showing that this property of Adam leads to superior generalization across datasets with spurious correlations where neural networks trained with SGD are known to show simplicity bias and don't generalize well under certain distributional shifts.