 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Persuasive Social Robots for Health Behavior Change: A Systematic Review of Behavior Change Strategies and Evaluation Methods
Jan 13, 2026Social robots are increasingly applied as health behavior change interventions, yet actionable knowledge to guide their design and evaluation remains limited. This systematic review synthesizes (1) the behavior change strategies used in existing HRI studies employing social robots to promote health behavior change, and (2) the evaluation methods applied to assess behavior change outcomes. Relevant literature was identified through systematic database searches and hand searches. Analysis of 39 studies revealed four overarching categories of behavior change strategies: coaching strategies, counseling strategies, social influence strategies, and persuasion-enhancing strategies. These strategies highlight the unique affordances of social robots as behavior change interventions and offer valuable design heuristics. The review also identified key characteristics of current evaluation practices, including study designs, settings, durations, and outcome measures, on the basis of which we propose several directions for future HRI research.
HIPPO: Accelerating Video Large Language Models Inference via Holistic-aware Parallel Speculative Decoding
Jan 13, 2026Speculative decoding (SD) has emerged as a promising approach to accelerate LLM inference without sacrificing output quality. Existing SD methods tailored for video-LLMs primarily focus on pruning redundant visual tokens to mitigate the computational burden of massive visual inputs. However, existing methods do not achieve inference acceleration comparable to text-only LLMs. We observe from extensive experiments that this phenomenon mainly stems from two limitations: (i) their pruning strategies inadequately preserve visual semantic tokens, degrading draft quality and acceptance rates; (ii) even with aggressive pruning (e.g., 90% visual tokens removed), the draft model's remaining inference cost limits overall speedup. To address these limitations, we propose HIPPO, a general holistic-aware parallel speculative decoding framework. Specifically, HIPPO proposes (i) a semantic-aware token preservation method, which fuses global attention scores with local visual semantics to retain semantic information at high pruning ratios; (ii) a video parallel SD algorithm that decouples and overlaps draft generation and target verification phases. Experiments on four video-LLMs across six benchmarks demonstrate HIPPO's effectiveness, yielding up to 3.51x speedup compared to vanilla auto-regressive decoding.
OpenDecoder: Open Large Language Model Decoding to Incorporate Document Quality in RAG
Jan 13, 2026The development of large language models (LLMs) has achieved superior performance in a range of downstream tasks, including LLM-based retrieval-augmented generation (RAG). The quality of generated content heavily relies on the usefulness of the retrieved information and the capacity of LLMs' internal information processing mechanism to incorporate it in answer generation. It is generally assumed that the retrieved information is relevant to the question. However, the retrieved information may have a variable degree of relevance and usefulness, depending on the question and the document collection. It is important to take into account the relevance of the retrieved information in answer generation. In this paper, we propose OpenDecoder, a new approach that leverages explicit evaluation of the retrieved information as quality indicator features for generation. We aim to build a RAG model that is more robust to varying levels of noisy context. Three types of explicit evaluation information are considered: relevance score, ranking score, and QPP (query performance prediction) score. The experimental results on five benchmark datasets demonstrate the effectiveness and better robustness of OpenDecoder by outperforming various baseline methods. Importantly, this paradigm is flexible to be integrated with the post-training of LLMs for any purposes and incorporated with any type of external indicators.
Mass Concept Erasure in Diffusion Models with Concept Hierarchy
Jan 06, 2026The success of diffusion models has raised concerns about the generation of unsafe or harmful content, prompting concept erasure approaches that fine-tune modules to suppress specific concepts while preserving general generative capabilities. However, as the number of erased concepts grows, these methods often become inefficient and ineffective, since each concept requires a separate set of fine-tuned parameters and may degrade the overall generation quality. In this work, we propose a supertype-subtype concept hierarchy that organizes erased concepts into a parent-child structure. Each erased concept is treated as a child node, and semantically related concepts (e.g., macaw, and bald eagle) are grouped under a shared parent node, referred to as a supertype concept (e.g., bird). Rather than erasing concepts individually, we introduce an effective and efficient group-wise suppression method, where semantically similar concepts are grouped and erased jointly by sharing a single set of learnable parameters. During the erasure phase, standard diffusion regularization is applied to preserve denoising process in unmasked regions. To mitigate the degradation of supertype generation caused by excessive erasure of semantically related subtypes, we propose a novel method called Supertype-Preserving Low-Rank Adaptation (SuPLoRA), which encodes the supertype concept information in the frozen down-projection matrix and updates only the up-projection matrix during erasure. Theoretical analysis demonstrates the effectiveness of SuPLoRA in mitigating generation performance degradation. We construct a more challenging benchmark that requires simultaneous erasure of concepts across diverse domains, including celebrities, objects, and pornographic content.
HY-Motion 1.0: Scaling Flow Matching Models for Text-To-Motion Generation
Dec 29, 2025We present HY-Motion 1.0, a series of state-of-the-art, large-scale, motion generation models capable of generating 3D human motions from textual descriptions. HY-Motion 1.0 represents the first successful attempt to scale up Diffusion Transformer (DiT)-based flow matching models to the billion-parameter scale within the motion generation domain, delivering instruction-following capabilities that significantly outperform current open-source benchmarks. Uniquely, we introduce a comprehensive, full-stage training paradigm -- including large-scale pretraining on over 3,000 hours of motion data, high-quality fine-tuning on 400 hours of curated data, and reinforcement learning from both human feedback and reward models -- to ensure precise alignment with the text instruction and high motion quality. This framework is supported by our meticulous data processing pipeline, which performs rigorous motion cleaning and captioning. Consequently, our model achieves the most extensive coverage, spanning over 200 motion categories across 6 major classes. We release HY-Motion 1.0 to the open-source community to foster future research and accelerate the transition of 3D human motion generation models towards commercial maturity.
Adaptation of Agentic AI
Dec 22, 2025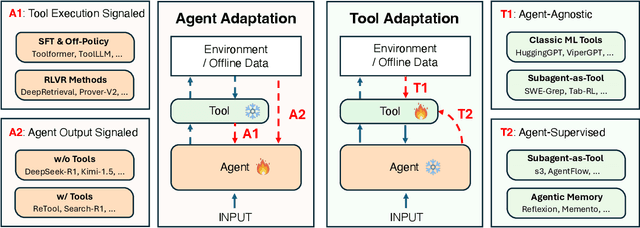
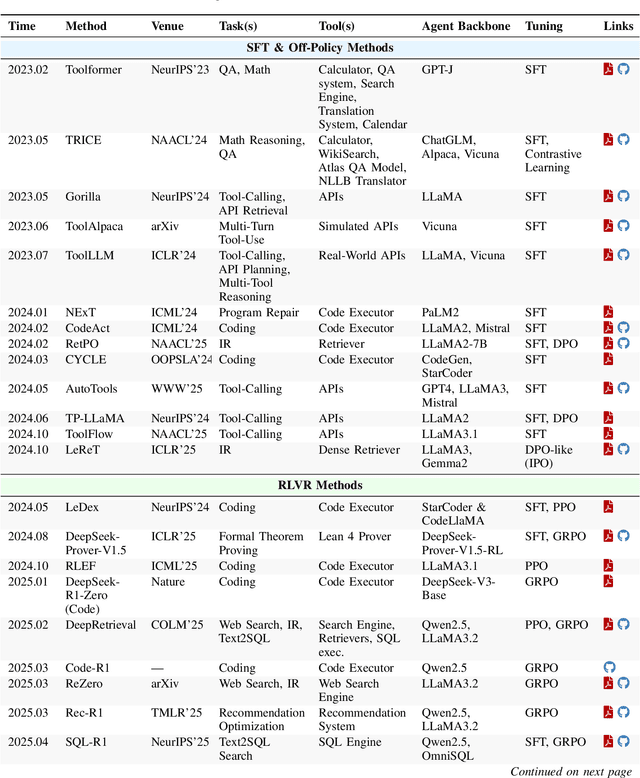
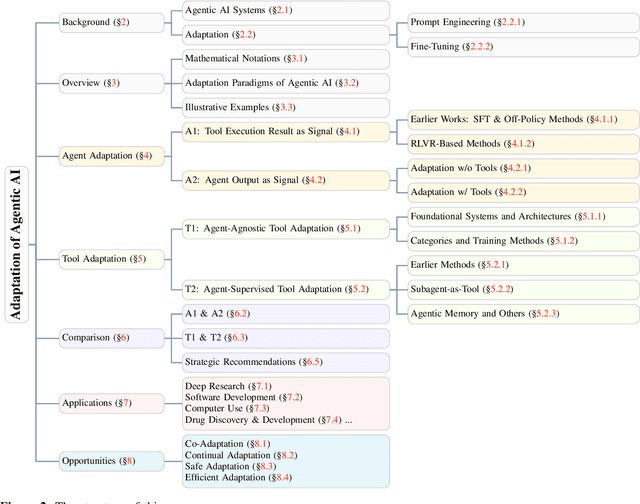
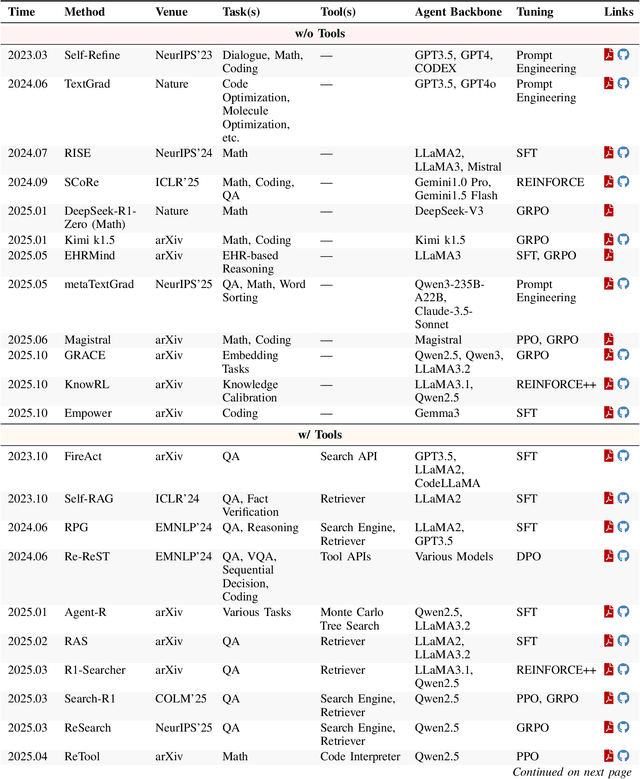
Cutting-edge agentic AI systems are built on foundation models that can be adapted to plan, reason, and interact with external tools to perform increasingly complex and specialized tasks. As these systems grow in capability and scope, adaptation becomes a central mechanism for improving performance, reliability, and generalization. In this paper, we unify the rapidly expanding research landscape into a systematic framework that spans both agent adaptations and tool adaptations. We further decompose these into tool-execution-signaled and agent-output-signaled forms of agent adaptation, as well as agent-agnostic and agent-supervised forms of tool adaptation. We demonstrate that this framework helps clarify the design space of adaptation strategies in agentic AI, makes their trade-offs explicit, and provides practical guidance for selecting or switching among strategies during system design. We then review the representative approaches in each category, analyze their strengths and limitations, and highlight key open challenges and future opportunities. Overall, this paper aims to offer a conceptual foundation and practical roadmap for researchers and practitioners seeking to build more capable, efficient, and reliable agentic AI systems.
RFKG-CoT: Relation-Driven Adaptive Hop-count Selection and Few-Shot Path Guidance for Knowledge-Aware QA
Dec 17, 2025Large language models (LLMs) often generate hallucinations in knowledge-intensive QA due to parametric knowledge limitations. While existing methods like KG-CoT improve reliability by integrating knowledge graph (KG) paths, they suffer from rigid hop-count selection (solely question-driven) and underutilization of reasoning paths (lack of guidance). To address this, we propose RFKG-CoT: First, it replaces the rigid hop-count selector with a relation-driven adaptive hop-count selector that dynamically adjusts reasoning steps by activating KG relations (e.g., 1-hop for direct "brother" relations, 2-hop for indirect "father-son" chains), formalized via a relation mask. Second, it introduces a few-shot in-context learning path guidance mechanism with CoT (think) that constructs examples in a "question-paths-answer" format to enhance LLMs' ability to understand reasoning paths. Experiments on four KGQA benchmarks show RFKG-CoT improves accuracy by up to 14.7 pp (Llama2-7B on WebQSP) over KG-CoT. Ablations confirm the hop-count selector and the path prompt are complementary, jointly transforming KG evidence into more faithful answers.
Revisiting the Reliability of Language Models in Instruction-Following
Dec 15, 2025Advanced LLMs have achieved near-ceiling instruction-following accuracy on benchmarks such as IFEval. However, these impressive scores do not necessarily translate to reliable services in real-world use, where users often vary their phrasing, contextual framing, and task formulations. In this paper, we study nuance-oriented reliability: whether models exhibit consistent competence across cousin prompts that convey analogous user intents but with subtle nuances. To quantify this, we introduce a new metric, reliable@k, and develop an automated pipeline that generates high-quality cousin prompts via data augmentation. Building upon this, we construct IFEval++ for systematic evaluation. Across 20 proprietary and 26 open-source LLMs, we find that current models exhibit substantial insufficiency in nuance-oriented reliability -- their performance can drop by up to 61.8% with nuanced prompt modifications. What's more, we characterize it and explore three potential improvement recipes. Our findings highlight nuance-oriented reliability as a crucial yet underexplored next step toward more dependable and trustworthy LLM behavior. Our code and benchmark are accessible: https://github.com/jianshuod/IFEval-pp.
3D Human-Human Interaction Anomaly Detection
Dec 15, 2025Human-centric anomaly detection (AD) has been primarily studied to specify anomalous behaviors in a single person. However, as humans by nature tend to act in a collaborative manner, behavioral anomalies can also arise from human-human interactions. Detecting such anomalies using existing single-person AD models is prone to low accuracy, as these approaches are typically not designed to capture the complex and asymmetric dynamics of interactions. In this paper, we introduce a novel task, Human-Human Interaction Anomaly Detection (H2IAD), which aims to identify anomalous interactive behaviors within collaborative 3D human actions. To address H2IAD, we then propose Interaction Anomaly Detection Network (IADNet), which is formalized with a Temporal Attention Sharing Module (TASM). Specifically, in designing TASM, we share the encoded motion embeddings across both people such that collaborative motion correlations can be effectively synchronized. Moreover, we notice that in addition to temporal dynamics, human interactions are also characterized by spatial configurations between two people. We thus introduce a Distance-Based Relational Encoding Module (DREM) to better reflect social cues in H2IAD. The normalizing flow is eventually employed for anomaly scoring. Extensive experiments on human-human motion benchmarks demonstrate that IADNet outperforms existing Human-centric AD baselines in H2IAD.
Benchmarking Real-World Medical Image Classification with Noisy Labels: Challenges, Practice, and Outlook
Dec 10, 2025Learning from noisy labels remains a major challenge in medical image analysis, where annotation demands expert knowledge and substantial inter-observer variability often leads to inconsistent or erroneous labels. Despite extensive research on learning with noisy labels (LNL), the robustness of existing methods in medical imaging has not been systematically assessed. To address this gap, we introduce LNMBench, a comprehensive benchmark for Label Noise in Medical imaging. LNMBench encompasses \textbf{10} representative methods evaluated across 7 datasets, 6 imaging modalities, and 3 noise patterns, establishing a unified and reproducible framework for robustness evaluation under realistic conditions. Comprehensive experiments reveal that the performance of existing LNL methods degrades substantially under high and real-world noise, highlighting the persistent challenges of class imbalance and domain variability in medical data. Motivated by these findings, we further propose a simple yet effective improvement to enhance model robustness under such conditions. The LNMBench codebase is publicly released to facilitate standardized evaluation, promote reproducible research, and provide practical insights for developing noise-resilient algorithms in both research and real-world medical applications.The codebase is publicly available on https://github.com/myyy777/LNMBench.