 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Sequence Modeling for Safe Reinforcement Learning
Feb 09, 2026Offline safe reinforcement learning (RL) aims to learn policies from a fixed dataset while maximizing performance under cumulative cost constraints. In practice, deployment requirements often vary across scenarios, necessitating a single policy that can adapt zero-shot to different cost thresholds. However, most existing offline safe RL methods are trained under a pre-specified threshold, yielding policies with limited generalization and deployment flexibility across cost thresholds. Motivated by recent progress in conditional sequence modeling (CSM), which enables flexible goal-conditioned control by specifying target returns, we propose RCDT, a CSM-based method that supports zero-shot deployment across multiple cost thresholds within a single trained policy. RCDT is the first CSM-based offline safe RL algorithm that integrates a Lagrangian-style cost penalty with an auto-adaptive penalty coefficient. To avoid overly conservative behavior and achieve a more favorable return--cost trade-off, a reward--cost-aware trajectory reweighting mechanism and Q-value regularization are further incorporated. Extensive experiments on the DSRL benchmark demonstrate that RCDT consistently improves return--cost trade-offs over representative baselines, advancing the state-of-the-art in offline safe RL.
FG-OrIU: Towards Better Forgetting via Feature-Gradient Orthogonality for Incremental Unlearning
Jan 20, 2026Incremental unlearning (IU) is critical for pre-trained models to comply with sequential data deletion requests, yet existing methods primarily suppress parameters or confuse knowledge without explicit constraints on both feature and gradient level, resulting in \textit{superficial forgetting} where residual information remains recoverable. This incomplete forgetting risks security breaches and disrupts retention balance, especially in IU scenarios. We propose FG-OrIU (\textbf{F}eature-\textbf{G}radient \textbf{Or}thogonality for \textbf{I}ncremental \textbf{U}nlearning), the first framework unifying orthogonal constraints on both features and gradients level to achieve deep forgetting, where the forgetting effect is irreversible. FG-OrIU decomposes feature spaces via Singular Value Decomposition (SVD), separating forgetting and remaining class features into distinct subspaces. It then enforces dual constraints: feature orthogonal projection on both forgetting and remaining classes, while gradient orthogonal projection prevents the reintroduction of forgotten knowledge and disruption to remaining classes during updates. Additionally, dynamic subspace adaptation merges newly forgetting subspaces and contracts remaining subspaces, ensuring a stable balance between removal and retention across sequential unlearning tasks. Extensive experiments demonstrate the effectiveness of our method.
Mass Concept Erasure in Diffusion Models with Concept Hierarchy
Jan 06, 2026The success of diffusion models has raised concerns about the generation of unsafe or harmful content, prompting concept erasure approaches that fine-tune modules to suppress specific concepts while preserving general generative capabilities. However, as the number of erased concepts grows, these methods often become inefficient and ineffective, since each concept requires a separate set of fine-tuned parameters and may degrade the overall generation quality. In this work, we propose a supertype-subtype concept hierarchy that organizes erased concepts into a parent-child structure. Each erased concept is treated as a child node, and semantically related concepts (e.g., macaw, and bald eagle) are grouped under a shared parent node, referred to as a supertype concept (e.g., bird). Rather than erasing concepts individually, we introduce an effective and efficient group-wise suppression method, where semantically similar concepts are grouped and erased jointly by sharing a single set of learnable parameters. During the erasure phase, standard diffusion regularization is applied to preserve denoising process in unmasked regions. To mitigate the degradation of supertype generation caused by excessive erasure of semantically related subtypes, we propose a novel method called Supertype-Preserving Low-Rank Adaptation (SuPLoRA), which encodes the supertype concept information in the frozen down-projection matrix and updates only the up-projection matrix during erasure. Theoretical analysis demonstrates the effectiveness of SuPLoRA in mitigating generation performance degradation. We construct a more challenging benchmark that requires simultaneous erasure of concepts across diverse domains, including celebrities, objects, and pornographic content.
Unleashing High-Quality Image Generation in Diffusion Sampling Using Second-Order Levenberg-Marquardt-Langevin
May 30, 2025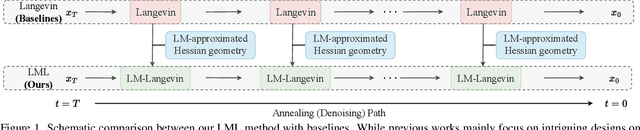


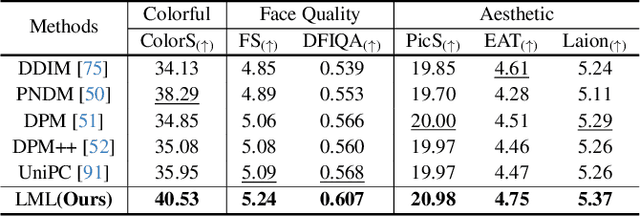
The diffusion models (DMs) have demonstrated the remarkable capability of generating images via learning the noised score function of data distribution. Current DM sampling techniques typically rely on first-order Langevin dynamics at each noise level, with efforts concentrated on refining inter-level denoising strategies. While leveraging additional second-order Hessian geometry to enhance the sampling quality of Langevin is a common practice in Markov chain Monte Carlo (MCMC), the naive attempts to utilize Hessian geometry in high-dimensional DMs lead to quadratic-complexity computational costs, rendering them non-scalable. In this work, we introduce a novel Levenberg-Marquardt-Langevin (LML) method that approximates the diffusion Hessian geometry in a training-free manner, drawing inspiration from the celebrated Levenberg-Marquardt optimization algorithm. Our approach introduces two key innovations: (1) A low-rank approximation of the diffusion Hessian, leveraging the DMs' inherent structure and circumventing explicit quadratic-complexity computations; (2) A damping mechanism to stabilize the approximated Hessian. This LML approximated Hessian geometry enables the diffusion sampling to execute more accurate steps and improve the image generation quality. We further conduct a theoretical analysis to substantiate the approximation error bound of low-rank approximation and the convergence property of the damping mechanism. Extensive experiments across multiple pretrained DMs validate that the LML method significantly improves image generation quality, with negligible computational overhead.
Efficiently Access Diffusion Fisher: Within the Outer Product Span Space
May 29, 2025Recent Diffusion models (DMs) advancements have explored incorporating the second-order diffusion Fisher information (DF), defined as the negative Hessian of log density, into various downstream tasks and theoretical analysis. However, current practices typically approximate the diffusion Fisher by applying auto-differentiation to the learned score network. This black-box method, though straightforward, lacks any accuracy guarantee and is time-consuming. In this paper, we show that the diffusion Fisher actually resides within a space spanned by the outer products of score and initial data. Based on the outer-product structure, we develop two efficient approximation algorithms to access the trace and matrix-vector multiplication of DF, respectively. These algorithms bypass the auto-differentiation operations with time-efficient vector-product calculations. Furthermore, we establish the approximation error bounds for the proposed algorithms. Experiments in likelihood evaluation and adjoint optimization demonstrate the superior accuracy and reduced computational cost of our proposed algorithms. Additionally, based on the novel outer-product formulation of DF, we design the first numerical verification experiment for the optimal transport property of the general PF-ODE deduced map.
Many-to-Many Matching via Sparsity Controlled Optimal Transport
Mar 31, 2025



Many-to-many matching seeks to match multiple points in one set and multiple points in another set, which is a basis for a wide range of data mining problems. It can be naturally recast in the framework of Optimal Transport (OT). However, existing OT methods either lack the ability to accomplish many-to-many matching or necessitate careful tuning of a regularization parameter to achieve satisfactory results. This paper proposes a novel many-to-many matching method to explicitly encode many-to-many constraints while preventing the degeneration into one-to-one matching. The proposed method consists of the following two components. The first component is the matching budget constraints on each row and column of a transport plan, which specify how many points can be matched to a point at most. The second component is the deformed $q$-entropy regularization, which encourages a point to meet the matching budget maximally. While the deformed $q$-entropy was initially proposed to sparsify a transport plan, we employ it to avoid the degeneration into one-to-one matching. We optimize the objective via a penalty algorithm, which is efficient and theoretically guaranteed to converge. Experimental results on various tasks demonstrate that the proposed method achieves good performance by gleaning meaningful many-to-many matchings.
IAP: Improving Continual Learning of Vision-Language Models via Instance-Aware Prompting
Mar 26, 2025



Recent pre-trained vision-language models (PT-VLMs) often face a Multi-Domain Class-Incremental Learning (MCIL) scenario in practice, where several classes and domains of multi-modal tasks are incrementally arrived. Without access to previously learned tasks and unseen tasks, memory-constrained MCIL suffers from forward and backward forgetting. To alleviate the above challenges, parameter-efficient fine-tuning techniques (PEFT), such as prompt tuning, are employed to adapt the PT-VLM to the diverse incrementally learned tasks. To achieve effective new task adaptation, existing methods only consider the effect of PEFT strategy selection, but neglect the influence of PEFT parameter setting (e.g., prompting). In this paper, we tackle the challenge of optimizing prompt designs for diverse tasks in MCIL and propose an Instance-Aware Prompting (IAP) framework. Specifically, our Instance-Aware Gated Prompting (IA-GP) module enhances adaptation to new tasks while mitigating forgetting by dynamically assigning prompts across transformer layers at the instance level. Our Instance-Aware Class-Distribution-Driven Prompting (IA-CDDP) improves the task adaptation process by determining an accurate task-label-related confidence score for each instance. Experimental evaluations across 11 datasets, using three performance metrics, demonstrate the effectiveness of our proposed method. Code can be found at https://github.com/FerdinandZJU/IAP.
CE-SDWV: Effective and Efficient Concept Erasure for Text-to-Image Diffusion Models via a Semantic-Driven Word Vocabulary
Jan 26, 2025



Large-scale text-to-image (T2I) diffusion models have achieved remarkable generative performance about various concepts. With the limitation of privacy and safety in practice, the generative capability concerning NSFW (Not Safe For Work) concepts is undesirable, e.g., producing sexually explicit photos, and licensed images. The concept erasure task for T2I diffusion models has attracted considerable attention and requires an effective and efficient method. To achieve this goal, we propose a CE-SDWV framework, which removes the target concepts (e.g., NSFW concepts) of T2I diffusion models in the text semantic space by only adjusting the text condition tokens and does not need to re-train the original T2I diffusion model's weights. Specifically, our framework first builds a target concept-related word vocabulary to enhance the representation of the target concepts within the text semantic space, and then utilizes an adaptive semantic component suppression strategy to ablate the target concept-related semantic information in the text condition tokens. To further adapt the above text condition tokens to the original image semantic space, we propose an end-to-end gradient-orthogonal token optimization strategy. Extensive experiments on I2P and UnlearnCanvas benchmarks demonstrate the effectiveness and efficiency of our method.
BELM: Bidirectional Explicit Linear Multi-step Sampler for Exact Inversion in Diffusion Models
Oct 09, 2024



The inversion of diffusion model sampling, which aims to find the corresponding initial noise of a sample, plays a critical role in various tasks. Recently, several heuristic exact inversion samplers have been proposed to address the inexact inversion issue in a training-free manner. However, the theoretical properties of these heuristic samplers remain unknown and they often exhibit mediocre sampling quality. In this paper, we introduce a generic formulation, \emph{Bidirectional Explicit Linear Multi-step} (BELM) samplers, of the exact inversion samplers, which includes all previously proposed heuristic exact inversion samplers as special cases. The BELM formulation is derived from the variable-stepsize-variable-formula linear multi-step method via integrating a bidirectional explicit constraint. We highlight this bidirectional explicit constraint is the key of mathematically exact inversion. We systematically investigate the Local Truncation Error (LTE) within the BELM framework and show that the existing heuristic designs of exact inversion samplers yield sub-optimal LTE. Consequently, we propose the Optimal BELM (O-BELM) sampler through the LTE minimization approach. We conduct additional analysis to substantiate the theoretical stability and global convergence property of the proposed optimal sampler. Comprehensive experiments demonstrate our O-BELM sampler establishes the exact inversion property while achieving high-quality sampling. Additional experiments in image editing and image interpolation highlight the extensive potential of applying O-BELM in varying applications.
LW2G: Learning Whether to Grow for Prompt-based Continual Learning
Sep 27, 2024Continual Learning (CL) aims to learn in non-stationary scenarios, progressively acquiring and maintaining knowledge from sequential tasks. Recent Prompt-based Continual Learning (PCL) has achieved remarkable performance with Pre-Trained Models (PTMs). These approaches grow a prompt sets pool by adding a new set of prompts when learning each new task (\emph{prompt learning}) and adopt a matching mechanism to select the correct set for each testing sample (\emph{prompt retrieval}). Previous studies focus on the latter stage by improving the matching mechanism to enhance Prompt Retrieval Accuracy (PRA). To promote cross-task knowledge facilitation and form an effective and efficient prompt sets pool, we propose a plug-in module in the former stage to \textbf{Learn Whether to Grow (LW2G)} based on the disparities between tasks. Specifically, a shared set of prompts is utilized when several tasks share certain commonalities, and a new set is added when there are significant differences between the new task and previous tasks. Inspired by Gradient Projection Continual Learning, our LW2G develops a metric called Hinder Forward Capability (HFC) to measure the hindrance imposed on learning new tasks by surgically modifying the original gradient onto the orthogonal complement of the old feature space. With HFC, an automated scheme Dynamic Growing Approach adaptively learns whether to grow with a dynamic threshold. Furthermore, we design a gradient-based constraint to ensure the consistency between the updating prompts and pre-trained knowledge, and a prompts weights reusing strategy to enhance forward transfer. Extensive experiments show the effectiveness of our method. The source codes are available at \url{https://github.com/RAIAN08/LW2G}.