 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiCD: Change Detection in Quality-Varied Images via Hierarchical Correlation Distillation
Jan 19, 2024Advanced change detection techniques primarily target image pairs of equal and high quality. However, variations in imaging conditions and platforms frequently lead to image pairs with distinct qualities: one image being high-quality, while the other being low-quality. These disparities in image quality present significant challenges for understanding image pairs semantically and extracting change features, ultimately resulting in a notable decline in performance. To tackle this challenge, we introduce an innovative training strategy grounded in knowledge distillation. The core idea revolves around leveraging task knowledge acquired from high-quality image pairs to guide the model's learning process when dealing with image pairs that exhibit differences in quality. Additionally, we develop a hierarchical correlation distillation approach (involving self-correlation, cross-correlation, and global correlation). This approach compels the student model to replicate the correlations inherent in the teacher model, rather than focusing solely on individual features. This ensures effective knowledge transfer while maintaining the student model's training flexibility.
ERNIE-Music: Text-to-Waveform Music Generation with Diffusion Models
Feb 09, 2023In recent years, there has been an increased popularity in image and speech generation using diffusion models. However, directly generating music waveforms from free-form text prompts is still under-explored. In this paper, we propose the first text-to-waveform music generation model that can receive arbitrary texts using diffusion models. We incorporate the free-form textual prompt as the condition to guide the waveform generation process of diffusion models. To solve the problem of lacking such text-music parallel data, we collect a dataset of text-music pairs from the Internet with weak supervision. Besides, we compare the effect of two prompt formats of conditioning texts (music tags and free-form texts) and prove the superior performance of our method in terms of text-music relevance. We further demonstrate that our generated music in the waveform domain outperforms previous works by a large margin in terms of diversity, quality, and text-music relevance.
Detecting Building Changes with Off-Nadir Aerial Images
Jan 26, 2023The tilted viewing nature of the off-nadir aerial images brings severe challenges to the building change detection (BCD) problem: the mismatch of the nearby buildings and the semantic ambiguity of the building facades. To tackle these challenges, we present a multi-task guided change detection network model, named as MTGCD-Net. The proposed model approaches the specific BCD problem by designing three auxiliary tasks, including: (1) a pixel-wise classification task to predict the roofs and facades of buildings; (2) an auxiliary task for learning the roof-to-footprint offsets of each building to account for the misalignment between building roof instances; and (3) an auxiliary task for learning the identical roof matching flow between bi-temporal aerial images to tackle the building roof mismatch problem. These auxiliary tasks provide indispensable and complementary building parsing and matching information. The predictions of the auxiliary tasks are finally fused to the main building change detection branch with a multi-modal distillation module. To train and test models for the BCD problem with off-nadir aerial images, we create a new benchmark dataset, named BANDON. Extensive experiments demonstrate that our model achieves superior performance over the previous state-of-the-art competitors.
ERNIE-Code: Beyond English-Centric Cross-lingual Pretraining for Programming Languages
Dec 13, 2022



Software engineers working with the same programming language (PL) may speak different natural languages (NLs) and vice versa, erecting huge barriers to communication and working efficiency. Recent studies have demonstrated the effectiveness of generative pre-training in computer programs, yet they are always English-centric. In this work, we step towards bridging the gap between multilingual NLs and multilingual PLs for large language models (LLMs). We release ERNIE-Code, a unified pre-trained language model for 116 NLs and 6 PLs. We employ two methods for universal cross-lingual pre-training: span-corruption language modeling that learns patterns from monolingual NL or PL; and pivot-based translation language modeling that relies on parallel data of many NLs and PLs. Extensive results show that ERNIE-Code outperforms previous multilingual LLMs for PL or NL across a wide range of end tasks of code intelligence, including multilingual code-to-text, text-to-code, code-to-code, and text-to-text generation. We further show its advantage of zero-shot prompting on multilingual code summarization and text-to-text translation. We will make our code and pre-trained models publicly available.
Multi-view deep learning based molecule design and structural optimization accelerates the SARS-CoV-2 inhibitor discovery
Dec 03, 2022In this work, we propose MEDICO, a Multi-viEw Deep generative model for molecule generation, structural optimization, and the SARS-CoV-2 Inhibitor disCOvery. To the best of our knowledge, MEDICO is the first-of-this-kind graph generative model that can generate molecular graphs similar to the structure of targeted molecules, with a multi-view representation learning framework to sufficiently and adaptively learn comprehensive structural semantics from targeted molecular topology and geometry. We show that our MEDICO significantly outperforms the state-of-the-art methods in generating valid, unique, and novel molecules under benchmarking comparisons. In particular, we showcase the multi-view deep learning model enables us to generate not only the molecules structurally similar to the targeted molecules but also the molecules with desired chemical properties, demonstrating the strong capability of our model in exploring the chemical space deeply. Moreover, case study results on targeted molecule generation for the SARS-CoV-2 main protease (Mpro) show that by integrating molecule docking into our model as chemical priori, we successfully generate new small molecules with desired drug-like properties for the Mpro, potentially accelerating the de novo design of Covid-19 drugs. Further, we apply MEDICO to the structural optimization of three well-known Mpro inhibitors (N3, 11a, and GC376) and achieve ~88% improvement in their binding affinity to Mpro, demonstrating the application value of our model for the development of therapeutics for SARS-CoV-2 infection.
ERNIE-SAT: Speech and Text Joint Pretraining for Cross-Lingual Multi-Speaker Text-to-Speech
Nov 07, 2022



Speech representation learning has improved both speech understanding and speech synthesis tasks for single language. However, its ability in cross-lingual scenarios has not been explored. In this paper, we extend the pretraining method for cross-lingual multi-speaker speech synthesis tasks, including cross-lingual multi-speaker voice cloning and cross-lingual multi-speaker speech editing. We propose a speech-text joint pretraining framework, where we randomly mask the spectrogram and the phonemes given a speech example and its transcription. By learning to reconstruct the masked parts of the input in different languages, our model shows great improvements over speaker-embedding-based multi-speaker TTS methods. Moreover, our framework is end-to-end for both the training and the inference without any finetuning effort. In cross-lingual multi-speaker voice cloning and cross-lingual multi-speaker speech editing tasks, our experiments show that our model outperforms speaker-embedding-based multi-speaker TTS methods. The code and model are publicly available at PaddleSpeech.
MechRetro is a chemical-mechanism-driven graph learning framework for interpretable retrosynthesis prediction and pathway planning
Oct 06, 2022
Leveraging artificial intelligence for automatic retrosynthesis speeds up organic pathway planning in digital laboratories. However, existing deep learning approaches are unexplainable, like "black box" with few insights, notably limiting their applications in real retrosynthesis scenarios. Here, we propose MechRetro, a chemical-mechanism-driven graph learning framework for interpretable retrosynthetic prediction and pathway planning, which learns several retrosynthetic actions to simulate a reverse reaction via elaborate self-adaptive joint learning. By integrating chemical knowledge as prior information, we design a novel Graph Transformer architecture to adaptively learn discriminative and chemically meaningful molecule representations, highlighting the strong capacity in molecule feature representation learning. We demonstrate that MechRetro outperforms the state-of-the-art approaches for retrosynthetic prediction with a large margin on large-scale benchmark datasets. Extending MechRetro to the multi-step retrosynthesis analysis, we identify efficient synthetic routes via an interpretable reasoning mechanism, leading to a better understanding in the realm of knowledgeable synthetic chemists. We also showcase that MechRetro discovers a novel pathway for protokylol, along with energy scores for uncertainty assessment, broadening the applicability for practical scenarios. Overall, we expect MechRetro to provide meaningful insights for high-throughput automated organic synthesis in drug discovery.
ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
Dec 23, 2021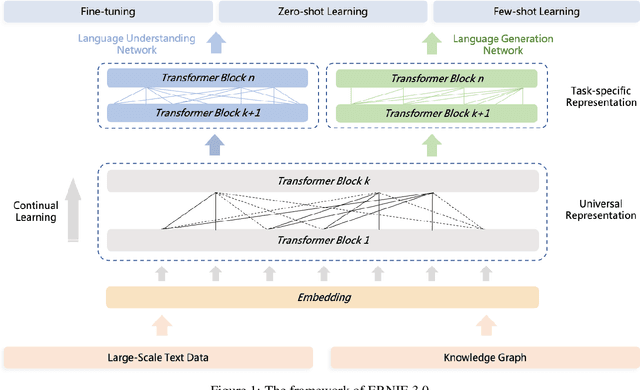
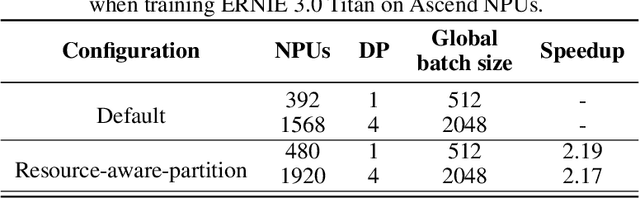
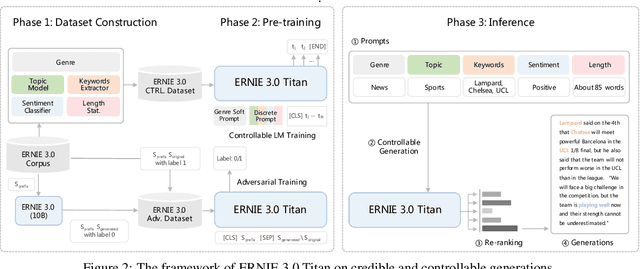
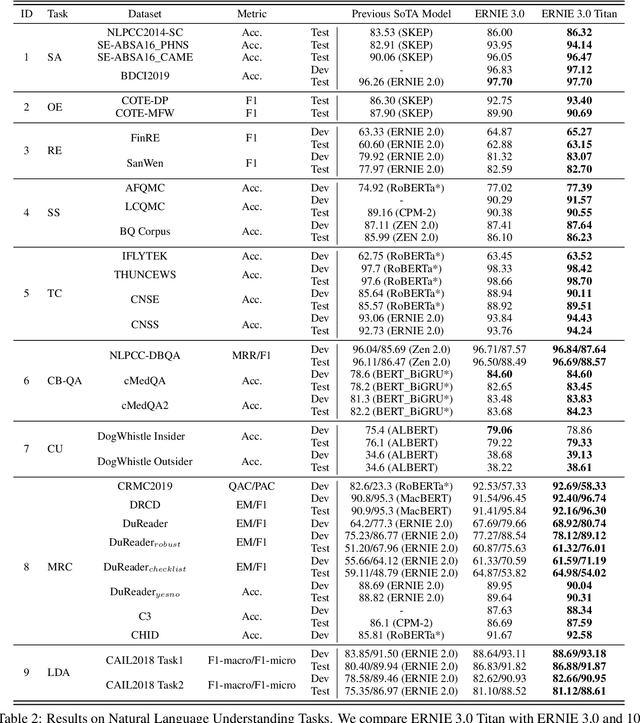
Pre-trained language models have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. GPT-3 has shown that scaling up pre-trained language models can further exploit their enormous potential. A unified framework named ERNIE 3.0 was recently proposed for pre-training large-scale knowledge enhanced models and trained a model with 10 billion parameters. ERNIE 3.0 outperformed the state-of-the-art models on various NLP tasks. In order to explore the performance of scaling up ERNIE 3.0, we train a hundred-billion-parameter model called ERNIE 3.0 Titan with up to 260 billion parameters on the PaddlePaddle platform. Furthermore, we design a self-supervised adversarial loss and a controllable language modeling loss to make ERNIE 3.0 Titan generate credible and controllable texts. To reduce the computation overhead and carbon emission, we propose an online distillation framework for ERNIE 3.0 Titan, where the teacher model will teach students and train itself simultaneously. ERNIE 3.0 Titan is the largest Chinese dense pre-trained model so far. Empirical results show that the ERNIE 3.0 Titan outperforms the state-of-the-art models on 68 NLP datasets.
CEHR-BERT: Incorporating temporal information from structured EHR data to improve prediction tasks
Nov 10, 2021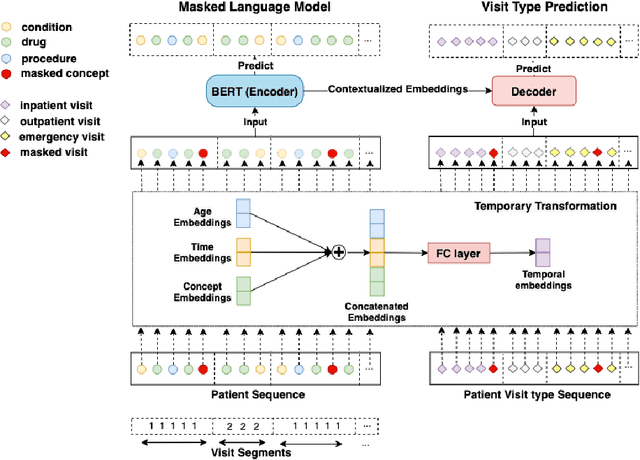

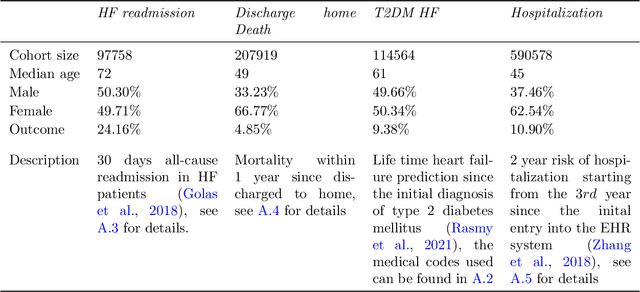

Embedding algorithms are increasingly used to represent clinical concepts in healthcare for improving machine learning tasks such as clinical phenotyping and disease prediction. Recent studies have adapted state-of-the-art bidirectional encoder representations from transformers (BERT) architecture to structured electronic health records (EHR) data for the generation of contextualized concept embeddings, yet do not fully incorporate temporal data across multiple clinical domains. Therefore we developed a new BERT adaptation, CEHR-BERT, to incorporate temporal information using a hybrid approach by augmenting the input to BERT using artificial time tokens, incorporating time, age, and concept embeddings, and introducing a new second learning objective for visit type. CEHR-BERT was trained on a subset of Columbia University Irving Medical Center-York Presbyterian Hospital's clinical data, which includes 2.4M patients, spanning over three decades, and tested using 4-fold cross-validation on the following prediction tasks: hospitalization, death, new heart failure (HF) diagnosis, and HF readmission. Our experiments show that CEHR-BERT outperformed existing state-of-the-art clinical BERT adaptations and baseline models across all 4 prediction tasks in both ROC-AUC and PR-AUC. CEHR-BERT also demonstrated strong transfer learning capability, as our model trained on only 5% of data outperformed comparison models trained on the entire data set. Ablation studies to better understand the contribution of each time component showed incremental gains with every element, suggesting that CEHR-BERT's incorporation of artificial time tokens, time and age embeddings with concept embeddings, and the addition of the second learning objective represents a promising approach for future BERT-based clinical embeddings.
ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
Jul 05, 2021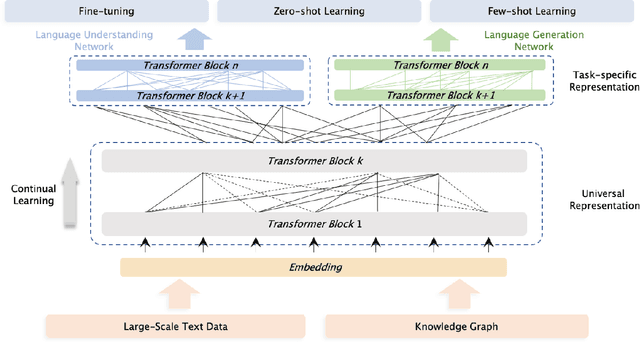

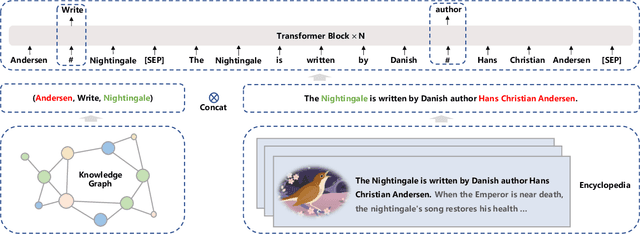
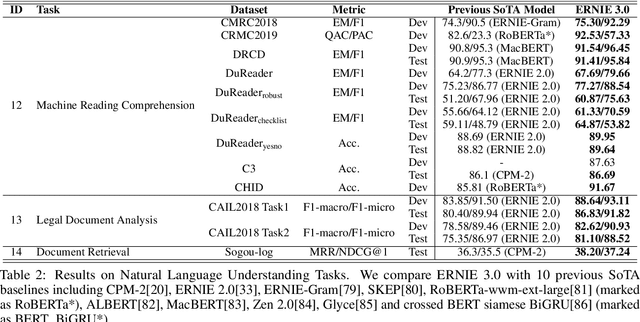
Pre-trained models have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. Recent works such as T5 and GPT-3 have shown that scaling up pre-trained language models can improve their generalization abilities. Particularly, the GPT-3 model with 175 billion parameters shows its strong task-agnostic zero-shot/few-shot learning capabilities. Despite their success, these large-scale models are trained on plain texts without introducing knowledge such as linguistic knowledge and world knowledge. In addition, most large-scale models are trained in an auto-regressive way. As a result, this kind of traditional fine-tuning approach demonstrates relatively weak performance when solving downstream language understanding tasks. In order to solve the above problems, we propose a unified framework named ERNIE 3.0 for pre-training large-scale knowledge enhanced models. It fuses auto-regressive network and auto-encoding network, so that the trained model can be easily tailored for both natural language understanding and generation tasks with zero-shot learning, few-shot learning or fine-tuning. We trained the model with 10 billion parameters on a 4TB corpus consisting of plain texts and a large-scale knowledge graph. Empirical results show that the model outperforms the state-of-the-art models on 54 Chinese NLP tasks, and its English version achieves the first place on the SuperGLUE benchmark (July 3, 2021), surpassing the human performance by +0.8% (90.6% vs. 89.8%).