 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Noisy Labels over Imbalanced Subpopulations
Nov 16, 2022



Learning with Noisy Labels (LNL) has attracted significant attention from the research community. Many recent LNL methods rely on the assumption that clean samples tend to have "small loss". However, this assumption always fails to generalize to some real-world cases with imbalanced subpopulations, i.e., training subpopulations varying in sample size or recognition difficulty. Therefore, recent LNL methods face the risk of misclassifying those "informative" samples (e.g., hard samples or samples in the tail subpopulations) into noisy samples, leading to poor generalization performance. To address the above issue, we propose a novel LNL method to simultaneously deal with noisy labels and imbalanced subpopulations. It first leverages sample correlation to estimate samples' clean probabilities for label correction and then utilizes corrected labels for Distributionally Robust Optimization (DRO) to further improve the robustness. Specifically, in contrast to previous works using classification loss as the selection criterion, we introduce a feature-based metric that takes the sample correlation into account for estimating samples' clean probabilities. Then, we refurbish the noisy labels using the estimated clean probabilities and the pseudo-labels from the model's predictions. With refurbished labels, we use DRO to train the model to be robust to subpopulation imbalance. Extensive experiments on a wide range of benchmarks demonstrate that our technique can consistently improve current state-of-the-art robust learning paradigms against noisy labels, especially when encountering imbalanced subpopulations.
UMIX: Improving Importance Weighting for Subpopulation Shift via Uncertainty-Aware Mixup
Oct 10, 2022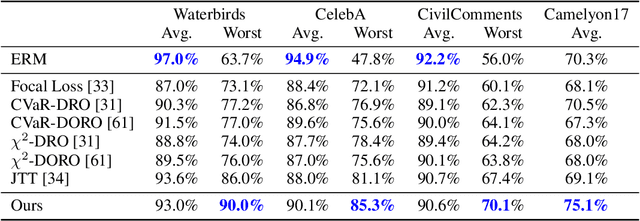
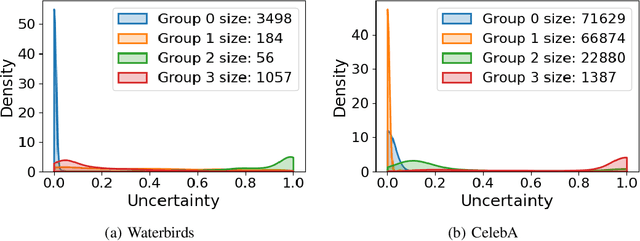
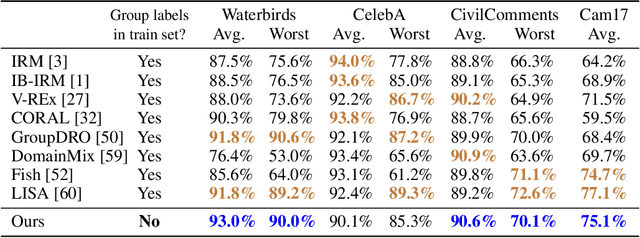
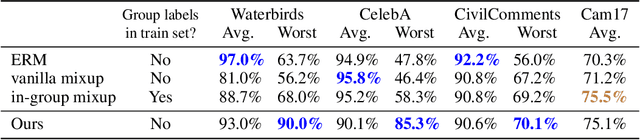
Subpopulation shift widely exists in many real-world machine learning applications, referring to the training and test distributions containing the same subpopulation groups but varying in subpopulation frequencies. Importance reweighting is a normal way to handle the subpopulation shift issue by imposing constant or adaptive sampling weights on each sample in the training dataset. However, some recent studies have recognized that most of these approaches fail to improve the performance over empirical risk minimization especially when applied to over-parameterized neural networks. In this work, we propose a simple yet practical framework, called uncertainty-aware mixup (UMIX), to mitigate the overfitting issue in over-parameterized models by reweighting the ''mixed'' samples according to the sample uncertainty. The training-trajectories-based uncertainty estimation is equipped in the proposed UMIX for each sample to flexibly characterize the subpopulation distribution. We also provide insightful theoretical analysis to verify that UMIX achieves better generalization bounds over prior works. Further, we conduct extensive empirical studies across a wide range of tasks to validate the effectiveness of our method both qualitatively and quantitatively. Code is available at https://github.com/TencentAILabHealthcare/UMIX.
ImDrug: A Benchmark for Deep Imbalanced Learning in AI-aided Drug Discovery
Sep 16, 2022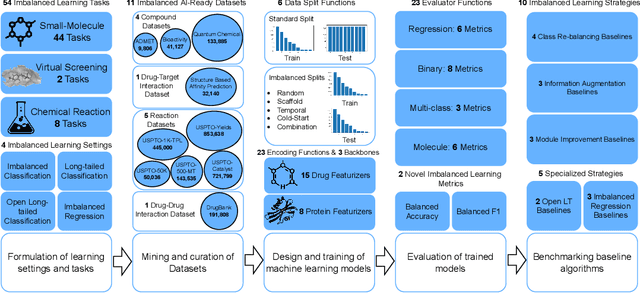

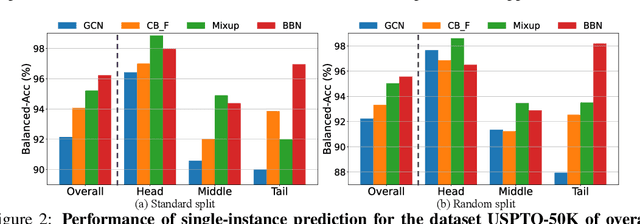
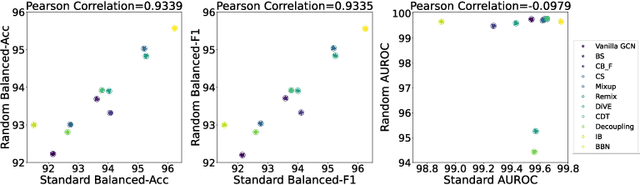
The last decade has witnessed a prosperous development of computational methods and dataset curation for AI-aided drug discovery (AIDD). However, real-world pharmaceutical datasets often exhibit highly imbalanced distribution, which is largely overlooked by the current literature but may severely compromise the fairness and generalization of machine learning applications. Motivated by this observation, we introduce ImDrug, a comprehensive benchmark with an open-source Python library which consists of 4 imbalance settings, 11 AI-ready datasets, 54 learning tasks and 16 baseline algorithms tailored for imbalanced learning. It provides an accessible and customizable testbed for problems and solutions spanning a broad spectrum of the drug discovery pipeline such as molecular modeling, drug-target interaction and retrosynthesis. We conduct extensive empirical studies with novel evaluation metrics, to demonstrate that the existing algorithms fall short of solving medicinal and pharmaceutical challenges in the data imbalance scenario. We believe that ImDrug opens up avenues for future research and development, on real-world challenges at the intersection of AIDD and deep imbalanced learning.
A Survey of Trustworthy Graph Learning: Reliability, Explainability, and Privacy Protection
May 23, 2022


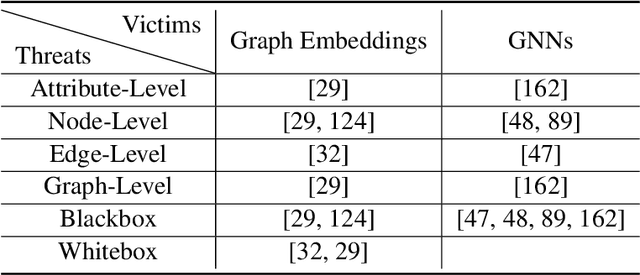
Deep graph learning has achieved remarkable progresses in both business and scientific areas ranging from finance and e-commerce, to drug and advanced material discovery. Despite these progresses, how to ensure various deep graph learning algorithms behave in a socially responsible manner and meet regulatory compliance requirements becomes an emerging problem, especially in risk-sensitive domains. Trustworthy graph learning (TwGL) aims to solve the above problems from a technical viewpoint. In contrast to conventional graph learning research which mainly cares about model performance, TwGL considers various reliability and safety aspects of the graph learning framework including but not limited to robustness, explainability, and privacy. In this survey, we provide a comprehensive review of recent leading approaches in the TwGL field from three dimensions, namely, reliability, explainability, and privacy protection. We give a general categorization for existing work and review typical work for each category. To give further insights for TwGL research, we provide a unified view to inspect previous works and build the connection between them. We also point out some important open problems remaining to be solved in the future developments of TwGL.
DRFLM: Distributionally Robust Federated Learning with Inter-client Noise via Local Mixup
Apr 16, 2022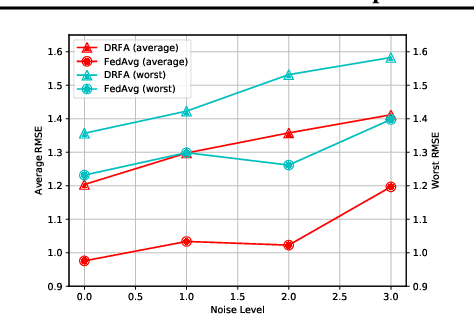
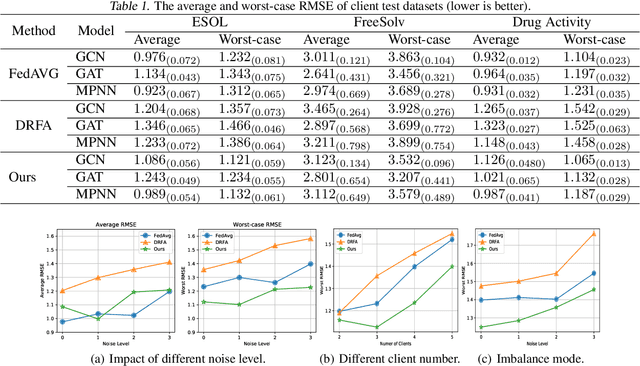
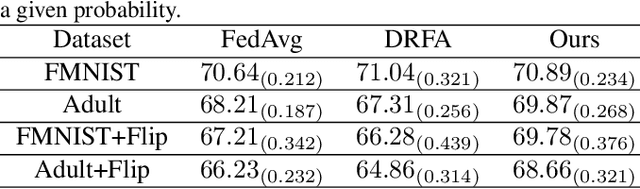
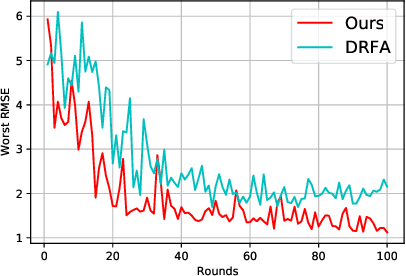
Recently, federated learning has emerged as a promising approach for training a global model using data from multiple organizations without leaking their raw data. Nevertheless, directly applying federated learning to real-world tasks faces two challenges: (1) heterogeneity in the data among different organizations; and (2) data noises inside individual organizations. In this paper, we propose a general framework to solve the above two challenges simultaneously. Specifically, we propose using distributionally robust optimization to mitigate the negative effects caused by data heterogeneity paradigm to sample clients based on a learnable distribution at each iteration. Additionally, we observe that this optimization paradigm is easily affected by data noises inside local clients, which has a significant performance degradation in terms of global model prediction accuracy. To solve this problem, we propose to incorporate mixup techniques into the local training process of federated learning. We further provide comprehensive theoretical analysis including robustness analysis, convergence analysis, and generalization ability. Furthermore, we conduct empirical studies across different drug discovery tasks, such as ADMET property prediction and drug-target affinity prediction.
Recent Advances in Reliable Deep Graph Learning: Adversarial Attack, Inherent Noise, and Distribution Shift
Feb 15, 2022


Deep graph learning (DGL) has achieved remarkable progress in both business and scientific areas ranging from finance and e-commerce to drug and advanced material discovery. Despite the progress, applying DGL to real-world applications faces a series of reliability threats including adversarial attacks, inherent noise, and distribution shift. This survey aims to provide a comprehensive review of recent advances for improving the reliability of DGL algorithms against the above threats. In contrast to prior related surveys which mainly focus on adversarial attacks and defense, our survey covers more reliability-related aspects of DGL, i.e., inherent noise and distribution shift. Additionally, we discuss the relationships among above aspects and highlight some important issues to be explored in future research.
DrugOOD: Out-of-Distribution (OOD) Dataset Curator and Benchmark for AI-aided Drug Discovery -- A Focus on Affinity Prediction Problems with Noise Annotations
Jan 24, 2022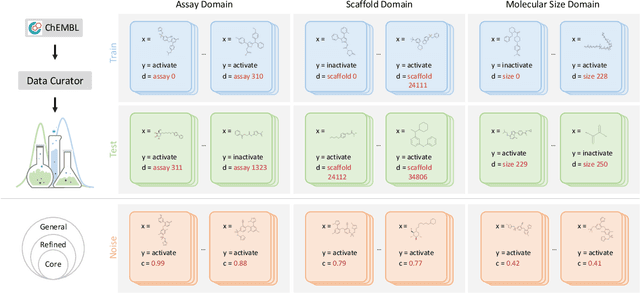

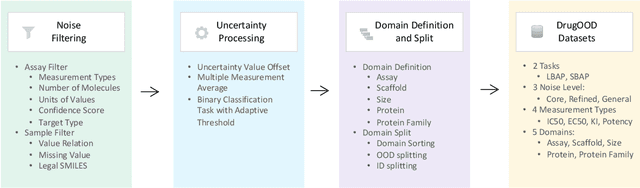
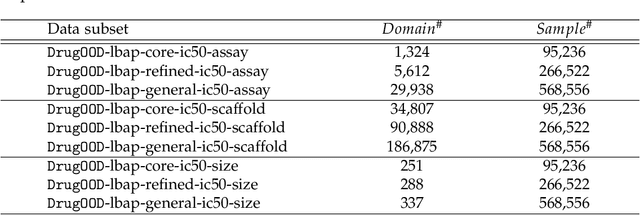
AI-aided drug discovery (AIDD) is gaining increasing popularity due to its promise of making the search for new pharmaceuticals quicker, cheaper and more efficient. In spite of its extensive use in many fields, such as ADMET prediction, virtual screening, protein folding and generative chemistry, little has been explored in terms of the out-of-distribution (OOD) learning problem with \emph{noise}, which is inevitable in real world AIDD applications. In this work, we present DrugOOD, a systematic OOD dataset curator and benchmark for AI-aided drug discovery, which comes with an open-source Python package that fully automates the data curation and OOD benchmarking processes. We focus on one of the most crucial problems in AIDD: drug target binding affinity prediction, which involves both macromolecule (protein target) and small-molecule (drug compound). In contrast to only providing fixed datasets, DrugOOD offers automated dataset curator with user-friendly customization scripts, rich domain annotations aligned with biochemistry knowledge, realistic noise annotations and rigorous benchmarking of state-of-the-art OOD algorithms. Since the molecular data is often modeled as irregular graphs using graph neural network (GNN) backbones, DrugOOD also serves as a valuable testbed for \emph{graph OOD learning} problems. Extensive empirical studies have shown a significant performance gap between in-distribution and out-of-distribution experiments, which highlights the need to develop better schemes that can allow for OOD generalization under noise for AIDD.
Generalization Bounds for Stochastic Gradient Langevin Dynamics: A Unified View via Information Leakage Analysis
Dec 14, 2021

Recently, generalization bounds of the non-convex empirical risk minimization paradigm using Stochastic Gradient Langevin Dynamics (SGLD) have been extensively studied. Several theoretical frameworks have been presented to study this problem from different perspectives, such as information theory and stability. In this paper, we present a unified view from privacy leakage analysis to investigate the generalization bounds of SGLD, along with a theoretical framework for re-deriving previous results in a succinct manner. Aside from theoretical findings, we conduct various numerical studies to empirically assess the information leakage issue of SGLD. Additionally, our theoretical and empirical results provide explanations for prior works that study the membership privacy of SGLD.
HASCO: Towards Agile HArdware and Software CO-design for Tensor Computation
May 04, 2021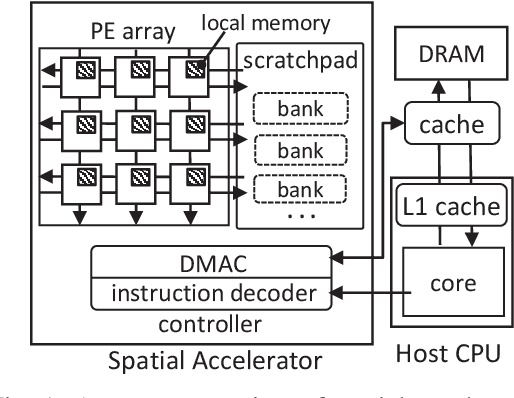
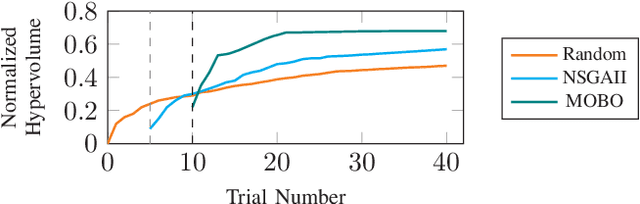
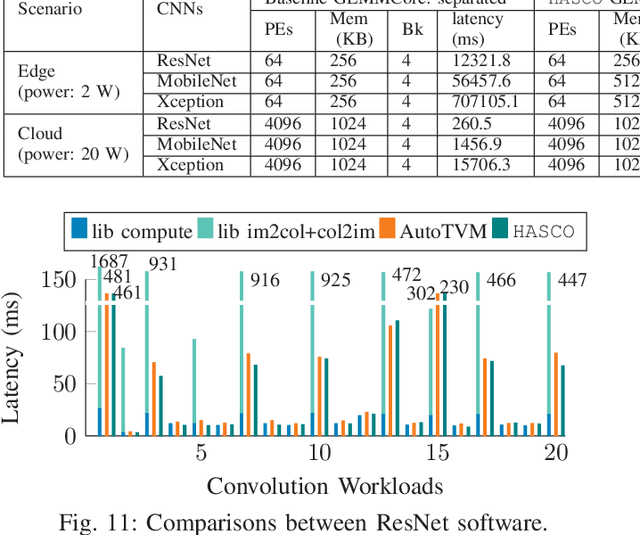
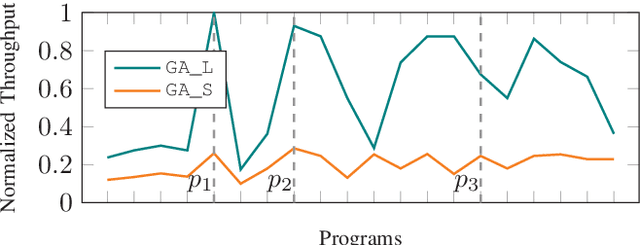
Tensor computations overwhelm traditional general-purpose computing devices due to the large amounts of data and operations of the computations. They call for a holistic solution composed of both hardware acceleration and software mapping. Hardware/software (HW/SW) co-design optimizes the hardware and software in concert and produces high-quality solutions. There are two main challenges in the co-design flow. First, multiple methods exist to partition tensor computation and have different impacts on performance and energy efficiency. Besides, the hardware part must be implemented by the intrinsic functions of spatial accelerators. It is hard for programmers to identify and analyze the partitioning methods manually. Second, the overall design space composed of HW/SW partitioning, hardware optimization, and software optimization is huge. The design space needs to be efficiently explored. To this end, we propose an agile co-design approach HASCO that provides an efficient HW/SW solution to dense tensor computation. We use tensor syntax trees as the unified IR, based on which we develop a two-step approach to identify partitioning methods. For each method, HASCO explores the hardware and software design spaces. We propose different algorithms for the explorations, as they have distinct objectives and evaluation costs. Concretely, we develop a multi-objective Bayesian optimization algorithm to explore hardware optimization. For software optimization, we use heuristic and Q-learning algorithms. Experiments demonstrate that HASCO achieves a 1.25X to 1.44X latency reduction through HW/SW co-design compared with developing the hardware and software separately.
Towards Scalable and Privacy-Preserving Deep Neural Network via Algorithmic-Cryptographic Co-design
Dec 17, 2020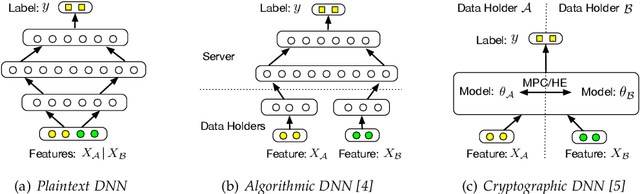
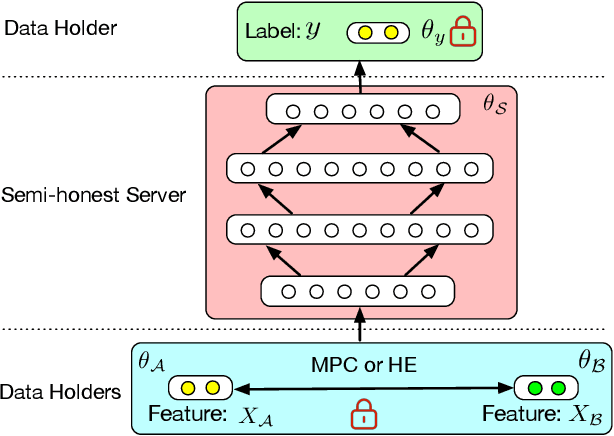
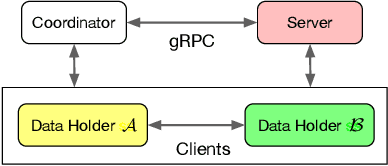

Deep Neural Networks (DNNs) have achieved remarkable progress in various real-world applications, especially when abundant training data are provided. However, data isolation has become a serious problem currently. Existing works build privacy preserving DNN models from either algorithmic perspective or cryptographic perspective. The former mainly splits the DNN computation graph between data holders or between data holders and server, which demonstrates good scalability but suffers from accuracy loss and potential privacy risks. In contrast, the latter leverages time-consuming cryptographic techniques, which has strong privacy guarantee but poor scalability. In this paper, we propose SPNN - a Scalable and Privacy-preserving deep Neural Network learning framework, from algorithmic-cryptographic co-perspective. From algorithmic perspective, we split the computation graph of DNN models into two parts, i.e., the private data related computations that are performed by data holders and the rest heavy computations that are delegated to a server with high computation ability. From cryptographic perspective, we propose using two types of cryptographic techniques, i.e., secret sharing and homomorphic encryption, for the isolated data holders to conduct private data related computations privately and cooperatively. Furthermore, we implement SPNN in a decentralized setting and introduce user-friendly APIs. Experimental results conducted on real-world datasets demonstrate the superiority of SPNN.