 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow LLMs Are Persuaded: A Few Attention Heads, Rerouted
May 10, 2026Language models can be persuaded to abandon factual knowledge. This vulnerability is central to AI safety, but its internal mechanism remains poorly understood. We uncover a compact causal mechanism for persuasion-induced factual errors. A small set of mid-layer attention heads almost entirely determines the model's answer. These heads write answer options into a low-dimensional polyhedron, with options occupying distinct vertices. Persuasion does not blur belief or merely reduce confidence; it causes a discrete latent jump from the correct-answer vertex to the persuasion-target vertex. We show that decision heads are not reasoning over evidence. Instead, they copy whichever option token their attention selects. Persuasion works by redirecting attention. We isolate a rank-one evidence-routing feature that controls the route. Directly modifying this feature steers the model's choice, and removing it blocks persuasion. We then trace the feature back to a band of shallower attention heads that build it from persuasive keywords in the input. Every step is validated by intervention. This mechanism appears across open-source LLMs and realistic poisoning scenarios such as Generative Engine Optimization, revealing persuasion as a narrow, monitorable circuit.
NeighborMAE: Exploiting Spatial Dependencies between Neighboring Earth Observation Images in Masked Autoencoders Pretraining
Mar 03, 2026Masked Image Modeling has been one of the most popular self-supervised learning paradigms to learn representations from large-scale, unlabeled Earth Observation images. While incorporating multi-modal and multi-temporal Earth Observation data into Masked Image Modeling has been widely explored, the spatial dependencies between images captured from neighboring areas remains largely overlooked. Since the Earth's surface is continuous, neighboring images are highly related and offer rich contextual information for self-supervised learning. To close this gap, we propose NeighborMAE, which learns spatial dependencies by joint reconstruction of neighboring Earth Observation images. To ensure that the reconstruction remains challenging, we leverage a heuristic strategy to dynamically adjust the mask ratio and the pixel-level loss weight. Experimental results across various pretraining datasets and downstream tasks show that NeighborMAE significantly outperforms existing baselines, underscoring the value of neighboring images in Masked Image Modeling for Earth Observation and the efficacy of our designs.
SkyReels-V4: Multi-modal Video-Audio Generation, Inpainting and Editing model
Feb 26, 2026SkyReels V4 is a unified multi modal video foundation model for joint video audio generation, inpainting, and editing. The model adopts a dual stream Multimodal Diffusion Transformer (MMDiT) architecture, where one branch synthesizes video and the other generates temporally aligned audio, while sharing a powerful text encoder based on the Multimodal Large Language Models (MMLM). SkyReels V4 accepts rich multi modal instructions, including text, images, video clips, masks, and audio references. By combining the MMLMs multi modal instruction following capability with in context learning in the video branch MMDiT, the model can inject fine grained visual guidance under complex conditioning, while the audio branch MMDiT simultaneously leverages audio references to guide sound generation. On the video side, we adopt a channel concatenation formulation that unifies a wide range of inpainting style tasks, such as image to video, video extension, and video editing under a single interface, and naturally extends to vision referenced inpainting and editing via multi modal prompts. SkyReels V4 supports up to 1080p resolution, 32 FPS, and 15 second duration, enabling high fidelity, multi shot, cinema level video generation with synchronized audio. To make such high resolution, long-duration generation computationally feasible, we introduce an efficiency strategy: Joint generation of low resolution full sequences and high-resolution keyframes, followed by dedicated super-resolution and frame interpolation models. To our knowledge, SkyReels V4 is the first video foundation model that simultaneously supports multi-modal input, joint video audio generation, and a unified treatment of generation, inpainting, and editing, while maintaining strong efficiency and quality at cinematic resolutions and durations.
G-LNS: Generative Large Neighborhood Search for LLM-Based Automatic Heuristic Design
Feb 09, 2026While Large Language Models (LLMs) have recently shown promise in Automated Heuristic Design (AHD), existing approaches typically formulate AHD around constructive priority rules or parameterized local search guidance, thereby restricting the search space to fixed heuristic forms. Such designs offer limited capacity for structural exploration, making it difficult to escape deep local optima in complex Combinatorial Optimization Problems (COPs). In this work, we propose G-LNS, a generative evolutionary framework that extends LLM-based AHD to the automated design of Large Neighborhood Search (LNS) operators. Unlike prior methods that evolve heuristics in isolation, G-LNS leverages LLMs to co-evolve tightly coupled pairs of destroy and repair operators. A cooperative evaluation mechanism explicitly captures their interaction, enabling the discovery of complementary operator logic that jointly performs effective structural disruption and reconstruction. Extensive experiments on challenging COP benchmarks, such as Traveling Salesman Problems (TSP) and Capacitated Vehicle Routing Problems (CVRP), demonstrate that G-LNS significantly outperforms LLM-based AHD methods as well as strong classical solvers. The discovered heuristics not only achieve near-optimal solutions with reduced computational budgets but also exhibit robust generalization across diverse and unseen instance distributions.
OneRec-V2 Technical Report
Aug 28, 2025



Recent breakthroughs in generative AI have transformed recommender systems through end-to-end generation. OneRec reformulates recommendation as an autoregressive generation task, achieving high Model FLOPs Utilization. While OneRec-V1 has shown significant empirical success in real-world deployment, two critical challenges hinder its scalability and performance: (1) inefficient computational allocation where 97.66% of resources are consumed by sequence encoding rather than generation, and (2) limitations in reinforcement learning relying solely on reward models. To address these challenges, we propose OneRec-V2, featuring: (1) Lazy Decoder-Only Architecture: Eliminates encoder bottlenecks, reducing total computation by 94% and training resources by 90%, enabling successful scaling to 8B parameters. (2) Preference Alignment with Real-World User Interactions: Incorporates Duration-Aware Reward Shaping and Adaptive Ratio Clipping to better align with user preferences using real-world feedback. Extensive A/B tests on Kuaishou demonstrate OneRec-V2's effectiveness, improving App Stay Time by 0.467%/0.741% while balancing multi-objective recommendations. This work advances generative recommendation scalability and alignment with real-world feedback, representing a step forward in the development of end-to-end recommender systems.
Skywork-Reward-V2: Scaling Preference Data Curation via Human-AI Synergy
Jul 02, 2025Despite the critical role of reward models (RMs) in reinforcement learning from human feedback (RLHF), current state-of-the-art open RMs perform poorly on most existing evaluation benchmarks, failing to capture the spectrum of nuanced and sophisticated human preferences. Even approaches that incorporate advanced training techniques have not yielded meaningful performance improvements. We hypothesize that this brittleness stems primarily from limitations in preference datasets, which are often narrowly scoped, synthetically labeled, or lack rigorous quality control. To address these challenges, we present a large-scale preference dataset comprising 40 million preference pairs, named SynPref-40M. To enable data curation at scale, we design a human-AI synergistic two-stage pipeline that leverages the complementary strengths of human annotation quality and AI scalability. In this pipeline, humans provide verified annotations, while large language models perform automatic curation based on human guidance. Training on this preference mixture, we introduce Skywork-Reward-V2, a suite of eight reward models ranging from 0.6B to 8B parameters, trained on a carefully curated subset of 26 million preference pairs from SynPref-40M. We demonstrate that Skywork-Reward-V2 is versatile across a wide range of capabilities, including alignment with human preferences, objective correctness, safety, resistance to stylistic biases, and best-of-N scaling, achieving state-of-the-art performance across seven major reward model benchmarks. Ablation studies confirm that the effectiveness of our approach stems not only from data scale but also from high-quality curation. The Skywork-Reward-V2 series represents substantial progress in open reward models, highlighting the untapped potential of existing preference datasets and demonstrating how human-AI curation synergy can unlock significantly higher data quality.
Skywork-SWE: Unveiling Data Scaling Laws for Software Engineering in LLMs
Jun 24, 2025Software engineering (SWE) has recently emerged as a crucial testbed for next-generation LLM agents, demanding inherent capabilities in two critical dimensions: sustained iterative problem-solving (e.g., >50 interaction rounds) and long-context dependency resolution (e.g., >32k tokens). However, the data curation process in SWE remains notoriously time-consuming, as it heavily relies on manual annotation for code file filtering and the setup of dedicated runtime environments to execute and validate unit tests. Consequently, most existing datasets are limited to only a few thousand GitHub-sourced instances. To this end, we propose an incremental, automated data-curation pipeline that systematically scales both the volume and diversity of SWE datasets. Our dataset comprises 10,169 real-world Python task instances from 2,531 distinct GitHub repositories, each accompanied by a task specified in natural language and a dedicated runtime-environment image for automated unit-test validation. We have carefully curated over 8,000 successfully runtime-validated training trajectories from our proposed SWE dataset. When fine-tuning the Skywork-SWE model on these trajectories, we uncover a striking data scaling phenomenon: the trained model's performance for software engineering capabilities in LLMs continues to improve as the data size increases, showing no signs of saturation. Notably, our Skywork-SWE model achieves 38.0% pass@1 accuracy on the SWE-bench Verified benchmark without using verifiers or multiple rollouts, establishing a new state-of-the-art (SOTA) among the Qwen2.5-Coder-32B-based LLMs built on the OpenHands agent framework. Furthermore, with the incorporation of test-time scaling techniques, the performance further improves to 47.0% accuracy, surpassing the previous SOTA results for sub-32B parameter models. We release the Skywork-SWE-32B model checkpoint to accelerate future research.
OneRec Technical Report
Jun 16, 2025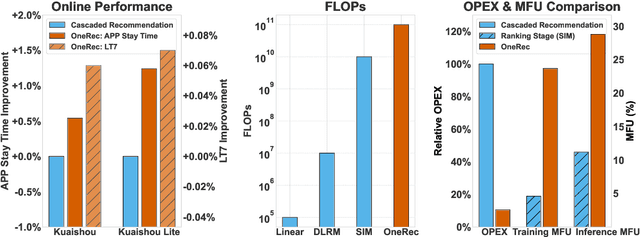

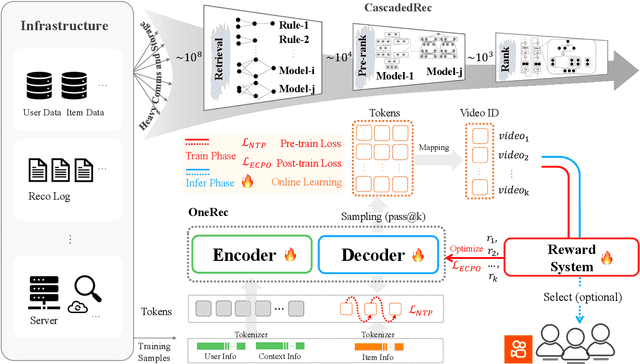
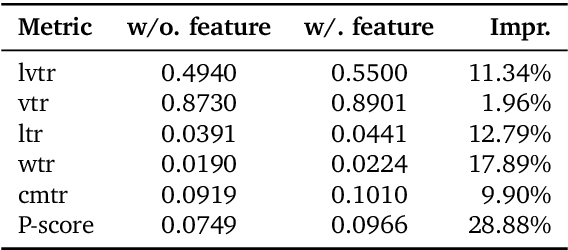
Recommender systems have been widely used in various large-scale user-oriented platforms for many years. However, compared to the rapid developments in the AI community, recommendation systems have not achieved a breakthrough in recent years. For instance, they still rely on a multi-stage cascaded architecture rather than an end-to-end approach, leading to computational fragmentation and optimization inconsistencies, and hindering the effective application of key breakthrough technologies from the AI community in recommendation scenarios. To address these issues, we propose OneRec, which reshapes the recommendation system through an end-to-end generative approach and achieves promising results. Firstly, we have enhanced the computational FLOPs of the current recommendation model by 10 $\times$ and have identified the scaling laws for recommendations within certain boundaries. Secondly, reinforcement learning techniques, previously difficult to apply for optimizing recommendations, show significant potential in this framework. Lastly, through infrastructure optimizations, we have achieved 23.7% and 28.8% Model FLOPs Utilization (MFU) on flagship GPUs during training and inference, respectively, aligning closely with the LLM community. This architecture significantly reduces communication and storage overhead, resulting in operating expense that is only 10.6% of traditional recommendation pipelines. Deployed in Kuaishou/Kuaishou Lite APP, it handles 25% of total queries per second, enhancing overall App Stay Time by 0.54% and 1.24%, respectively. Additionally, we have observed significant increases in metrics such as 7-day Lifetime, which is a crucial indicator of recommendation experience. We also provide practical lessons and insights derived from developing, optimizing, and maintaining a production-scale recommendation system with significant real-world impact.
Skywork Open Reasoner 1 Technical Report
May 29, 2025The success of DeepSeek-R1 underscores the significant role of reinforcement learning (RL) in enhancing the reasoning capabilities of large language models (LLMs). In this work, we present Skywork-OR1, an effective and scalable RL implementation for long Chain-of-Thought (CoT) models. Building on the DeepSeek-R1-Distill model series, our RL approach achieves notable performance gains, increasing average accuracy across AIME24, AIME25, and LiveCodeBench from 57.8% to 72.8% (+15.0%) for the 32B model and from 43.6% to 57.5% (+13.9%) for the 7B model. Our Skywork-OR1-32B model surpasses both DeepSeek-R1 and Qwen3-32B on the AIME24 and AIME25 benchmarks, while achieving comparable results on LiveCodeBench. The Skywork-OR1-7B and Skywork-OR1-Math-7B models demonstrate competitive reasoning capabilities among models of similar size. We perform comprehensive ablation studies on the core components of our training pipeline to validate their effectiveness. Additionally, we thoroughly investigate the phenomenon of entropy collapse, identify key factors affecting entropy dynamics, and demonstrate that mitigating premature entropy collapse is critical for improved test performance. To support community research, we fully open-source our model weights, training code, and training datasets.
Policy-to-Language: Train LLMs to Explain Decisions with Flow-Matching Generated Rewards
Feb 18, 2025As humans increasingly share environments with diverse agents powered by RL, LLMs, and beyond, the ability to explain their policies in natural language will be vital for reliable coexistence. In this paper, we build a model-agnostic explanation generator based on an LLM. The technical novelty is that the rewards for training this LLM are generated by a generative flow matching model. This model has a specially designed structure with a hidden layer merged with an LLM to harness the linguistic cues of explanations into generating appropriate rewards. Experiments on both RL and LLM tasks demonstrate that our method can generate dense and effective rewards while saving on expensive human feedback; it thus enables effective explanations and even improves the accuracy of the decisions in original tasks.