 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Adaptive Robotics Framework for Chemistry Lab Automation
Dec 19, 2022In the process of materials discovery, chemists currently need to perform many laborious, time-consuming, and often dangerous lab experiments. To accelerate this process, we propose a framework for robots to assist chemists by performing lab experiments autonomously. The solution allows a general-purpose robot to perform diverse chemistry experiments and efficiently make use of available lab tools. Our system can load high-level descriptions of chemistry experiments, perceive a dynamic workspace, and autonomously plan the required actions and motions to perform the given chemistry experiments with common tools found in the existing lab environment. Our architecture uses a modified PDDLStream solver for integrated task and constrained motion planning, which generates plans and motions that are guaranteed to be safe by preventing collisions and spillage. We present a modular framework that can scale to many different experiments, actions, and lab tools. In this work, we demonstrate the utility of our framework on three pouring skills and two foundational chemical experiments for materials synthesis: solubility and recrystallization. More experiments and updated evaluations can be found at https://ac-rad.github.io/arc-icra2023.
NeurIPS 2022 Competition: Driving SMARTS
Nov 14, 2022

Driving SMARTS is a regular competition designed to tackle problems caused by the distribution shift in dynamic interaction contexts that are prevalent in real-world autonomous driving (AD). The proposed competition supports methodologically diverse solutions, such as reinforcement learning (RL) and offline learning methods, trained on a combination of naturalistic AD data and open-source simulation platform SMARTS. The two-track structure allows focusing on different aspects of the distribution shift. Track 1 is open to any method and will give ML researchers with different backgrounds an opportunity to solve a real-world autonomous driving challenge. Track 2 is designed for strictly offline learning methods. Therefore, direct comparisons can be made between different methods with the aim to identify new promising research directions. The proposed setup consists of 1) realistic traffic generated using real-world data and micro simulators to ensure fidelity of the scenarios, 2) framework accommodating diverse methods for solving the problem, and 3) baseline method. As such it provides a unique opportunity for the principled investigation into various aspects of autonomous vehicle deployment.
nerf2nerf: Pairwise Registration of Neural Radiance Fields
Nov 03, 2022



We introduce a technique for pairwise registration of neural fields that extends classical optimization-based local registration (i.e. ICP) to operate on Neural Radiance Fields (NeRF) -- neural 3D scene representations trained from collections of calibrated images. NeRF does not decompose illumination and color, so to make registration invariant to illumination, we introduce the concept of a ''surface field'' -- a field distilled from a pre-trained NeRF model that measures the likelihood of a point being on the surface of an object. We then cast nerf2nerf registration as a robust optimization that iteratively seeks a rigid transformation that aligns the surface fields of the two scenes. We evaluate the effectiveness of our technique by introducing a dataset of pre-trained NeRF scenes -- our synthetic scenes enable quantitative evaluations and comparisons to classical registration techniques, while our real scenes demonstrate the validity of our technique in real-world scenarios. Additional results available at: https://nerf2nerf.github.io
Breaking Bad: A Dataset for Geometric Fracture and Reassembly
Oct 20, 2022

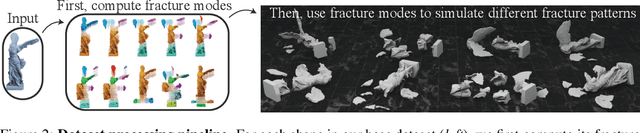

We introduce Breaking Bad, a large-scale dataset of fractured objects. Our dataset consists of over one million fractured objects simulated from ten thousand base models. The fracture simulation is powered by a recent physically based algorithm that efficiently generates a variety of fracture modes of an object. Existing shape assembly datasets decompose objects according to semantically meaningful parts, effectively modeling the construction process. In contrast, Breaking Bad models the destruction process of how a geometric object naturally breaks into fragments. Our dataset serves as a benchmark that enables the study of fractured object reassembly and presents new challenges for geometric shape understanding. We analyze our dataset with several geometry measurements and benchmark three state-of-the-art shape assembly deep learning methods under various settings. Extensive experimental results demonstrate the difficulty of our dataset, calling on future research in model designs specifically for the geometric shape assembly task. We host our dataset at https://breaking-bad-dataset.github.io/.
MoCoDA: Model-based Counterfactual Data Augmentation
Oct 20, 2022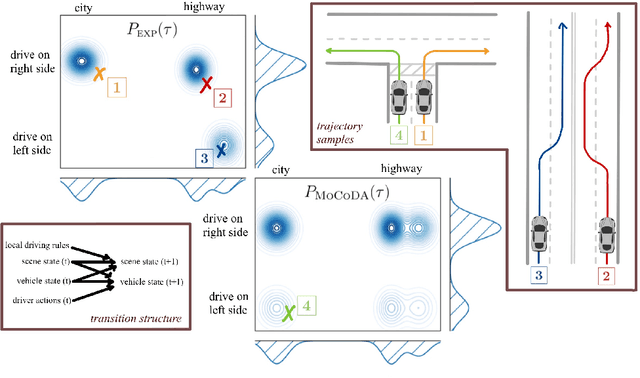
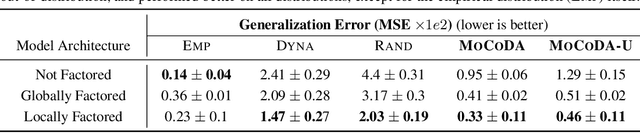
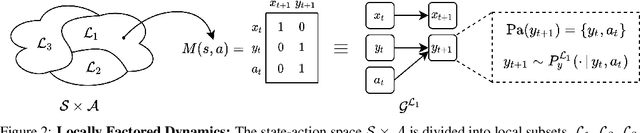
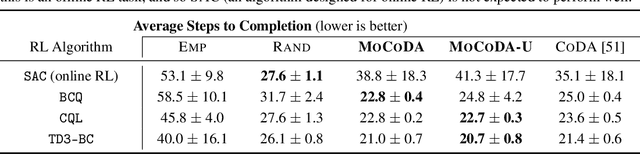
The number of states in a dynamic process is exponential in the number of objects, making reinforcement learning (RL) difficult in complex, multi-object domains. For agents to scale to the real world, they will need to react to and reason about unseen combinations of objects. We argue that the ability to recognize and use local factorization in transition dynamics is a key element in unlocking the power of multi-object reasoning. To this end, we show that (1) known local structure in the environment transitions is sufficient for an exponential reduction in the sample complexity of training a dynamics model, and (2) a locally factored dynamics model provably generalizes out-of-distribution to unseen states and actions. Knowing the local structure also allows us to predict which unseen states and actions this dynamics model will generalize to. We propose to leverage these observations in a novel Model-based Counterfactual Data Augmentation (MoCoDA) framework. MoCoDA applies a learned locally factored dynamics model to an augmented distribution of states and actions to generate counterfactual transitions for RL. MoCoDA works with a broader set of local structures than prior work and allows for direct control over the augmented training distribution. We show that MoCoDA enables RL agents to learn policies that generalize to unseen states and actions. We use MoCoDA to train an offline RL agent to solve an out-of-distribution robotics manipulation task on which standard offline RL algorithms fail.
SlotFormer: Unsupervised Visual Dynamics Simulation with Object-Centric Models
Oct 12, 2022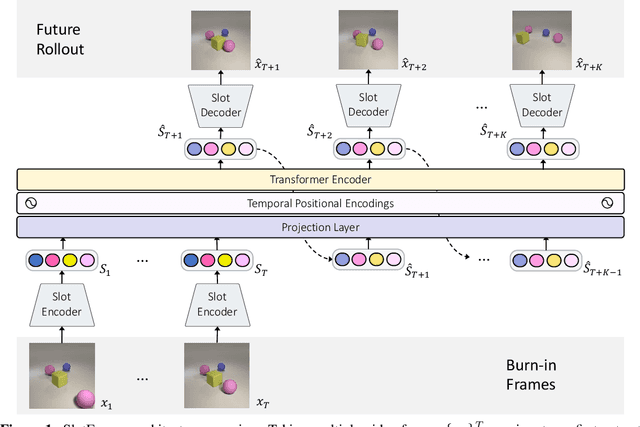
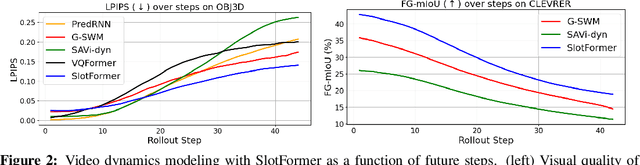
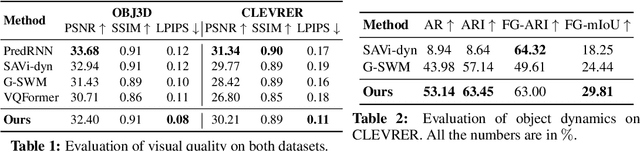
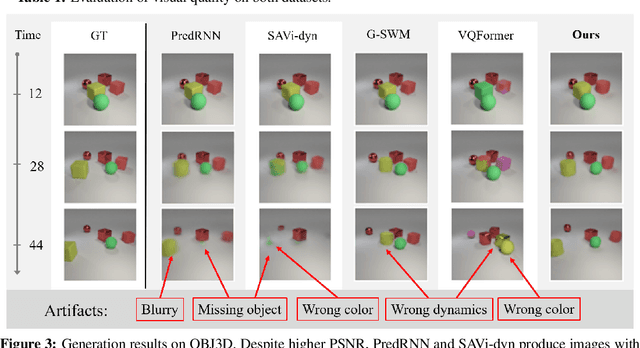
Understanding dynamics from visual observations is a challenging problem that requires disentangling individual objects from the scene and learning their interactions. While recent object-centric models can successfully decompose a scene into objects, modeling their dynamics effectively still remains a challenge. We address this problem by introducing SlotFormer -- a Transformer-based autoregressive model operating on learned object-centric representations. Given a video clip, our approach reasons over object features to model spatio-temporal relationships and predicts accurate future object states. In this paper, we successfully apply SlotFormer to perform video prediction on datasets with complex object interactions. Moreover, the unsupervised SlotFormer's dynamics model can be used to improve the performance on supervised downstream tasks, such as Visual Question Answering (VQA), and goal-conditioned planning. Compared to past works on dynamics modeling, our method achieves significantly better long-term synthesis of object dynamics, while retaining high quality visual generation. Besides, SlotFormer enables VQA models to reason about the future without object-level labels, even outperforming counterparts that use ground-truth annotations. Finally, we show its ability to serve as a world model for model-based planning, which is competitive with methods designed specifically for such tasks.
See, Plan, Predict: Language-guided Cognitive Planning with Video Prediction
Oct 07, 2022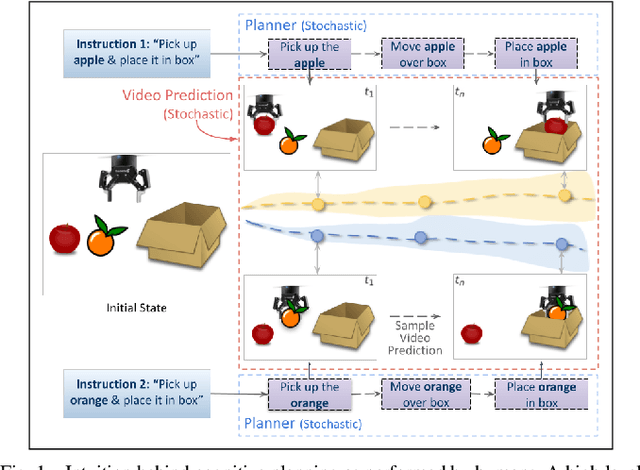
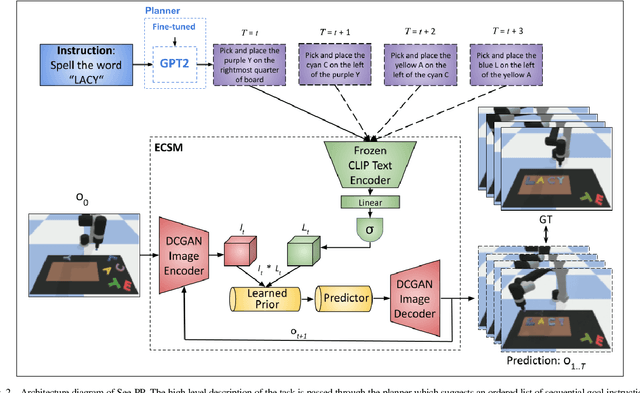
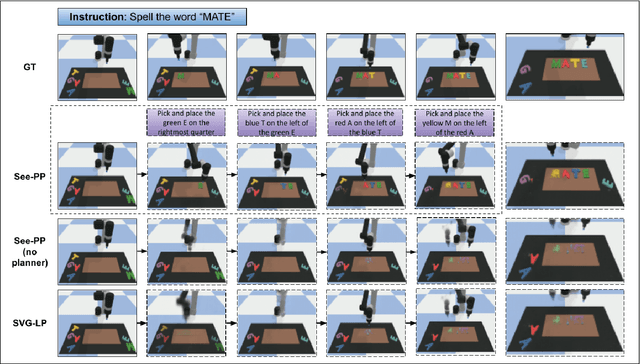

Cognitive planning is the structural decomposition of complex tasks into a sequence of future behaviors. In the computational setting, performing cognitive planning entails grounding plans and concepts in one or more modalities in order to leverage them for low level control. Since real-world tasks are often described in natural language, we devise a cognitive planning algorithm via language-guided video prediction. Current video prediction models do not support conditioning on natural language instructions. Therefore, we propose a new video prediction architecture which leverages the power of pre-trained transformers.The network is endowed with the ability to ground concepts based on natural language input with generalization to unseen objects. We demonstrate the effectiveness of this approach on a new simulation dataset, where each task is defined by a high-level action described in natural language. Our experiments compare our method again stone video generation baseline without planning or action grounding and showcase significant improvements. Our ablation studies highlight an improved generalization to unseen objects that natural language embeddings offer to concept grounding ability, as well as the importance of planning towards visual "imagination" of a task.
ProgPrompt: Generating Situated Robot Task Plans using Large Language Models
Sep 22, 2022
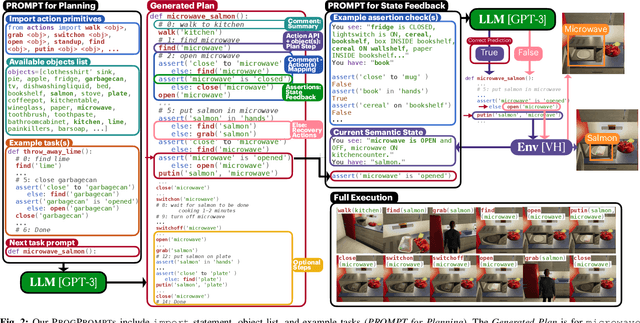


Task planning can require defining myriad domain knowledge about the world in which a robot needs to act. To ameliorate that effort, large language models (LLMs) can be used to score potential next actions during task planning, and even generate action sequences directly, given an instruction in natural language with no additional domain information. However, such methods either require enumerating all possible next steps for scoring, or generate free-form text that may contain actions not possible on a given robot in its current context. We present a programmatic LLM prompt structure that enables plan generation functional across situated environments, robot capabilities, and tasks. Our key insight is to prompt the LLM with program-like specifications of the available actions and objects in an environment, as well as with example programs that can be executed. We make concrete recommendations about prompt structure and generation constraints through ablation experiments, demonstrate state of the art success rates in VirtualHome household tasks, and deploy our method on a physical robot arm for tabletop tasks. Website at progprompt.github.io
Grasp'D: Differentiable Contact-rich Grasp Synthesis for Multi-fingered Hands
Aug 26, 2022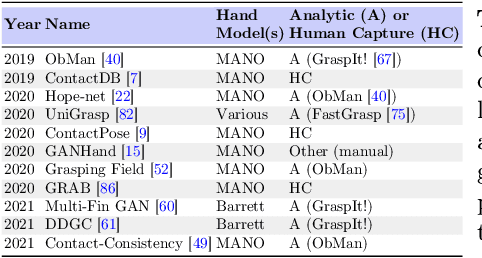


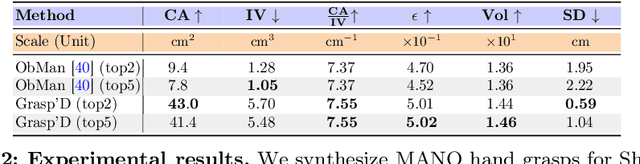
The study of hand-object interaction requires generating viable grasp poses for high-dimensional multi-finger models, often relying on analytic grasp synthesis which tends to produce brittle and unnatural results. This paper presents Grasp'D, an approach for grasp synthesis with a differentiable contact simulation from both known models as well as visual inputs. We use gradient-based methods as an alternative to sampling-based grasp synthesis, which fails without simplifying assumptions, such as pre-specified contact locations and eigengrasps. Such assumptions limit grasp discovery and, in particular, exclude high-contact power grasps. In contrast, our simulation-based approach allows for stable, efficient, physically realistic, high-contact grasp synthesis, even for gripper morphologies with high-degrees of freedom. We identify and address challenges in making grasp simulation amenable to gradient-based optimization, such as non-smooth object surface geometry, contact sparsity, and a rugged optimization landscape. Grasp'D compares favorably to analytic grasp synthesis on human and robotic hand models, and resultant grasps achieve over 4x denser contact, leading to significantly higher grasp stability. Video and code available at https://graspd-eccv22.github.io/.
Neural Motion Fields: Encoding Grasp Trajectories as Implicit Value Functions
Jun 29, 2022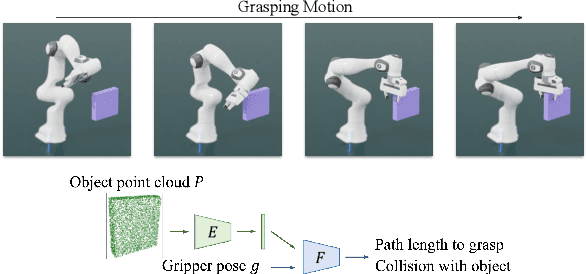
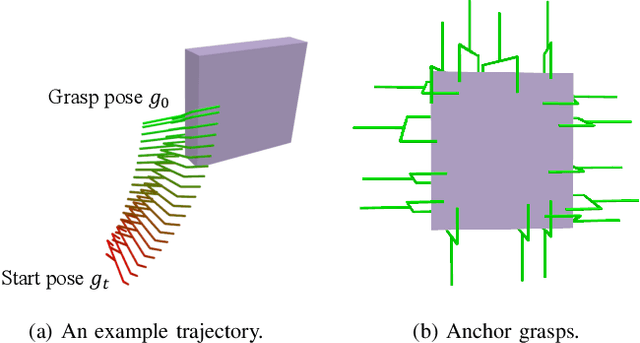


The pipeline of current robotic pick-and-place methods typically consists of several stages: grasp pose detection, finding inverse kinematic solutions for the detected poses, planning a collision-free trajectory, and then executing the open-loop trajectory to the grasp pose with a low-level tracking controller. While these grasping methods have shown good performance on grasping static objects on a table-top, the problem of grasping dynamic objects in constrained environments remains an open problem. We present Neural Motion Fields, a novel object representation which encodes both object point clouds and the relative task trajectories as an implicit value function parameterized by a neural network. This object-centric representation models a continuous distribution over the SE(3) space and allows us to perform grasping reactively by leveraging sampling-based MPC to optimize this value function.