 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-guided Controllable Mesh Refinement for Interactive 3D Modeling
Jun 03, 2024We propose a novel technique for adding geometric details to an input coarse 3D mesh guided by a text prompt. Our method is composed of three stages. First, we generate a single-view RGB image conditioned on the input coarse geometry and the input text prompt. This single-view image generation step allows the user to pre-visualize the result and offers stronger conditioning for subsequent multi-view generation. Second, we use our novel multi-view normal generation architecture to jointly generate six different views of the normal images. The joint view generation reduces inconsistencies and leads to sharper details. Third, we optimize our mesh with respect to all views and generate a fine, detailed geometry as output. The resulting method produces an output within seconds and offers explicit user control over the coarse structure, pose, and desired details of the resulting 3D mesh. Project page: https://text-mesh-refinement.github.io.
Neural Progressive Meshes
Aug 10, 2023The recent proliferation of 3D content that can be consumed on hand-held devices necessitates efficient tools for transmitting large geometric data, e.g., 3D meshes, over the Internet. Detailed high-resolution assets can pose a challenge to storage as well as transmission bandwidth, and level-of-detail techniques are often used to transmit an asset using an appropriate bandwidth budget. It is especially desirable for these methods to transmit data progressively, improving the quality of the geometry with more data. Our key insight is that the geometric details of 3D meshes often exhibit similar local patterns even across different shapes, and thus can be effectively represented with a shared learned generative space. We learn this space using a subdivision-based encoder-decoder architecture trained in advance on a large collection of surfaces. We further observe that additional residual features can be transmitted progressively between intermediate levels of subdivision that enable the client to control the tradeoff between bandwidth cost and quality of reconstruction, providing a neural progressive mesh representation. We evaluate our method on a diverse set of complex 3D shapes and demonstrate that it outperforms baselines in terms of compression ratio and reconstruction quality.
Breaking Bad: A Dataset for Geometric Fracture and Reassembly
Oct 20, 2022

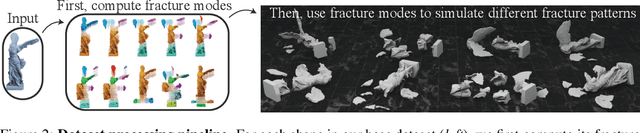

We introduce Breaking Bad, a large-scale dataset of fractured objects. Our dataset consists of over one million fractured objects simulated from ten thousand base models. The fracture simulation is powered by a recent physically based algorithm that efficiently generates a variety of fracture modes of an object. Existing shape assembly datasets decompose objects according to semantically meaningful parts, effectively modeling the construction process. In contrast, Breaking Bad models the destruction process of how a geometric object naturally breaks into fragments. Our dataset serves as a benchmark that enables the study of fractured object reassembly and presents new challenges for geometric shape understanding. We analyze our dataset with several geometry measurements and benchmark three state-of-the-art shape assembly deep learning methods under various settings. Extensive experimental results demonstrate the difficulty of our dataset, calling on future research in model designs specifically for the geometric shape assembly task. We host our dataset at https://breaking-bad-dataset.github.io/.
Grasp'D: Differentiable Contact-rich Grasp Synthesis for Multi-fingered Hands
Aug 26, 2022


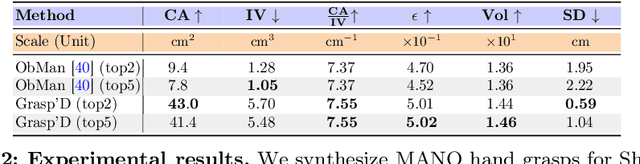
The study of hand-object interaction requires generating viable grasp poses for high-dimensional multi-finger models, often relying on analytic grasp synthesis which tends to produce brittle and unnatural results. This paper presents Grasp'D, an approach for grasp synthesis with a differentiable contact simulation from both known models as well as visual inputs. We use gradient-based methods as an alternative to sampling-based grasp synthesis, which fails without simplifying assumptions, such as pre-specified contact locations and eigengrasps. Such assumptions limit grasp discovery and, in particular, exclude high-contact power grasps. In contrast, our simulation-based approach allows for stable, efficient, physically realistic, high-contact grasp synthesis, even for gripper morphologies with high-degrees of freedom. We identify and address challenges in making grasp simulation amenable to gradient-based optimization, such as non-smooth object surface geometry, contact sparsity, and a rugged optimization landscape. Grasp'D compares favorably to analytic grasp synthesis on human and robotic hand models, and resultant grasps achieve over 4x denser contact, leading to significantly higher grasp stability. Video and code available at https://graspd-eccv22.github.io/.
Neural Motion Fields: Encoding Grasp Trajectories as Implicit Value Functions
Jun 29, 2022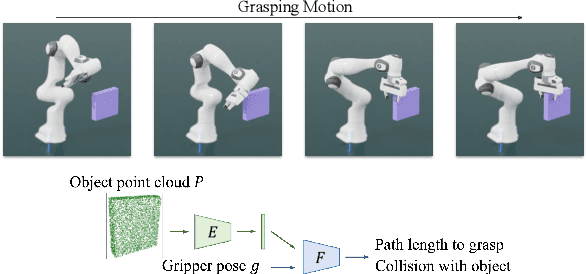
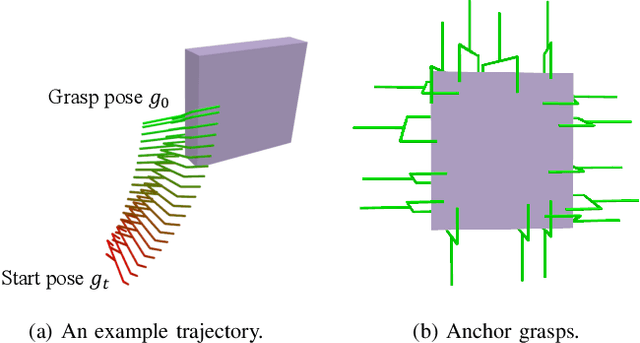


The pipeline of current robotic pick-and-place methods typically consists of several stages: grasp pose detection, finding inverse kinematic solutions for the detected poses, planning a collision-free trajectory, and then executing the open-loop trajectory to the grasp pose with a low-level tracking controller. While these grasping methods have shown good performance on grasping static objects on a table-top, the problem of grasping dynamic objects in constrained environments remains an open problem. We present Neural Motion Fields, a novel object representation which encodes both object point clouds and the relative task trajectories as an implicit value function parameterized by a neural network. This object-centric representation models a continuous distribution over the SE(3) space and allows us to perform grasping reactively by leveraging sampling-based MPC to optimize this value function.
Neural Shape Mating: Self-Supervised Object Assembly with Adversarial Shape Priors
May 30, 2022Learning to autonomously assemble shapes is a crucial skill for many robotic applications. While the majority of existing part assembly methods focus on correctly posing semantic parts to recreate a whole object, we interpret assembly more literally: as mating geometric parts together to achieve a snug fit. By focusing on shape alignment rather than semantic cues, we can achieve across-category generalization. In this paper, we introduce a novel task, pairwise 3D geometric shape mating, and propose Neural Shape Mating (NSM) to tackle this problem. Given the point clouds of two object parts of an unknown category, NSM learns to reason about the fit of the two parts and predict a pair of 3D poses that tightly mate them together. We couple the training of NSM with an implicit shape reconstruction task to make NSM more robust to imperfect point cloud observations. To train NSM, we present a self-supervised data collection pipeline that generates pairwise shape mating data with ground truth by randomly cutting an object mesh into two parts, resulting in a dataset that consists of 200K shape mating pairs from numerous object meshes with diverse cut types. We train NSM on the collected dataset and compare it with several point cloud registration methods and one part assembly baseline. Extensive experimental results and ablation studies under various settings demonstrate the effectiveness of the proposed algorithm. Additional material is available at: https://neural-shape-mating.github.io/
Self-Attentive 3D Human Pose and Shape Estimation from Videos
Mar 26, 2021
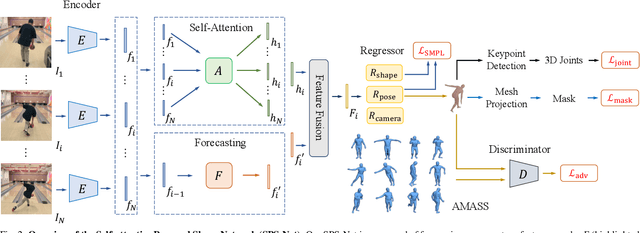
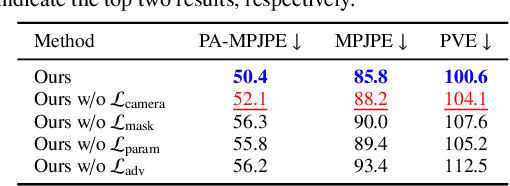
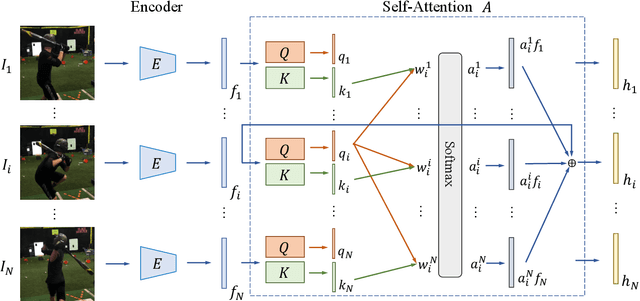
We consider the task of estimating 3D human pose and shape from videos. While existing frame-based approaches have made significant progress, these methods are independently applied to each image, thereby often leading to inconsistent predictions. In this work, we present a video-based learning algorithm for 3D human pose and shape estimation. The key insights of our method are two-fold. First, to address the inconsistent temporal prediction issue, we exploit temporal information in videos and propose a self-attention module that jointly considers short-range and long-range dependencies across frames, resulting in temporally coherent estimations. Second, we model human motion with a forecasting module that allows the transition between adjacent frames to be smooth. We evaluate our method on the 3DPW, MPI-INF-3DHP, and Human3.6M datasets. Extensive experimental results show that our algorithm performs favorably against the state-of-the-art methods.
Learning by Watching: Physical Imitation of Manipulation Skills from Human Videos
Jan 18, 2021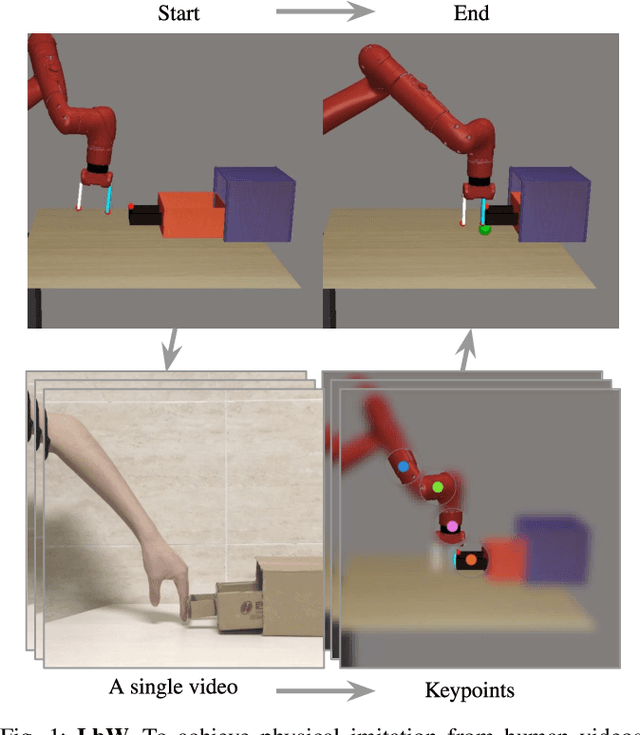
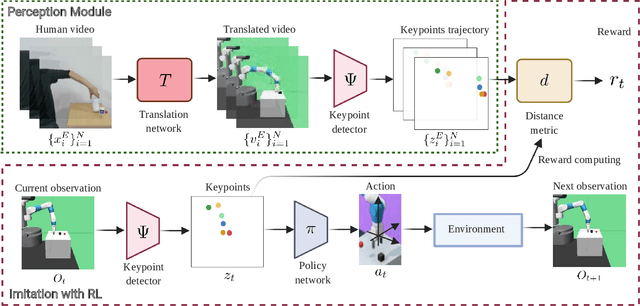
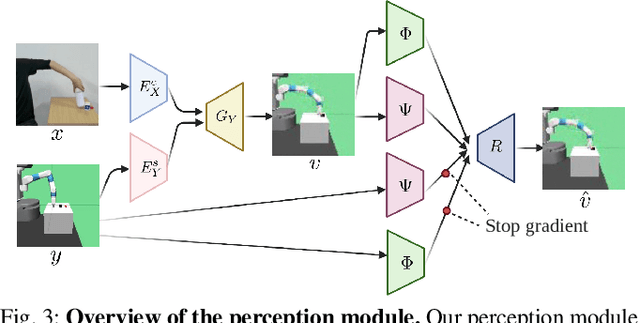

We present an approach for physical imitation from human videos for robot manipulation tasks. The key idea of our method lies in explicitly exploiting the kinematics and motion information embedded in the video to learn structured representations that endow the robot with the ability to imagine how to perform manipulation tasks in its own context. To achieve this, we design a perception module that learns to translate human videos to the robot domain followed by unsupervised keypoint detection. The resulting keypoint-based representations provide semantically meaningful information that can be directly used for reward computing and policy learning. We evaluate the effectiveness of our approach on five robot manipulation tasks, including reaching, pushing, sliding, coffee making, and drawer closing. Detailed experimental evaluations demonstrate that our method performs favorably against previous approaches.
NAS-DIP: Learning Deep Image Prior with Neural Architecture Search
Aug 26, 2020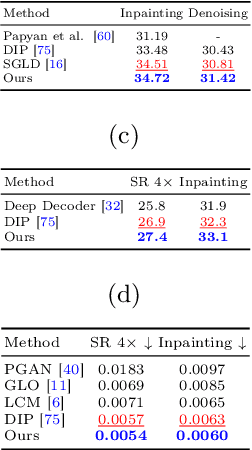
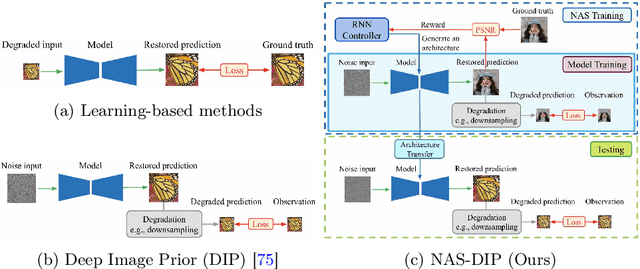

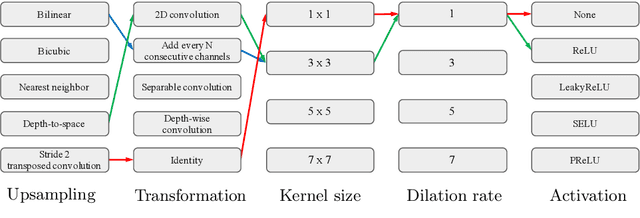
Recent work has shown that the structure of deep convolutional neural networks can be used as a structured image prior for solving various inverse image restoration tasks. Instead of using hand-designed architectures, we propose to search for neural architectures that capture stronger image priors. Building upon a generic U-Net architecture, our core contribution lies in designing new search spaces for (1) an upsampling cell and (2) a pattern of cross-scale residual connections. We search for an improved network by leveraging an existing neural architecture search algorithm (using reinforcement learning with a recurrent neural network controller). We validate the effectiveness of our method via a wide variety of applications, including image restoration, dehazing, image-to-image translation, and matrix factorization. Extensive experimental results show that our algorithm performs favorably against state-of-the-art learning-free approaches and reaches competitive performance with existing learning-based methods in some cases.
Learning to Learn in a Semi-Supervised Fashion
Aug 25, 2020
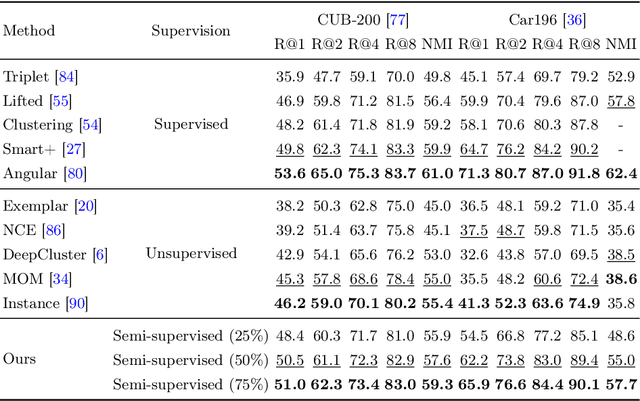


To address semi-supervised learning from both labeled and unlabeled data, we present a novel meta-learning scheme. We particularly consider that labeled and unlabeled data share disjoint ground truth label sets, which can be seen tasks like in person re-identification or image retrieval. Our learning scheme exploits the idea of leveraging information from labeled to unlabeled data. Instead of fitting the associated class-wise similarity scores as most meta-learning algorithms do, we propose to derive semantics-oriented similarity representations from labeled data, and transfer such representation to unlabeled ones. Thus, our strategy can be viewed as a self-supervised learning scheme, which can be applied to fully supervised learning tasks for improved performance. Our experiments on various tasks and settings confirm the effectiveness of our proposed approach and its superiority over the state-of-the-art methods.