 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Language Maps for Robot Navigation
Oct 17, 2022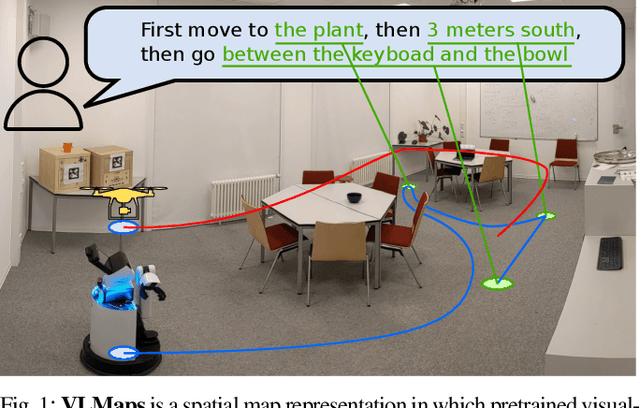

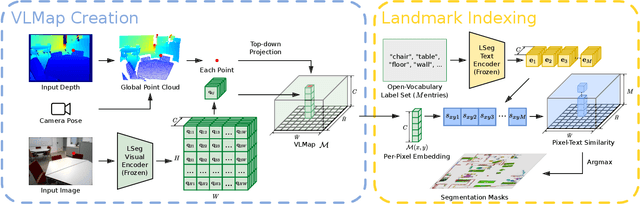

Grounding language to the visual observations of a navigating agent can be performed using off-the-shelf visual-language models pretrained on Internet-scale data (e.g., image captions). While this is useful for matching images to natural language descriptions of object goals, it remains disjoint from the process of mapping the environment, so that it lacks the spatial precision of classic geometric maps. To address this problem, we propose VLMaps, a spatial map representation that directly fuses pretrained visual-language features with a 3D reconstruction of the physical world. VLMaps can be autonomously built from video feed on robots using standard exploration approaches and enables natural language indexing of the map without additional labeled data. Specifically, when combined with large language models (LLMs), VLMaps can be used to (i) translate natural language commands into a sequence of open-vocabulary navigation goals (which, beyond prior work, can be spatial by construction, e.g., "in between the sofa and TV" or "three meters to the right of the chair") directly localized in the map, and (ii) can be shared among multiple robots with different embodiments to generate new obstacle maps on-the-fly (by using a list of obstacle categories). Extensive experiments carried out in simulated and real world environments show that VLMaps enable navigation according to more complex language instructions than existing methods. Videos are available at https://vlmaps.github.io.
VIRDO++: Real-World, Visuo-tactile Dynamics and Perception of Deformable Objects
Oct 07, 2022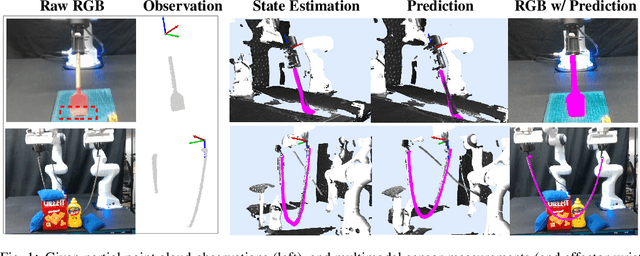
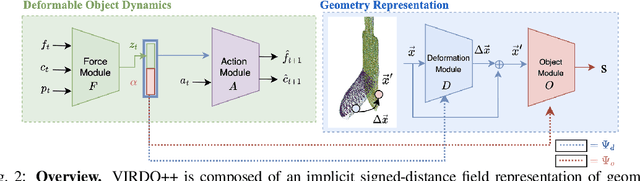
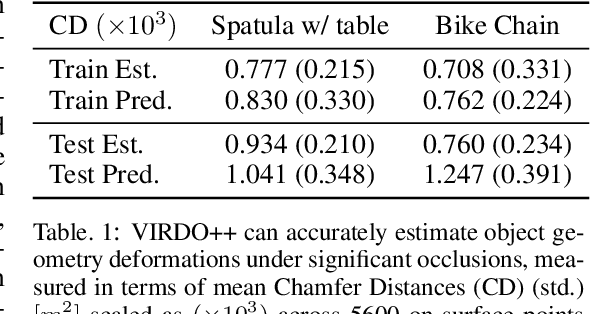
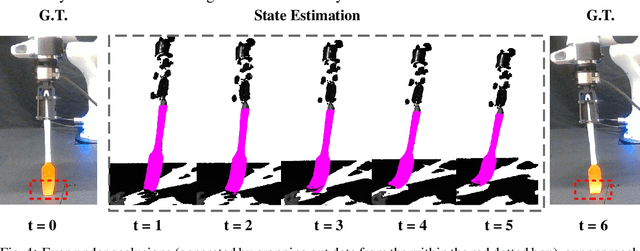
Deformable objects manipulation can benefit from representations that seamlessly integrate vision and touch while handling occlusions. In this work, we present a novel approach for, and real-world demonstration of, multimodal visuo-tactile state-estimation and dynamics prediction for deformable objects. Our approach, VIRDO++, builds on recent progress in multimodal neural implicit representations for deformable object state-estimation [1] via a new formulation for deformation dynamics and a complementary state-estimation algorithm that (i) maintains a belief over deformations, and (ii) enables practical real-world application by removing the need for privileged contact information. In the context of two real-world robotic tasks, we show:(i) high-fidelity cross-modal state-estimation and prediction of deformable objects from partial visuo-tactile feedback, and (ii) generalization to unseen objects and contact formations.
Code as Policies: Language Model Programs for Embodied Control
Sep 19, 2022

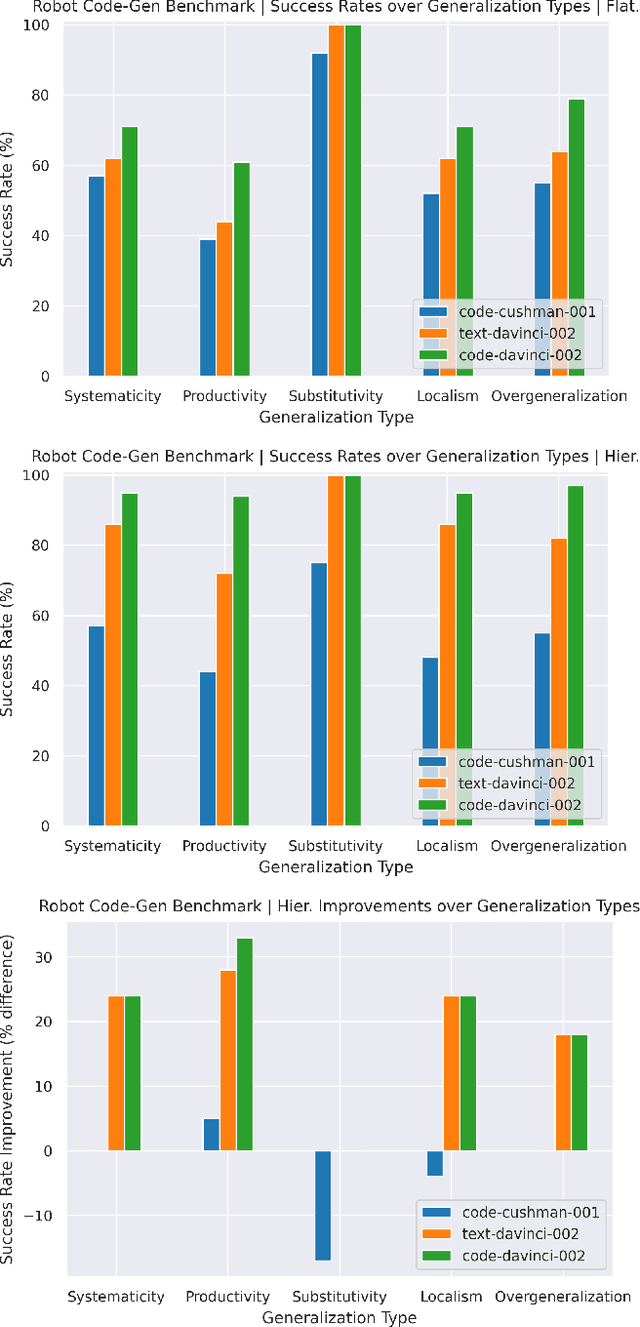
Large language models (LLMs) trained on code completion have been shown to be capable of synthesizing simple Python programs from docstrings [1]. We find that these code-writing LLMs can be re-purposed to write robot policy code, given natural language commands. Specifically, policy code can express functions or feedback loops that process perception outputs (e.g.,from object detectors [2], [3]) and parameterize control primitive APIs. When provided as input several example language commands (formatted as comments) followed by corresponding policy code (via few-shot prompting), LLMs can take in new commands and autonomously re-compose API calls to generate new policy code respectively. By chaining classic logic structures and referencing third-party libraries (e.g., NumPy, Shapely) to perform arithmetic, LLMs used in this way can write robot policies that (i) exhibit spatial-geometric reasoning, (ii) generalize to new instructions, and (iii) prescribe precise values (e.g., velocities) to ambiguous descriptions ("faster") depending on context (i.e., behavioral commonsense). This paper presents code as policies: a robot-centric formalization of language model generated programs (LMPs) that can represent reactive policies (e.g., impedance controllers), as well as waypoint-based policies (vision-based pick and place, trajectory-based control), demonstrated across multiple real robot platforms. Central to our approach is prompting hierarchical code-gen (recursively defining undefined functions), which can write more complex code and also improves state-of-the-art to solve 39.8% of problems on the HumanEval [1] benchmark. Code and videos are available at https://code-as-policies.github.io
Inner Monologue: Embodied Reasoning through Planning with Language Models
Jul 12, 2022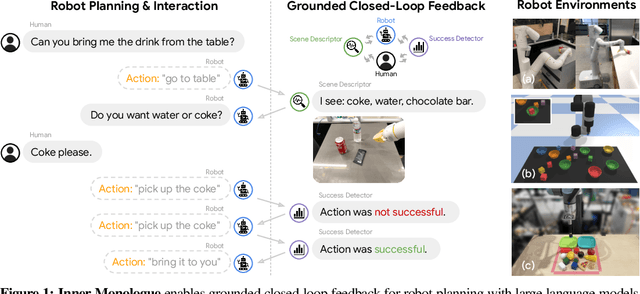


Recent works have shown how the reasoning capabilities of Large Language Models (LLMs) can be applied to domains beyond natural language processing, such as planning and interaction for robots. These embodied problems require an agent to understand many semantic aspects of the world: the repertoire of skills available, how these skills influence the world, and how changes to the world map back to the language. LLMs planning in embodied environments need to consider not just what skills to do, but also how and when to do them - answers that change over time in response to the agent's own choices. In this work, we investigate to what extent LLMs used in such embodied contexts can reason over sources of feedback provided through natural language, without any additional training. We propose that by leveraging environment feedback, LLMs are able to form an inner monologue that allows them to more richly process and plan in robotic control scenarios. We investigate a variety of sources of feedback, such as success detection, scene description, and human interaction. We find that closed-loop language feedback significantly improves high-level instruction completion on three domains, including simulated and real table top rearrangement tasks and long-horizon mobile manipulation tasks in a kitchen environment in the real world.
Learning to Fold Real Garments with One Arm: A Case Study in Cloud-Based Robotics Research
Apr 21, 2022


Autonomous fabric manipulation is a longstanding challenge in robotics, but evaluating progress is difficult due to the cost and diversity of robot hardware. Using Reach, a cloud robotics platform that enables low-latency remote execution of control policies on physical robots, we present the first systematic benchmarking of fabric manipulation algorithms on physical hardware. We develop 4 novel learning-based algorithms that model expert actions, keypoints, reward functions, and dynamic motions, and we compare these against 4 learning-free and inverse dynamics algorithms on the task of folding a crumpled T-shirt with a single robot arm. The entire lifecycle of data collection, model training, and policy evaluation is performed remotely without physical access to the robot workcell. Results suggest a new algorithm combining imitation learning with analytic methods achieves 84% of human-level performance on the folding task. See https://sites.google.com/berkeley.edu/cloudfolding for all data, code, models, and supplemental material.
Learning Pneumatic Non-Prehensile Manipulation with a Mobile Blower
Apr 05, 2022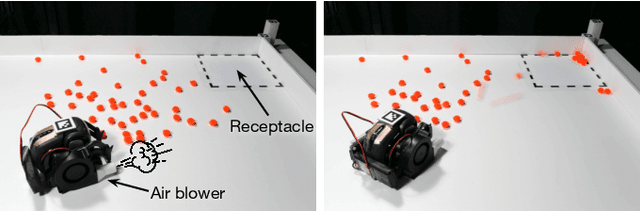

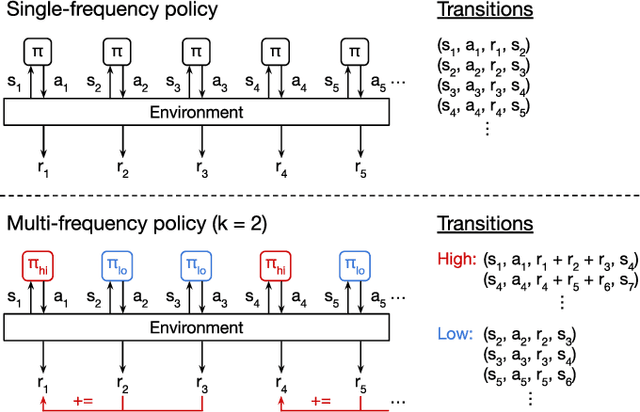
We investigate pneumatic non-prehensile manipulation (i.e., blowing) as a means of efficiently moving scattered objects into a target receptacle. Due to the chaotic nature of aerodynamic forces, a blowing controller must (i) continually adapt to unexpected changes from its actions, (ii) maintain fine-grained control, since the slightest misstep can result in large unintended consequences (e.g., scatter objects already in a pile), and (iii) infer long-range plans (e.g., move the robot to strategic blowing locations). We tackle these challenges in the context of deep reinforcement learning, introducing a multi-frequency version of the spatial action maps framework. This allows for efficient learning of vision-based policies that effectively combine high-level planning and low-level closed-loop control for dynamic mobile manipulation. Experiments show that our system learns efficient behaviors for the task, demonstrating in particular that blowing achieves better downstream performance than pushing, and that our policies improve performance over baselines. Moreover, we show that our system naturally encourages emergent specialization between the different subpolicies spanning low-level fine-grained control and high-level planning. On a real mobile robot equipped with a miniature air blower, we show that our simulation-trained policies transfer well to a real environment and can generalize to novel objects.
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
Apr 01, 2022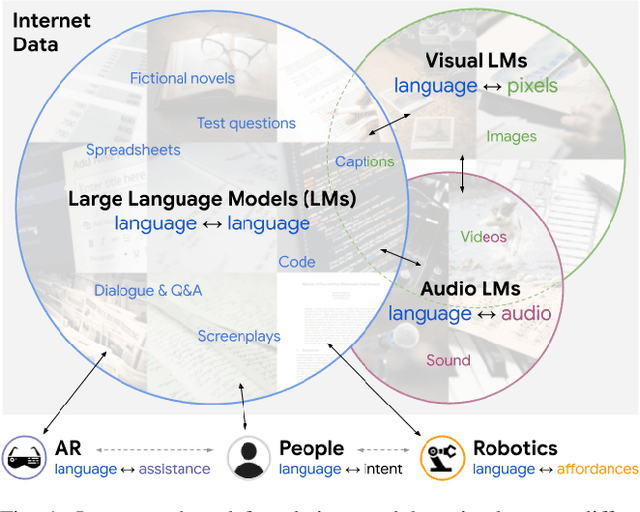
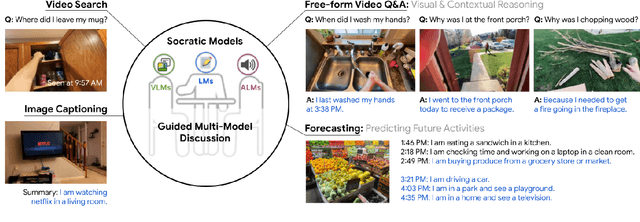
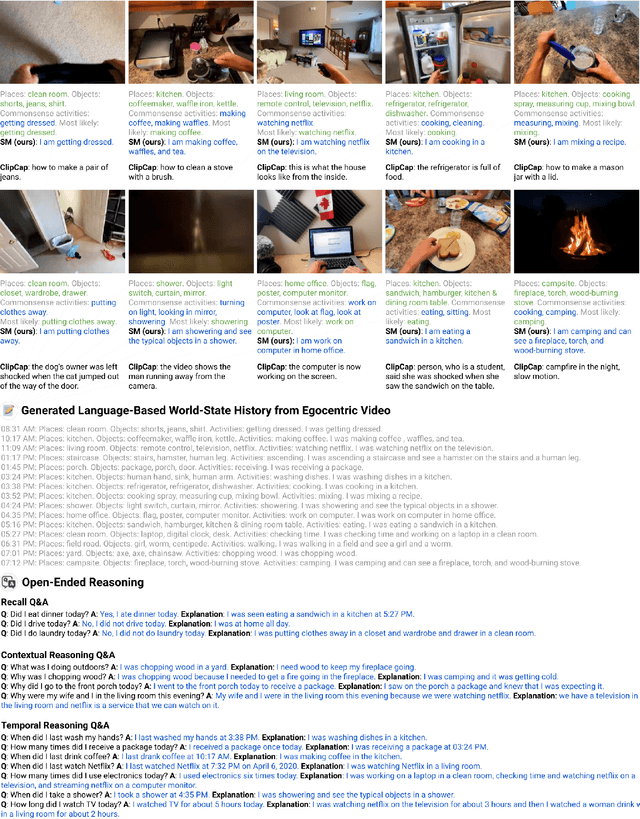
Large foundation models can exhibit unique capabilities depending on the domain of data they are trained on. While these domains are generic, they may only barely overlap. For example, visual-language models (VLMs) are trained on Internet-scale image captions, but large language models (LMs) are further trained on Internet-scale text with no images (e.g. from spreadsheets, to SAT questions). As a result, these models store different forms of commonsense knowledge across different domains. In this work, we show that this model diversity is symbiotic, and can be leveraged to build AI systems with structured Socratic dialogue -- in which new multimodal tasks are formulated as a guided language-based exchange between different pre-existing foundation models, without additional finetuning. In the context of egocentric perception, we present a case study of Socratic Models (SMs) that can provide meaningful results for complex tasks such as generating free-form answers to contextual questions about egocentric video, by formulating video Q&A as short story Q&A, i.e. summarizing the video into a short story, then answering questions about it. Additionally, SMs can generate captions for Internet images, and are competitive with state-of-the-art on zero-shot video-to-text retrieval with 42.8 R@1 on MSR-VTT 1k-A. SMs demonstrate how to compose foundation models zero-shot to capture new multimodal functionalities, without domain-specific data collection. Prototypes are available at socraticmodels.github.io.
Multiscale Sensor Fusion and Continuous Control with Neural CDEs
Mar 16, 2022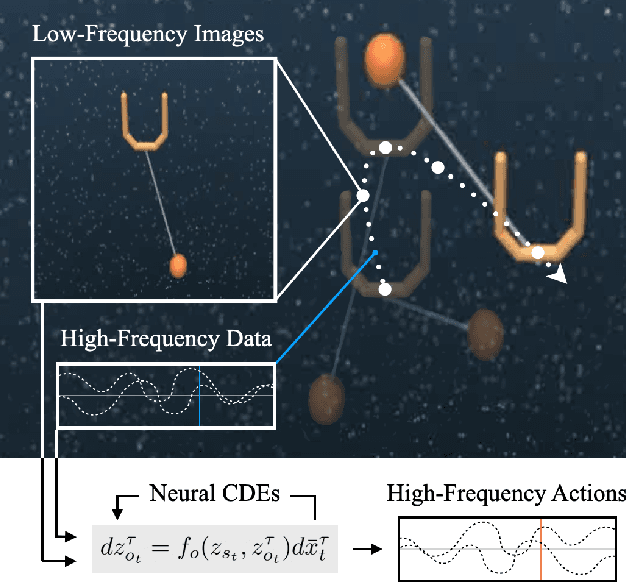
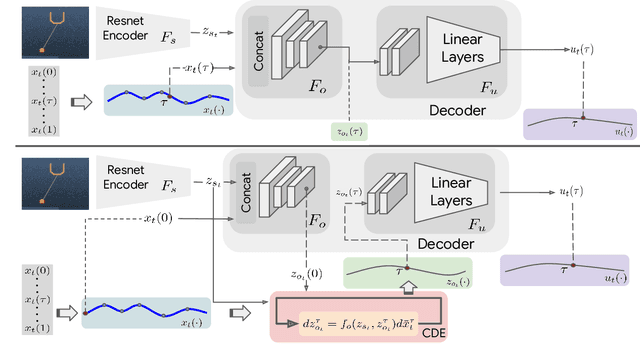
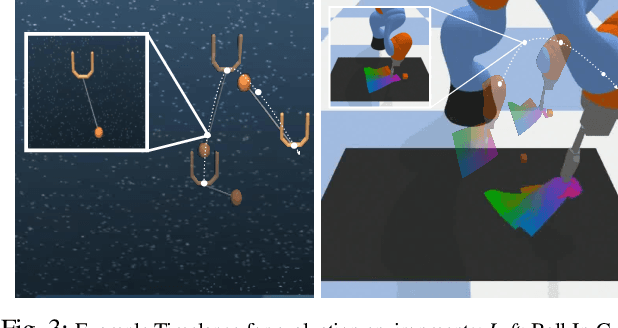
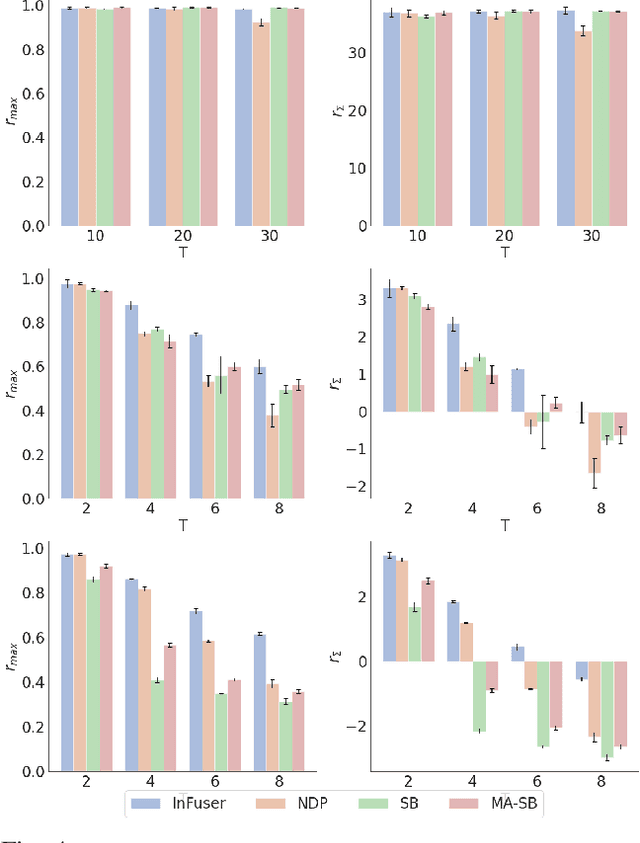
Though robot learning is often formulated in terms of discrete-time Markov decision processes (MDPs), physical robots require near-continuous multiscale feedback control. Machines operate on multiple asynchronous sensing modalities, each with different frequencies, e.g., video frames at 30Hz, proprioceptive state at 100Hz, force-torque data at 500Hz, etc. While the classic approach is to batch observations into fixed-time windows then pass them through feed-forward encoders (e.g., with deep networks), we show that there exists a more elegant approach -- one that treats policy learning as modeling latent state dynamics in continuous-time. Specifically, we present 'InFuser', a unified architecture that trains continuous time-policies with Neural Controlled Differential Equations (CDEs). InFuser evolves a single latent state representation over time by (In)tegrating and (Fus)ing multi-sensory observations (arriving at different frequencies), and inferring actions in continuous-time. This enables policies that can react to multi-frequency multi sensory feedback for truly end-to-end visuomotor control, without discrete-time assumptions. Behavior cloning experiments demonstrate that InFuser learns robust policies for dynamic tasks (e.g., swinging a ball into a cup) notably outperforming several baselines in settings where observations from one sensing modality can arrive at much sparser intervals than others.
Implicit Kinematic Policies: Unifying Joint and Cartesian Action Spaces in End-to-End Robot Learning
Mar 03, 2022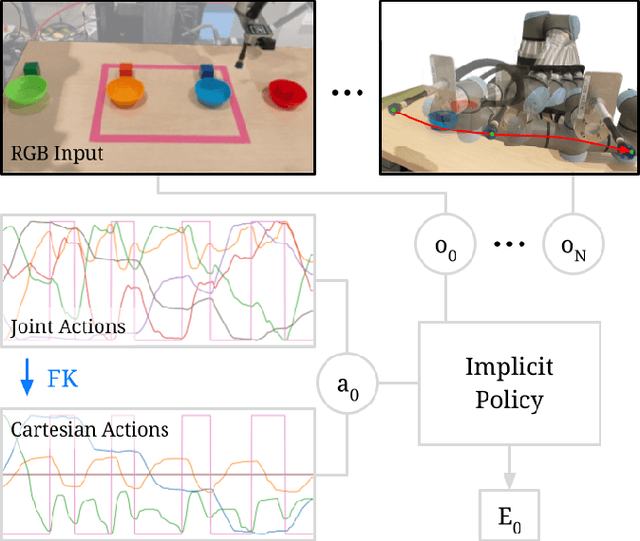
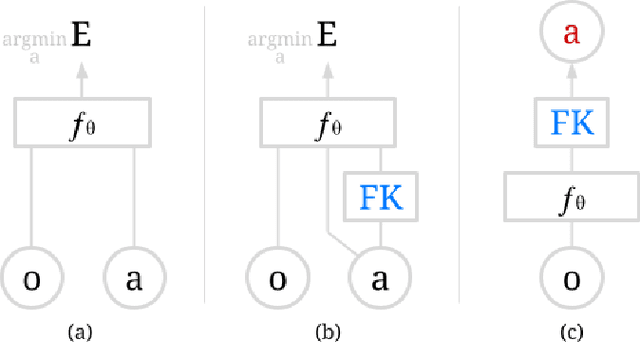
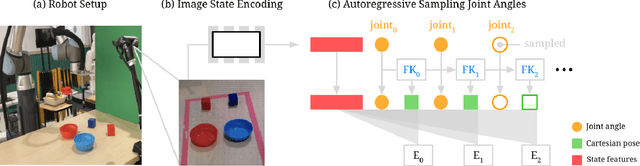
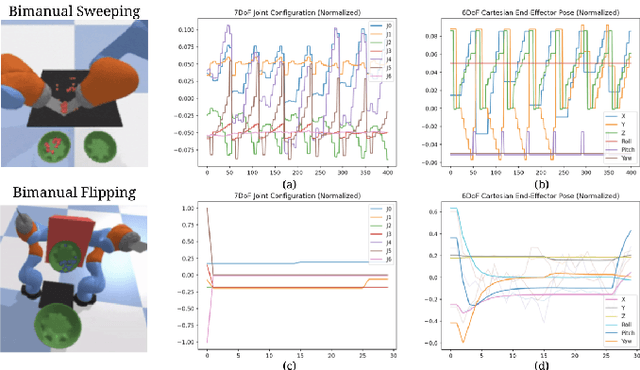
Action representation is an important yet often overlooked aspect in end-to-end robot learning with deep networks. Choosing one action space over another (e.g. target joint positions, or Cartesian end-effector poses) can result in surprisingly stark performance differences between various downstream tasks -- and as a result, considerable research has been devoted to finding the right action space for a given application. However, in this work, we instead investigate how our models can discover and learn for themselves which action space to use. Leveraging recent work on implicit behavioral cloning, which takes both observations and actions as input, we demonstrate that it is possible to present the same action in multiple different spaces to the same policy -- allowing it to learn inductive patterns from each space. Specifically, we study the benefits of combining Cartesian and joint action spaces in the context of learning manipulation skills. To this end, we present Implicit Kinematic Policies (IKP), which incorporates the kinematic chain as a differentiable module within the deep network. Quantitative experiments across several simulated continuous control tasks -- from scooping piles of small objects, to lifting boxes with elbows, to precise block insertion with miscalibrated robots -- suggest IKP not only learns complex prehensile and non-prehensile manipulation from pixels better than baseline alternatives, but also can learn to compensate for small joint encoder offset errors. Finally, we also run qualitative experiments on a real UR5e to demonstrate the feasibility of our algorithm on a physical robotic system with real data. See https://tinyurl.com/4wz3nf86 for code and supplementary material.
VIRDO: Visio-tactile Implicit Representations of Deformable Objects
Feb 02, 2022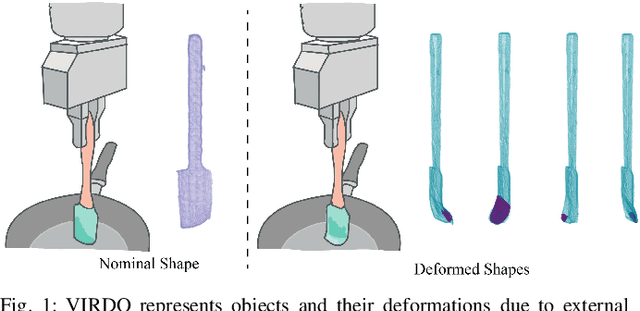
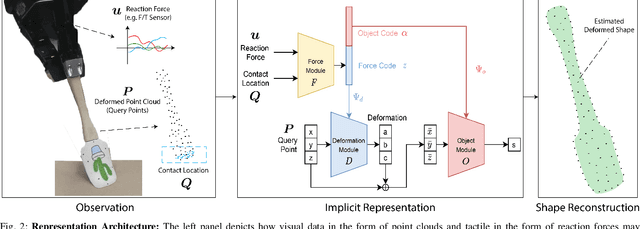
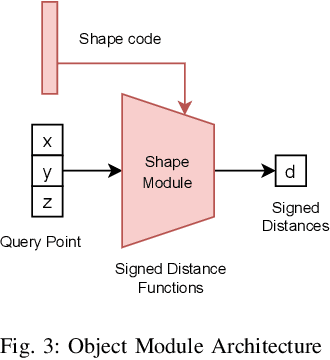
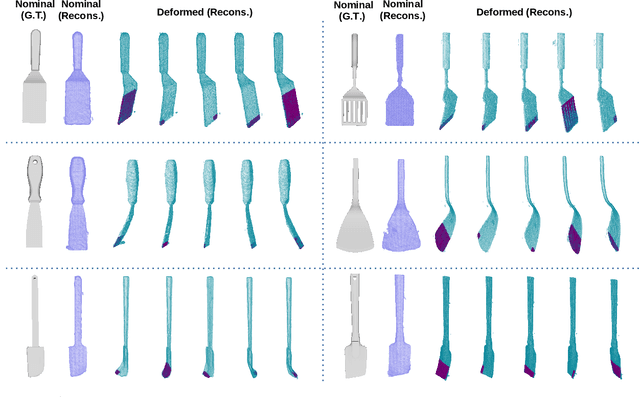
Deformable object manipulation requires computationally efficient representations that are compatible with robotic sensing modalities. In this paper, we present VIRDO:an implicit, multi-modal, and continuous representation for deformable-elastic objects. VIRDO operates directly on visual (point cloud) and tactile (reaction forces) modalities and learns rich latent embeddings of contact locations and forces to predict object deformations subject to external contacts.Here, we demonstrate VIRDOs ability to: i) produce high-fidelity cross-modal reconstructions with dense unsupervised correspondences, ii) generalize to unseen contact formations,and iii) state-estimation with partial visio-tactile feedback