 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Fold Real Garments with One Arm: A Case Study in Cloud-Based Robotics Research
Apr 21, 2022


Autonomous fabric manipulation is a longstanding challenge in robotics, but evaluating progress is difficult due to the cost and diversity of robot hardware. Using Reach, a cloud robotics platform that enables low-latency remote execution of control policies on physical robots, we present the first systematic benchmarking of fabric manipulation algorithms on physical hardware. We develop 4 novel learning-based algorithms that model expert actions, keypoints, reward functions, and dynamic motions, and we compare these against 4 learning-free and inverse dynamics algorithms on the task of folding a crumpled T-shirt with a single robot arm. The entire lifecycle of data collection, model training, and policy evaluation is performed remotely without physical access to the robot workcell. Results suggest a new algorithm combining imitation learning with analytic methods achieves 84% of human-level performance on the folding task. See https://sites.google.com/berkeley.edu/cloudfolding for all data, code, models, and supplemental material.
Unrolling SGD: Understanding Factors Influencing Machine Unlearning
Sep 27, 2021
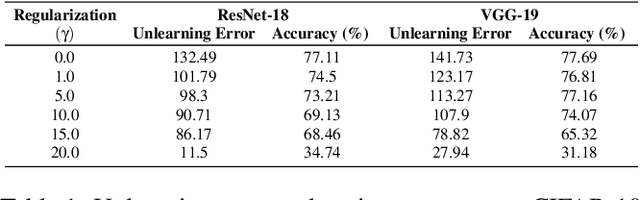
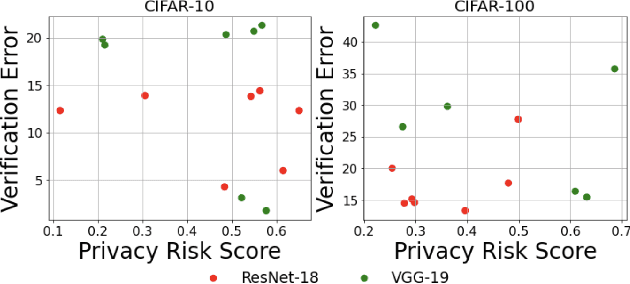
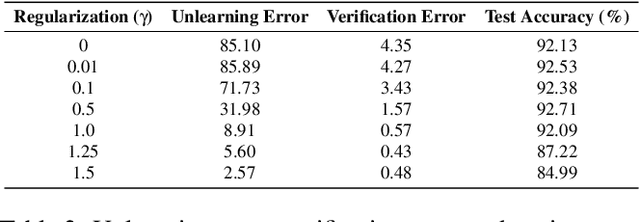
Machine unlearning is the process through which a deployed machine learning model forgets about one of its training data points. While naively retraining the model from scratch is an option, it is almost always associated with a large computational effort for deep learning models. Thus, several approaches to approximately unlearn have been proposed along with corresponding metrics that formalize what it means for a model to forget about a data point. In this work, we first taxonomize approaches and metrics of approximate unlearning. As a result, we identify verification error, i.e., the L2 difference between the weights of an approximately unlearned and a naively retrained model, as a metric approximate unlearning should optimize for as it implies a large class of other metrics. We theoretically analyze the canonical stochastic gradient descent (SGD) training algorithm to surface the variables which are relevant to reducing the verification error of approximate unlearning for SGD. From this analysis, we first derive an easy-to-compute proxy for verification error (termed unlearning error). The analysis also informs the design of a new training objective penalty that limits the overall change in weights during SGD and as a result facilitates approximate unlearning with lower verification error. We validate our theoretical work through an empirical evaluation on CIFAR-10, CIFAR-100, and IMDB sentiment analysis.
Interpretability in Safety-Critical FinancialTrading Systems
Sep 24, 2021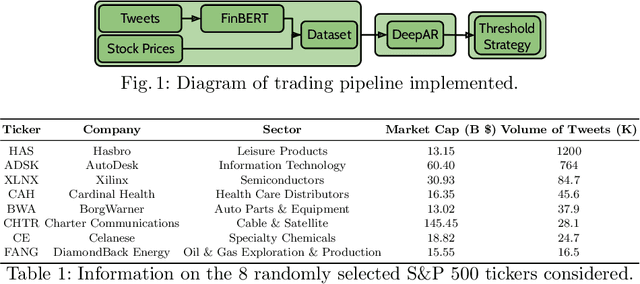
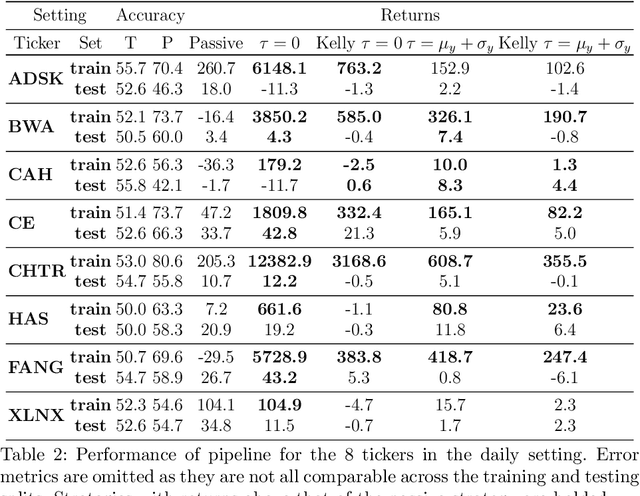

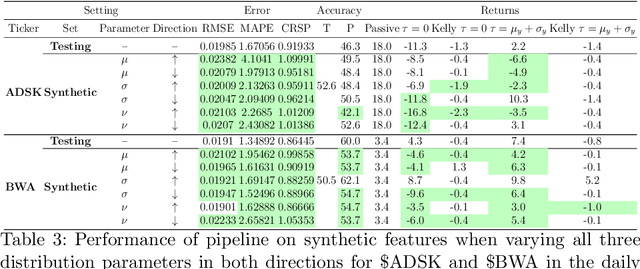
Sophisticated machine learning (ML) models to inform trading in the financial sector create problems of interpretability and risk management. Seemingly robust forecasting models may behave erroneously in out of distribution settings. In 2020, some of the world's most sophisticated quant hedge funds suffered losses as their ML models were first underhedged, and then overcompensated. We implement a gradient-based approach for precisely stress-testing how a trading model's forecasts can be manipulated, and their effects on downstream tasks at the trading execution level. We construct inputs -- whether in changes to sentiment or market variables -- that efficiently affect changes in the return distribution. In an industry-standard trading pipeline, we perturb model inputs for eight S&P 500 stocks. We find our approach discovers seemingly in-sample input settings that result in large negative shifts in return distributions. We provide the financial community with mechanisms to interpret ML forecasts in trading systems. For the security community, we provide a compelling application where studying ML robustness necessitates that one capture an end-to-end system's performance rather than study a ML model in isolation. Indeed, we show in our evaluation that errors in the forecasting model's predictions alone are not sufficient for trading decisions made based on these forecasts to yield a negative return.