 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Feels Bad Man: Dissecting Automated Hateful Meme Detection Through the Lens of Facebook's Challenge
Feb 17, 2022
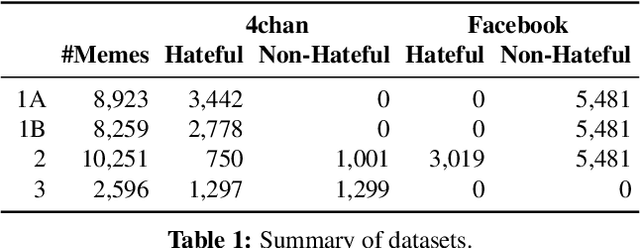
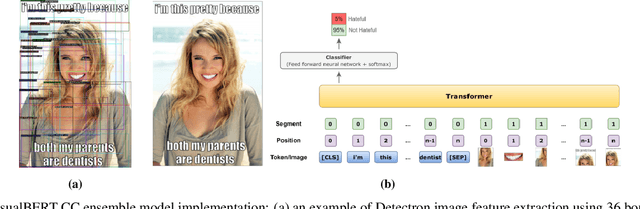

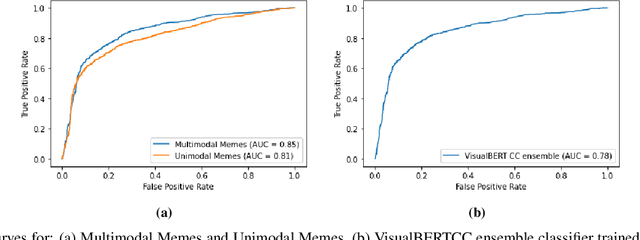
Internet memes have become a dominant method of communication; at the same time, however, they are also increasingly being used to advocate extremism and foster derogatory beliefs. Nonetheless, we do not have a firm understanding as to which perceptual aspects of memes cause this phenomenon. In this work, we assess the efficacy of current state-of-the-art multimodal machine learning models toward hateful meme detection, and in particular with respect to their generalizability across platforms. We use two benchmark datasets comprising 12,140 and 10,567 images from 4chan's "Politically Incorrect" board (/pol/) and Facebook's Hateful Memes Challenge dataset to train the competition's top-ranking machine learning models for the discovery of the most prominent features that distinguish viral hateful memes from benign ones. We conduct three experiments to determine the importance of multimodality on classification performance, the influential capacity of fringe Web communities on mainstream social platforms and vice versa, and the models' learning transferability on 4chan memes. Our experiments show that memes' image characteristics provide a greater wealth of information than its textual content. We also find that current systems developed for online detection of hate speech in memes necessitate further concentration on its visual elements to improve their interpretation of underlying cultural connotations, implying that multimodal models fail to adequately grasp the intricacies of hate speech in memes and generalize across social media platforms.
Robust Dynamic State Estimator of Integrated Energy Systems based on Natural Gas Partial Differential Equations
Feb 04, 2022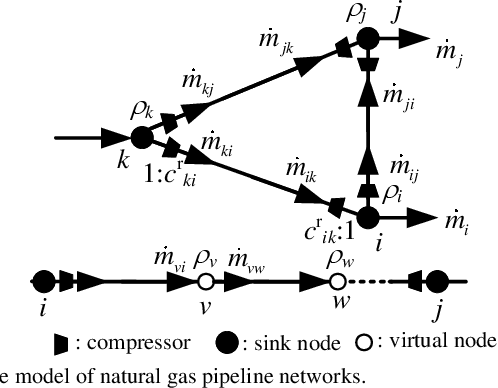
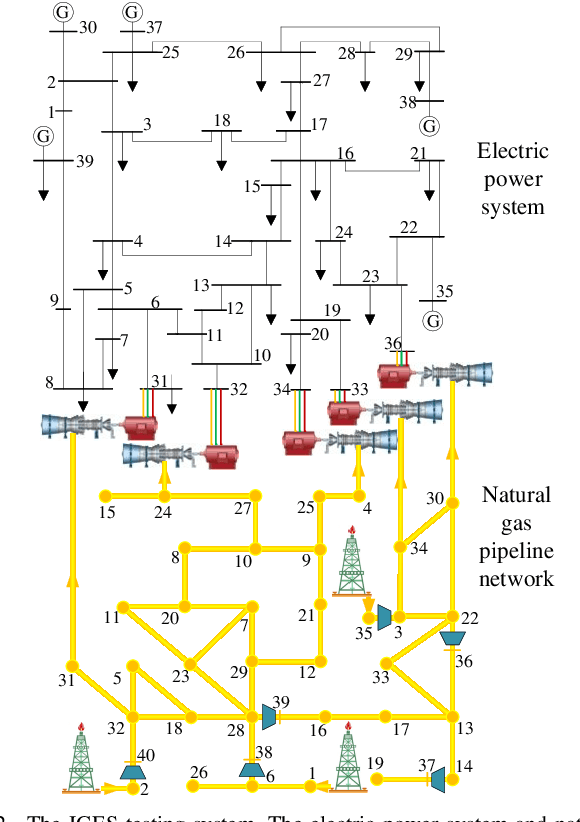
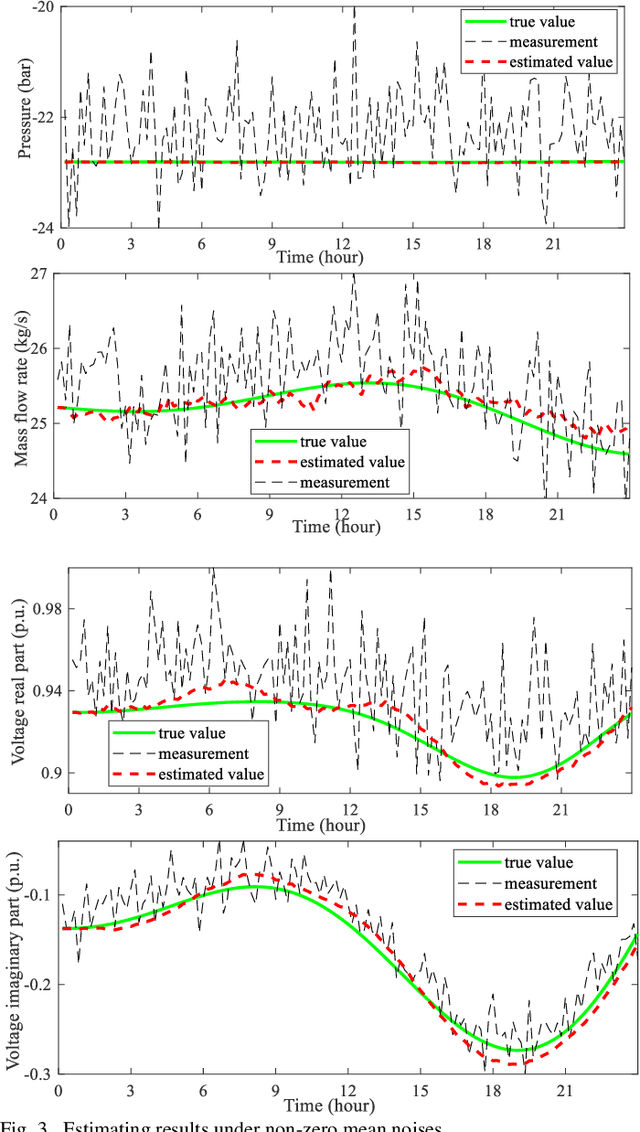
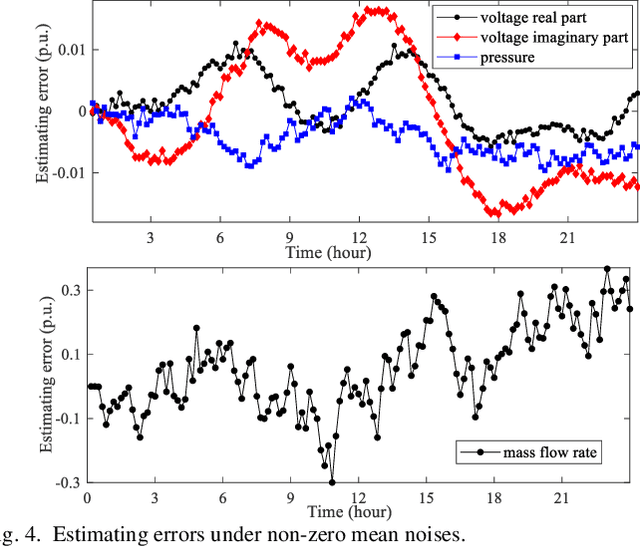
The reliability and precision of dynamic database are vital for the optimal operating and global control of integrated energy systems. One of the effective ways to obtain the accurate states is state estimations. A novel robust dynamic state estimation methodology for integrated natural gas and electric power systems is proposed based on Kalman filter. To take full advantage of measurement redundancies and predictions for enhancing the estimating accuracy, the dynamic state estimation model coupling gas and power systems by gas turbine units is established. The exponential smoothing technique and gas physical model are integrated in Kalman filter. Additionally, the time-varying scalar matrix is proposed to conquer bad data in Kalman filter algorithm. The proposed method is applied to an integrated gas and power systems formed by GasLib-40 and IEEE 39-bus system with five gas turbine units. The simulating results show that the method can obtain the accurate dynamic states under three different measurement error conditions, and the filtering performance are better than separate estimation methods. Additionally, the proposed method is robust when the measurements experience bad data.
DeepKE: A Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population
Jan 24, 2022
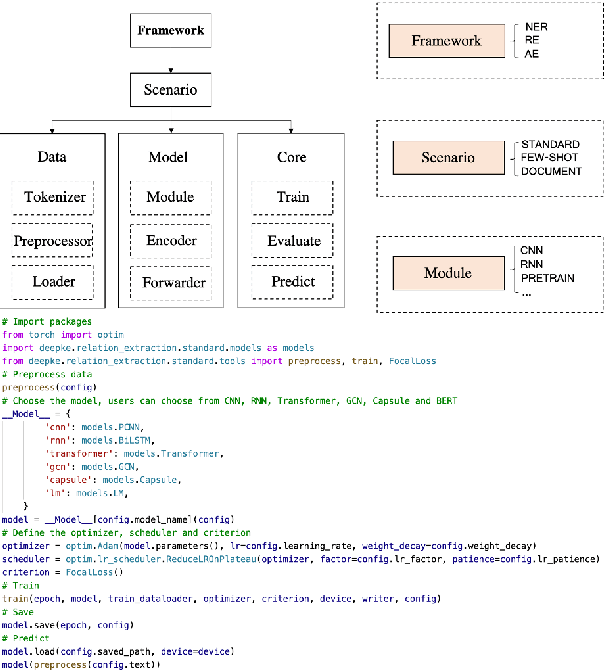
We present a new open-source and extensible knowledge extraction toolkit, called DeepKE (Deep learning based Knowledge Extraction), supporting standard fully supervised, low-resource few-shot and document-level scenarios. DeepKE implements various information extraction tasks, including named entity recognition, relation extraction and attribute extraction. With a unified framework, DeepKE allows developers and researchers to customize datasets and models to extract information from unstructured texts according to their requirements. Specifically, DeepKE not only provides various functional modules and model implementation for different tasks and scenarios but also organizes all components by consistent frameworks to maintain sufficient modularity and extensibility. Besides, we present an online platform in http://deepke.zjukg.cn/ for real-time extraction of various tasks. DeepKE has been equipped with Google Colab tutorials and comprehensive documents for beginners. We release the source code at https://github.com/zjunlp/DeepKE, with a demo video.
Evaluation and Comparison of Deep Learning Methods for Pavement Crack Identification with Visual Images
Dec 20, 2021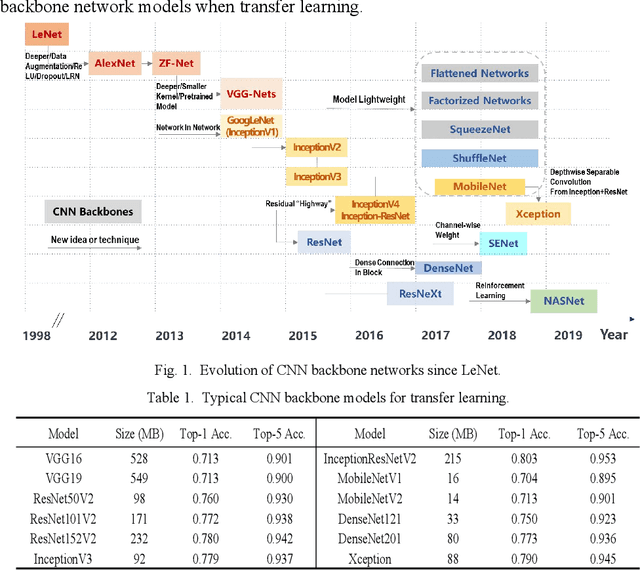
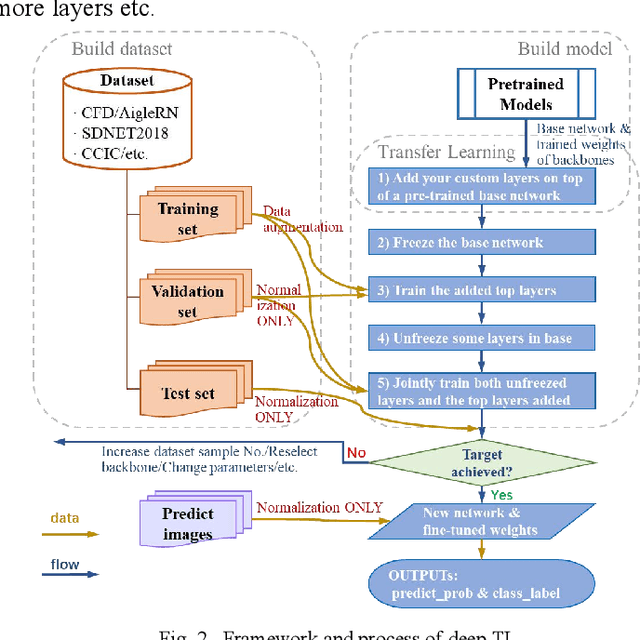

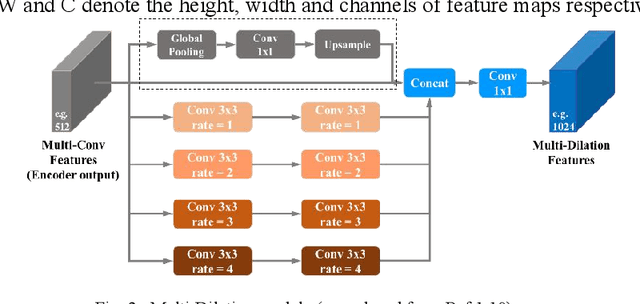
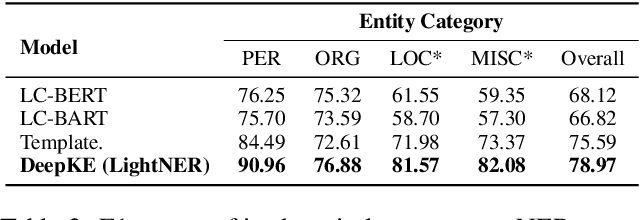
Compared with contact detection techniques, pavement crack identification with visual images via deep learning algorithms has the advantages of not being limited by the material of object to be detected, fast speed and low cost. The fundamental frameworks and typical model architectures of transfer learning (TL), encoder-decoder (ED), generative adversarial networks (GAN), and their common modules were first reviewed, and then the evolution of convolutional neural network (CNN) backbone models and GAN models were summarized. The crack classification, segmentation performance, and effect were tested on the SDNET2018 and CFD public data sets. In the aspect of patch sample classification, the fine-tuned TL models can be equivalent to or even slightly better than the ED models in accuracy, and the predicting time is faster; In the aspect of accurate crack location, both ED and GAN algorithms can achieve pixel-level segmentation and is expected to be detected in real time on low computing power platform. Furthermore, a weakly supervised learning framework of combined TL-SSGAN and its performance enhancement measures are proposed, which can maintain comparable crack identification performance with that of the supervised learning, while greatly reducing the number of labeled samples required.
Winning Solution of the AIcrowd SBB Flatland Challenge 2019-2020
Nov 11, 2021This report describes the main ideas of the solution which won the AIcrowd SBB Flatland Challenge 2019-2020, with a score of 99% (meaning that, on average, 99% of the agents were routed to their destinations within the allotted time steps). The details of the task can be found on the competition's website. The solution consists of 2 major components: 1) A component which (re-)generates paths over a time-expanded graph for each agent 2) A component which updates the agent paths after a malfunction occurs, in order to try to preserve the same agent ordering of entering each cell as before the malfunction. The goal of this component is twofold: a) to (try to) avoid deadlocks b) to bring the system back to a consistent state (where each agent has a feasible path over the time-expanded graph). I am discussing both of these components, as well as a series of potentially promising, but unexplored ideas, below.
Variational Autoencoders for Studying the Manifold of Precoding Matrices with High Spectral Efficiency
Dec 01, 2021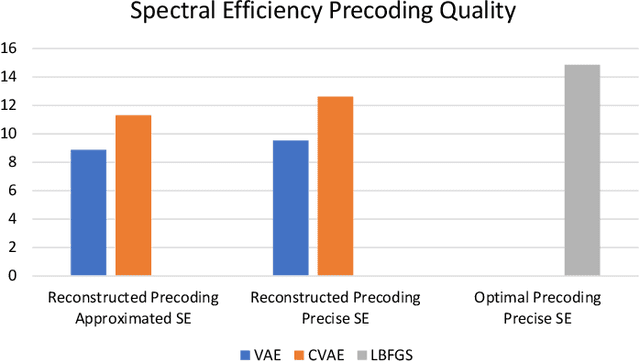
In multiple-input multiple-output (MIMO) wireless communications systems, neural networks have been employed for channel decoding, detection, channel estimation, and resource management. In this paper, we look at how to use a variational autoencoder to find a precoding matrix with a high Spectral Efficiency (SE). To collect optimal precoding matrices, an optimization approach is used. Our objective is to create a less time-consuming algorithm with minimum quality degradation. To build precoding matrices, we employed two forms of variational autoencoders: conventional variational autoencoders (VAE) and conditional variational autoencoders (CVAE). Both methods may be used to study a wide range of optimal precoding matrices. To the best of our knowledge, the development of precoding matrices for the spectral efficiency objective function (SE) utilising VAE and CVAE methods is being published for the first time.
Design-Bench: Benchmarks for Data-Driven Offline Model-Based Optimization
Feb 17, 2022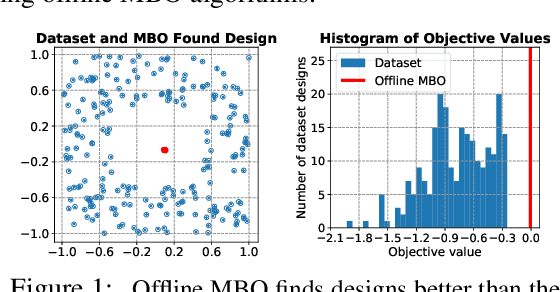
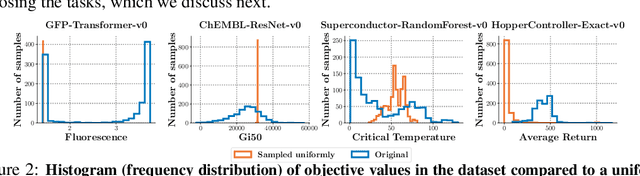
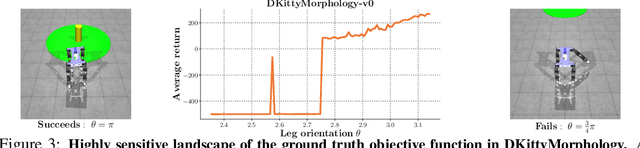
Black-box model-based optimization (MBO) problems, where the goal is to find a design input that maximizes an unknown objective function, are ubiquitous in a wide range of domains, such as the design of proteins, DNA sequences, aircraft, and robots. Solving model-based optimization problems typically requires actively querying the unknown objective function on design proposals, which means physically building the candidate molecule, aircraft, or robot, testing it, and storing the result. This process can be expensive and time consuming, and one might instead prefer to optimize for the best design using only the data one already has. This setting -- called offline MBO -- poses substantial and different algorithmic challenges than more commonly studied online techniques. A number of recent works have demonstrated success with offline MBO for high-dimensional optimization problems using high-capacity deep neural networks. However, the lack of standardized benchmarks in this emerging field is making progress difficult to track. To address this, we present Design-Bench, a benchmark for offline MBO with a unified evaluation protocol and reference implementations of recent methods. Our benchmark includes a suite of diverse and realistic tasks derived from real-world optimization problems in biology, materials science, and robotics that present distinct challenges for offline MBO. Our benchmark and reference implementations are released at github.com/rail-berkeley/design-bench and github.com/rail-berkeley/design-baselines.
Objective Prediction of Tomorrow's Affect Using Multi-Modal Physiological Data and Personal Chronicles: A Study of Monitoring College Student Well-being in 2020
Jan 26, 2022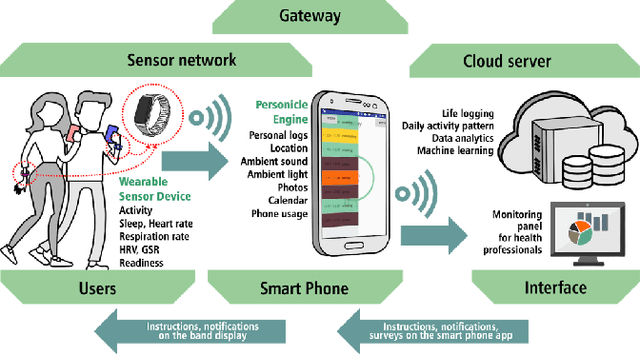
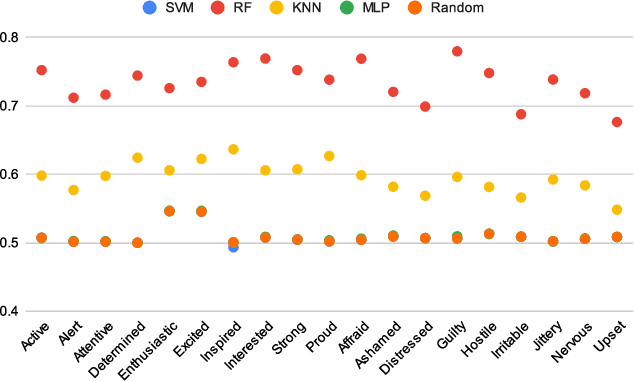
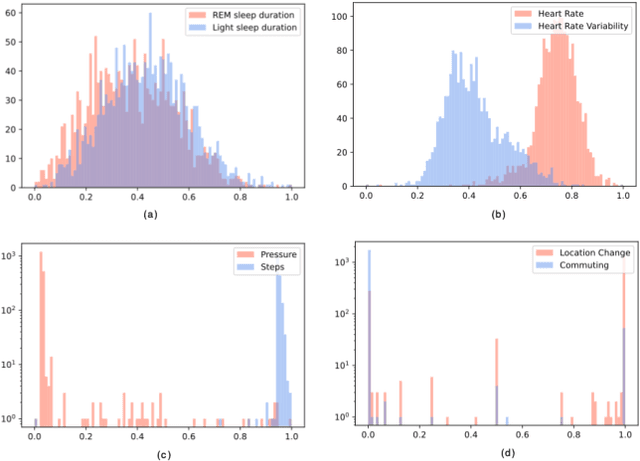
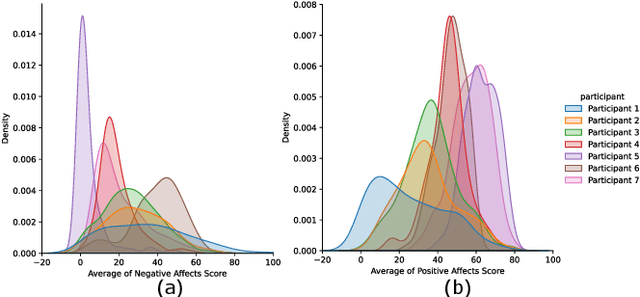
Monitoring and understanding affective states are important aspects of healthy functioning and treatment of mood-based disorders. Recent advancements of ubiquitous wearable technologies have increased the reliability of such tools in detecting and accurately estimating mental states (e.g., mood, stress, etc.), offering comprehensive and continuous monitoring of individuals over time. Previous attempts to model an individual's mental state were limited to subjective approaches or the inclusion of only a few modalities (i.e., phone, watch). Thus, the goal of our study was to investigate the capacity to more accurately predict affect through a fully automatic and objective approach using multiple commercial devices. Longitudinal physiological data and daily assessments of emotions were collected from a sample of college students using smart wearables and phones for over a year. Results showed that our model was able to predict next-day affect with accuracy comparable to state of the art methods.
Deconstructing Distributions: A Pointwise Framework of Learning
Feb 20, 2022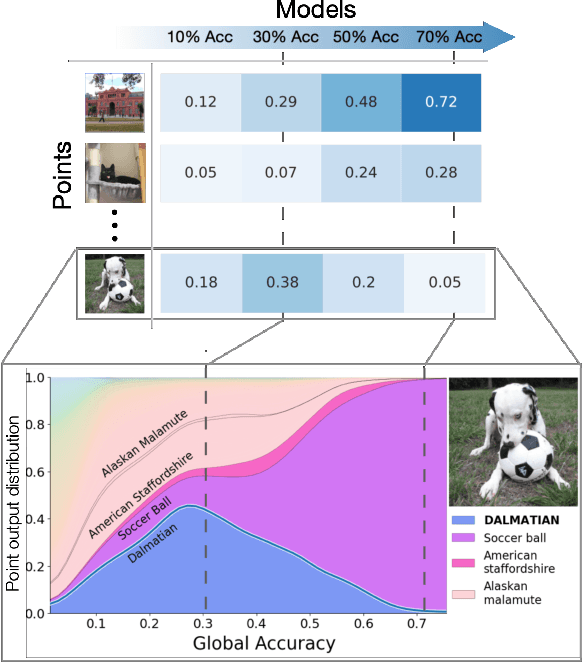

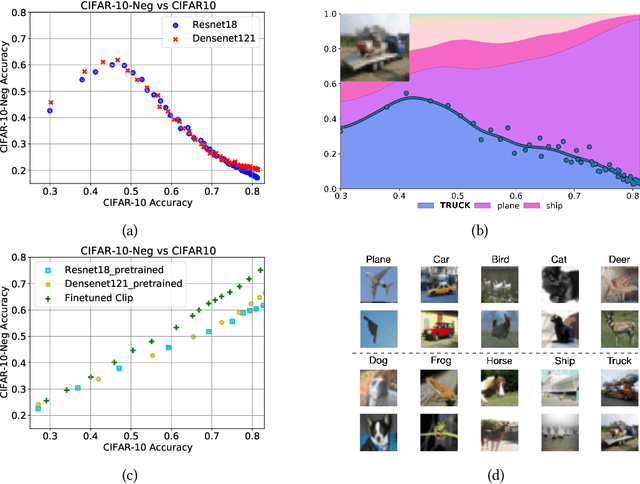

In machine learning, we traditionally evaluate the performance of a single model, averaged over a collection of test inputs. In this work, we propose a new approach: we measure the performance of a collection of models when evaluated on a $\textit{single input point}$. Specifically, we study a point's $\textit{profile}$: the relationship between models' average performance on the test distribution and their pointwise performance on this individual point. We find that profiles can yield new insights into the structure of both models and data -- in and out-of-distribution. For example, we empirically show that real data distributions consist of points with qualitatively different profiles. On one hand, there are "compatible" points with strong correlation between the pointwise and average performance. On the other hand, there are points with weak and even $\textit{negative}$ correlation: cases where improving overall model accuracy actually $\textit{hurts}$ performance on these inputs. We prove that these experimental observations are inconsistent with the predictions of several simplified models of learning proposed in prior work. As an application, we use profiles to construct a dataset we call CIFAR-10-NEG: a subset of CINIC-10 such that for standard models, accuracy on CIFAR-10-NEG is $\textit{negatively correlated}$ with accuracy on CIFAR-10 test. This illustrates, for the first time, an OOD dataset that completely inverts "accuracy-on-the-line" (Miller, Taori, Raghunathan, Sagawa, Koh, Shankar, Liang, Carmon, and Schmidt 2021)
Assessing generalisability of deep learning-based polyp detection and segmentation methods through a computer vision challenge
Feb 24, 2022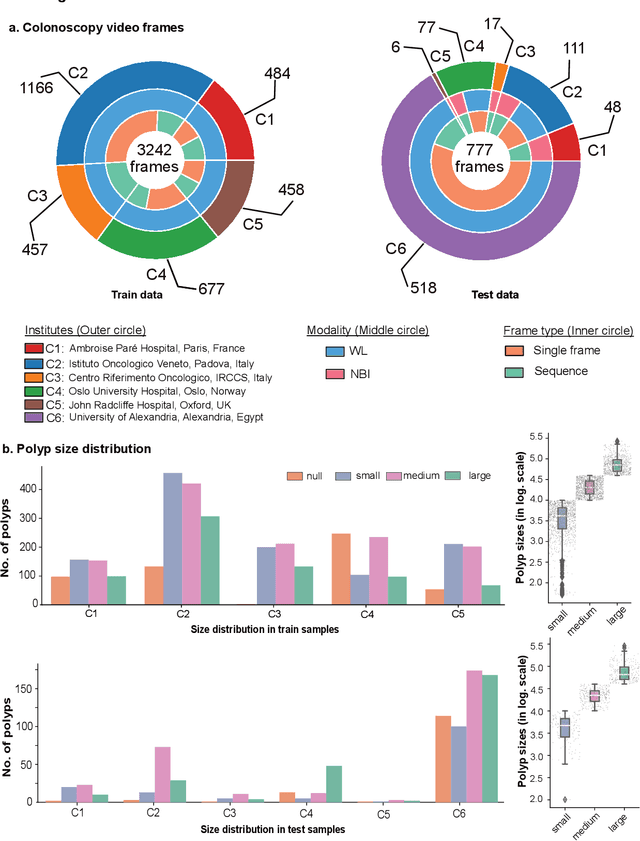
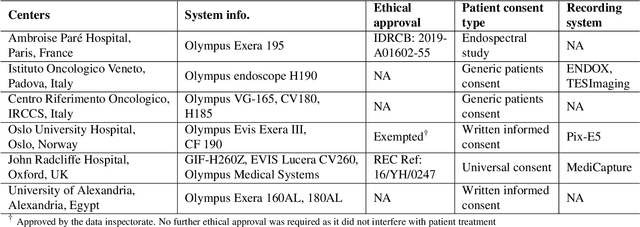
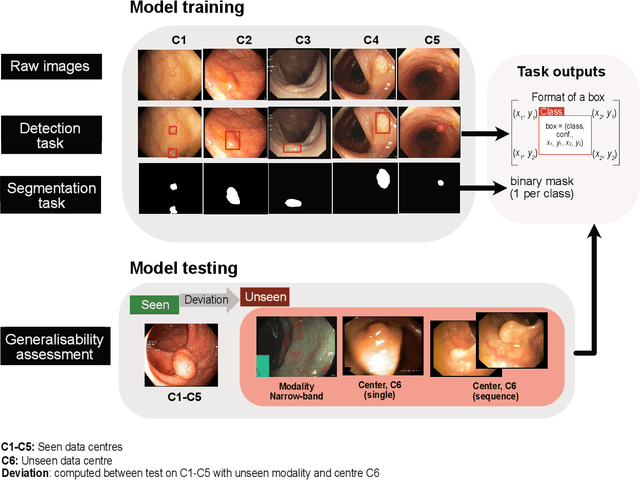
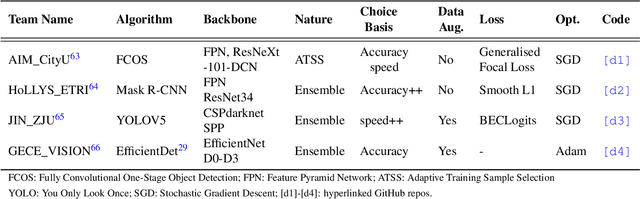
Polyps are well-known cancer precursors identified by colonoscopy. However, variability in their size, location, and surface largely affect identification, localisation, and characterisation. Moreover, colonoscopic surveillance and removal of polyps (referred to as polypectomy ) are highly operator-dependent procedures. There exist a high missed detection rate and incomplete removal of colonic polyps due to their variable nature, the difficulties to delineate the abnormality, the high recurrence rates, and the anatomical topography of the colon. There have been several developments in realising automated methods for both detection and segmentation of these polyps using machine learning. However, the major drawback in most of these methods is their ability to generalise to out-of-sample unseen datasets that come from different centres, modalities and acquisition systems. To test this hypothesis rigorously we curated a multi-centre and multi-population dataset acquired from multiple colonoscopy systems and challenged teams comprising machine learning experts to develop robust automated detection and segmentation methods as part of our crowd-sourcing Endoscopic computer vision challenge (EndoCV) 2021. In this paper, we analyse the detection results of the four top (among seven) teams and the segmentation results of the five top teams (among 16). Our analyses demonstrate that the top-ranking teams concentrated on accuracy (i.e., accuracy > 80% on overall Dice score on different validation sets) over real-time performance required for clinical applicability. We further dissect the methods and provide an experiment-based hypothesis that reveals the need for improved generalisability to tackle diversity present in multi-centre datasets.