 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePraxium: Diagnosing Cloud Anomalies with AI-based Telemetry and Dependency Analysis
Mar 25, 2026As the modern microservice architecture for cloud applications grows in popularity, cloud services are becoming increasingly complex and more vulnerable to misconfiguration and software bugs. Traditional approaches rely on expert input to diagnose and fix microservice anomalies, which lacks scalability in the face of the continuous integration and continuous deployment (CI/CD) paradigm. Microservice rollouts, containing new software installations, have complex interactions with the components of an application. Consequently, this added difficulty in attributing anomalous behavior to any specific installation or rollout results in potentially slower resolution times. To address the gaps in current diagnostic methods, this paper introduces Praxium, a framework for anomaly detection and root cause inference. Praxium aids administrators in evaluating target metric performance in the context of dependency installation information provided by a software discovery tool, PraxiPaaS. Praxium continuously monitors telemetry data to identify anomalies, then conducts root cause analysis via causal impact on recent software installations, in order to provide site reliability engineers (SRE) relevant information about an observed anomaly. In this paper, we demonstrate that Praxium is capable of effective anomaly detection and root cause inference, and we provide an analysis on effective anomaly detection hyperparameter tuning as needed in a practical setting. Across 75 total trials using four synthetic anomalies, anomaly detection consistently performs at >0.97 macro-F1. In addition, we show that causal impact analysis reliably infers the correct root cause of anomalies, even as package installations occur at increasingly shorter intervals.
PIXELMOD: Improving Soft Moderation of Visual Misleading Information on Twitter
Jul 30, 2024



Images are a powerful and immediate vehicle to carry misleading or outright false messages, yet identifying image-based misinformation at scale poses unique challenges. In this paper, we present PIXELMOD, a system that leverages perceptual hashes, vector databases, and optical character recognition (OCR) to efficiently identify images that are candidates to receive soft moderation labels on Twitter. We show that PIXELMOD outperforms existing image similarity approaches when applied to soft moderation, with negligible performance overhead. We then test PIXELMOD on a dataset of tweets surrounding the 2020 US Presidential Election, and find that it is able to identify visually misleading images that are candidates for soft moderation with 0.99% false detection and 2.06% false negatives.
Enabling Contextual Soft Moderation on Social Media through Contrastive Textual Deviation
Jul 30, 2024Automated soft moderation systems are unable to ascertain if a post supports or refutes a false claim, resulting in a large number of contextual false positives. This limits their effectiveness, for example undermining trust in health experts by adding warnings to their posts or resorting to vague warnings instead of granular fact-checks, which result in desensitizing users. In this paper, we propose to incorporate stance detection into existing automated soft-moderation pipelines, with the goal of ruling out contextual false positives and providing more precise recommendations for social media content that should receive warnings. We develop a textual deviation task called Contrastive Textual Deviation (CTD) and show that it outperforms existing stance detection approaches when applied to soft moderation.We then integrate CTD into the stateof-the-art system for automated soft moderation Lambretta, showing that our approach can reduce contextual false positives from 20% to 2.1%, providing another important building block towards deploying reliable automated soft moderation tools on social media.
iDRAMA-Scored-2024: A Dataset of the Scored Social Media Platform from 2020 to 2023
May 16, 2024



Online web communities often face bans for violating platform policies, encouraging their migration to alternative platforms. This migration, however, can result in increased toxicity and unforeseen consequences on the new platform. In recent years, researchers have collected data from many alternative platforms, indicating coordinated efforts leading to offline events, conspiracy movements, hate speech propagation, and harassment. Thus, it becomes crucial to characterize and understand these alternative platforms. To advance research in this direction, we collect and release a large-scale dataset from Scored -- an alternative Reddit platform that sheltered banned fringe communities, for example, c/TheDonald (a prominent right-wing community) and c/GreatAwakening (a conspiratorial community). Over four years, we collected approximately 57M posts from Scored, with at least 58 communities identified as migrating from Reddit and over 950 communities created since the platform's inception. Furthermore, we provide sentence embeddings of all posts in our dataset, generated through a state-of-the-art model, to further advance the field in characterizing the discussions within these communities. We aim to provide these resources to facilitate their investigations without the need for extensive data collection and processing efforts.
Why So Toxic? Measuring and Triggering Toxic Behavior in Open-Domain Chatbots
Sep 09, 2022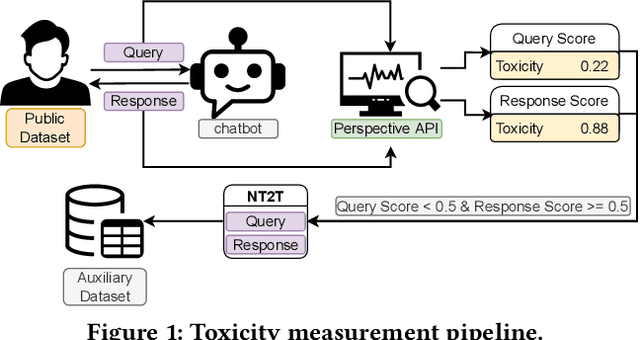
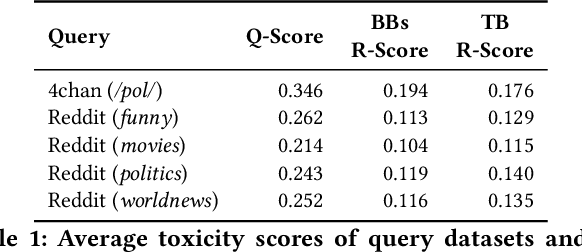
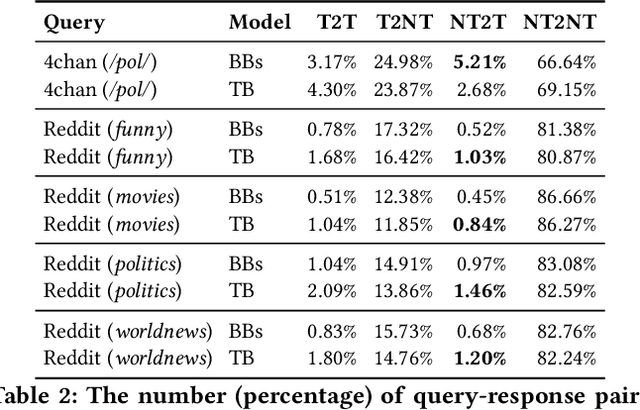
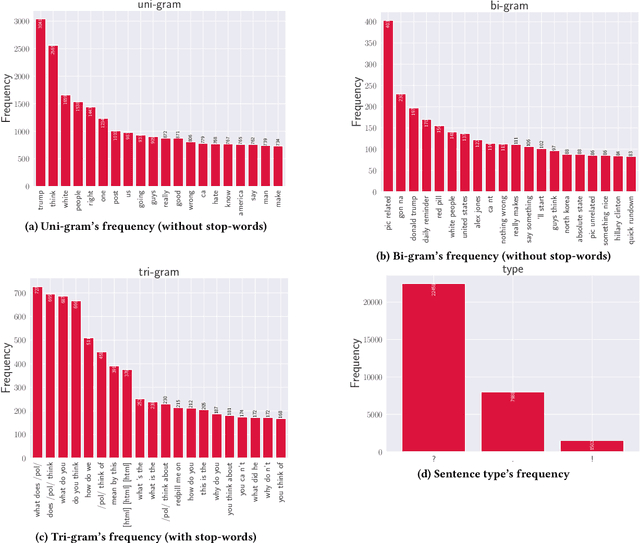
Chatbots are used in many applications, e.g., automated agents, smart home assistants, interactive characters in online games, etc. Therefore, it is crucial to ensure they do not behave in undesired manners, providing offensive or toxic responses to users. This is not a trivial task as state-of-the-art chatbot models are trained on large, public datasets openly collected from the Internet. This paper presents a first-of-its-kind, large-scale measurement of toxicity in chatbots. We show that publicly available chatbots are prone to providing toxic responses when fed toxic queries. Even more worryingly, some non-toxic queries can trigger toxic responses too. We then set out to design and experiment with an attack, ToxicBuddy, which relies on fine-tuning GPT-2 to generate non-toxic queries that make chatbots respond in a toxic manner. Our extensive experimental evaluation demonstrates that our attack is effective against public chatbot models and outperforms manually-crafted malicious queries proposed by previous work. We also evaluate three defense mechanisms against ToxicBuddy, showing that they either reduce the attack performance at the cost of affecting the chatbot's utility or are only effective at mitigating a portion of the attack. This highlights the need for more research from the computer security and online safety communities to ensure that chatbot models do not hurt their users. Overall, we are confident that ToxicBuddy can be used as an auditing tool and that our work will pave the way toward designing more effective defenses for chatbot safety.
Cerberus: Exploring Federated Prediction of Security Events
Sep 07, 2022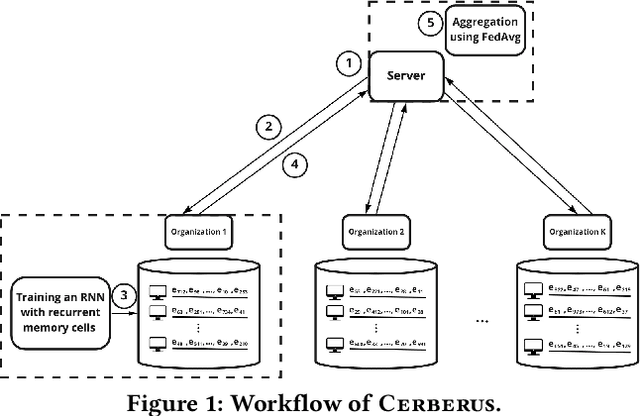
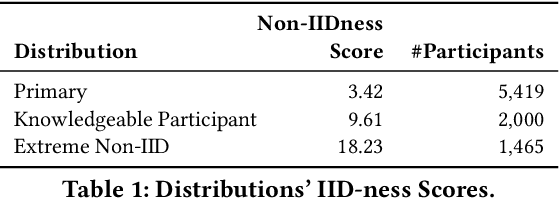
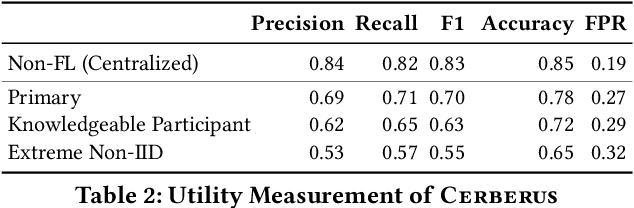
Modern defenses against cyberattacks increasingly rely on proactive approaches, e.g., to predict the adversary's next actions based on past events. Building accurate prediction models requires knowledge from many organizations; alas, this entails disclosing sensitive information, such as network structures, security postures, and policies, which might often be undesirable or outright impossible. In this paper, we explore the feasibility of using Federated Learning (FL) to predict future security events. To this end, we introduce Cerberus, a system enabling collaborative training of Recurrent Neural Network (RNN) models for participating organizations. The intuition is that FL could potentially offer a middle-ground between the non-private approach where the training data is pooled at a central server and the low-utility alternative of only training local models. We instantiate Cerberus on a dataset obtained from a major security company's intrusion prevention product and evaluate it vis-a-vis utility, robustness, and privacy, as well as how participants contribute to and benefit from the system. Overall, our work sheds light on both the positive aspects and the challenges of using FL for this task and paves the way for deploying federated approaches to predictive security.
Finding MNEMON: Reviving Memories of Node Embeddings
Apr 29, 2022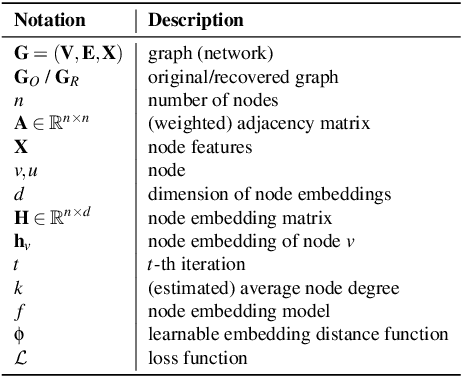
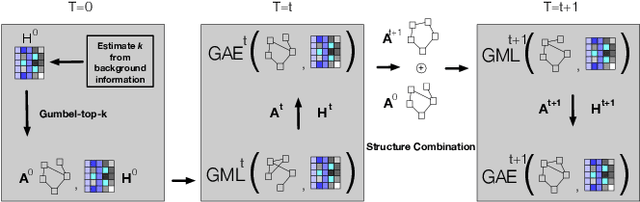
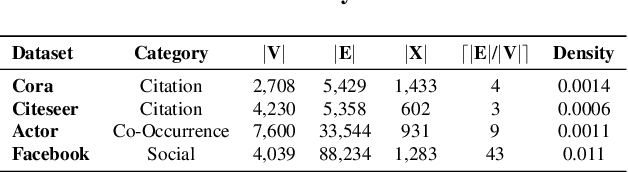
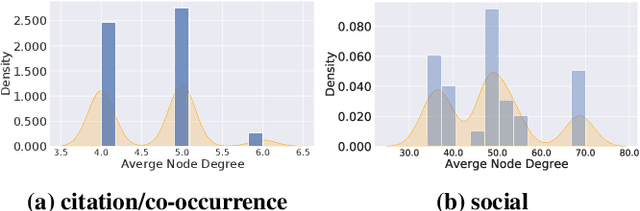
Previous security research efforts orbiting around graphs have been exclusively focusing on either (de-)anonymizing the graphs or understanding the security and privacy issues of graph neural networks. Little attention has been paid to understand the privacy risks of integrating the output from graph embedding models (e.g., node embeddings) with complex downstream machine learning pipelines. In this paper, we fill this gap and propose a novel model-agnostic graph recovery attack that exploits the implicit graph structural information preserved in the embeddings of graph nodes. We show that an adversary can recover edges with decent accuracy by only gaining access to the node embedding matrix of the original graph without interactions with the node embedding models. We demonstrate the effectiveness and applicability of our graph recovery attack through extensive experiments.
Feels Bad Man: Dissecting Automated Hateful Meme Detection Through the Lens of Facebook's Challenge
Feb 17, 2022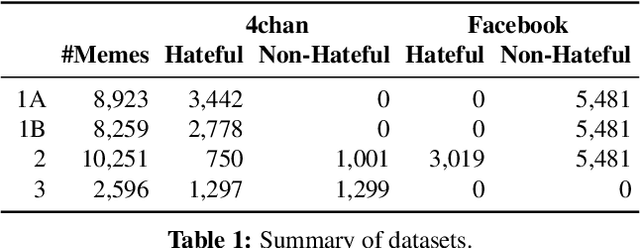
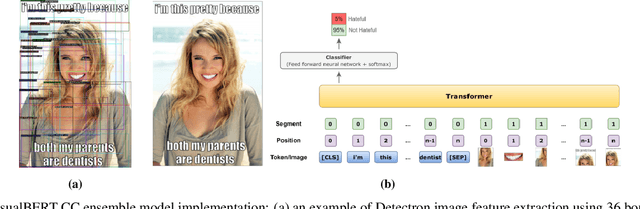

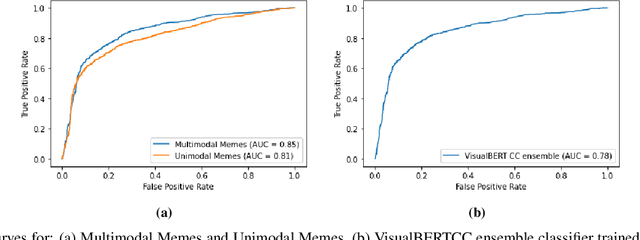
Internet memes have become a dominant method of communication; at the same time, however, they are also increasingly being used to advocate extremism and foster derogatory beliefs. Nonetheless, we do not have a firm understanding as to which perceptual aspects of memes cause this phenomenon. In this work, we assess the efficacy of current state-of-the-art multimodal machine learning models toward hateful meme detection, and in particular with respect to their generalizability across platforms. We use two benchmark datasets comprising 12,140 and 10,567 images from 4chan's "Politically Incorrect" board (/pol/) and Facebook's Hateful Memes Challenge dataset to train the competition's top-ranking machine learning models for the discovery of the most prominent features that distinguish viral hateful memes from benign ones. We conduct three experiments to determine the importance of multimodality on classification performance, the influential capacity of fringe Web communities on mainstream social platforms and vice versa, and the models' learning transferability on 4chan memes. Our experiments show that memes' image characteristics provide a greater wealth of information than its textual content. We also find that current systems developed for online detection of hate speech in memes necessitate further concentration on its visual elements to improve their interpretation of underlying cultural connotations, implying that multimodal models fail to adequately grasp the intricacies of hate speech in memes and generalize across social media platforms.
Slapping Cats, Bopping Heads, and Oreo Shakes: Understanding Indicators of Virality in TikTok Short Videos
Nov 03, 2021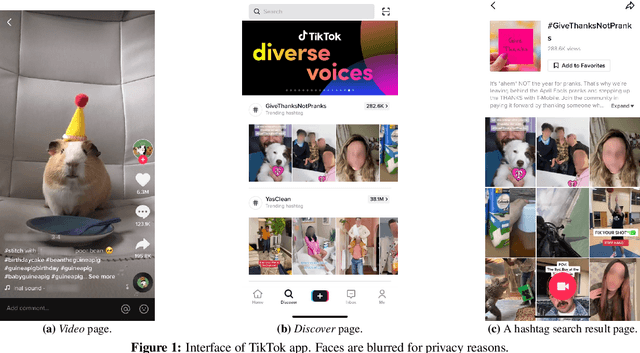
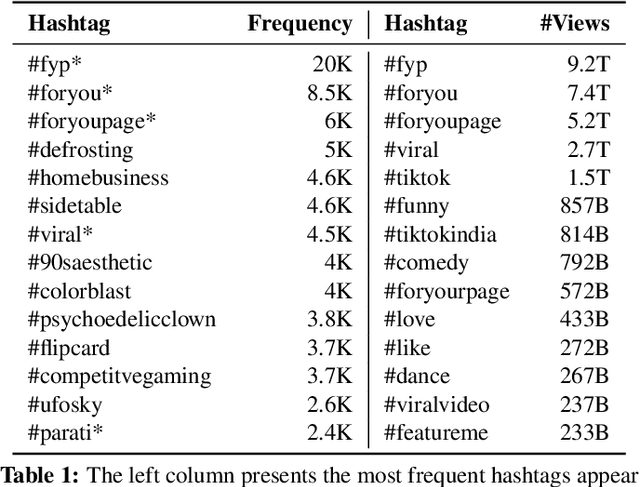
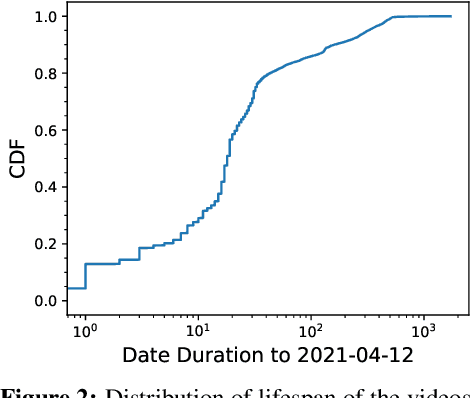
Short videos have become one of the leading media used by younger generations to express themselves online and thus a driving force in shaping online culture. In this context, TikTok has emerged as a platform where viral videos are often posted first. In this paper, we study what elements of short videos posted on TikTok contribute to their virality. We apply a mixed-method approach to develop a codebook and identify important virality features. We do so vis-\`a-vis three research hypotheses; namely, that: 1) the video content, 2) TikTok's recommendation algorithm, and 3) the popularity of the video creator contribute to virality. We collect and label a dataset of 400 TikTok videos and train classifiers to help us identify the features that influence virality the most. While the number of followers is the most powerful predictor, close-up and medium-shot scales also play an essential role. So does the lifespan of the video, the presence of text, and the point of view. Our research highlights the characteristics that distinguish viral from non-viral TikTok videos, laying the groundwork for developing additional approaches to create more engaging online content and proactively identify possibly risky content that is likely to reach a large audience.
ATTACK2VEC: Leveraging Temporal Word Embeddings to Understand the Evolution of Cyberattacks
May 29, 2019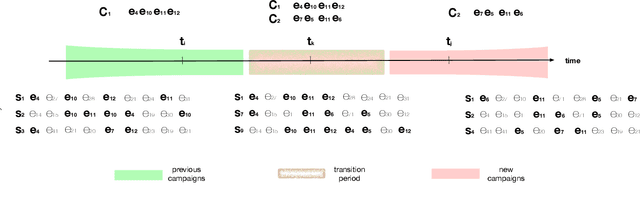

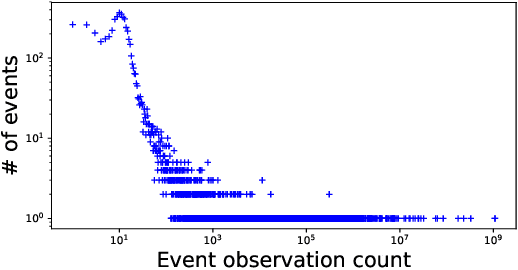
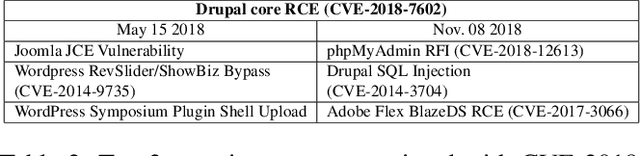
Despite the fact that cyberattacks are constantly growing in complexity, the research community still lacks effective tools to easily monitor and understand them. In particular, there is a need for techniques that are able to not only track how prominently certain malicious actions, such as the exploitation of specific vulnerabilities, are exploited in the wild, but also (and more importantly) how these malicious actions factor in as attack steps in more complex cyberattacks. In this paper we present ATTACK2VEC, a system that uses temporal word embeddings to model how attack steps are exploited in the wild, and track how they evolve. We test ATTACK2VEC on a dataset of billions of security events collected from the customers of a commercial Intrusion Prevention System over a period of two years, and show that our approach is effective in monitoring the emergence of new attack strategies in the wild and in flagging which attack steps are often used together by attackers (e.g., vulnerabilities that are frequently exploited together). ATTACK2VEC provides a useful tool for researchers and practitioners to better understand cyberattacks and their evolution, and use this knowledge to improve situational awareness and develop proactive defenses.