 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Trade offs When Conditioning Synthetic Data
Jul 03, 2025Learning robust object detectors from only a handful of images is a critical challenge in industrial vision systems, where collecting high quality training data can take months. Synthetic data has emerged as a key solution for data efficient visual inspection and pick and place robotics. Current pipelines rely on 3D engines such as Blender or Unreal, which offer fine control but still require weeks to render a small dataset, and the resulting images often suffer from a large gap between simulation and reality. Diffusion models promise a step change because they can generate high quality images in minutes, yet precise control, especially in low data regimes, remains difficult. Although many adapters now extend diffusion beyond plain text prompts, the effect of different conditioning schemes on synthetic data quality is poorly understood. We study eighty diverse visual concepts drawn from four standard object detection benchmarks and compare two conditioning strategies: prompt based and layout based. When the set of conditioning cues is narrow, prompt conditioning yields higher quality synthetic data; as diversity grows, layout conditioning becomes superior. When layout cues match the full training distribution, synthetic data raises mean average precision by an average of thirty four percent and by as much as one hundred seventy seven percent compared with using real data alone.
Towards Internet-Scale Training For Agents
Feb 10, 2025



The predominant approach for training web navigation agents gathers human demonstrations for a set of popular websites and hand-written tasks, but it is becoming clear that human data are an inefficient resource. We develop a pipeline to facilitate Internet-scale training for agents without laborious human annotations. In the first stage, an LLM generates tasks for 150k diverse websites. In the next stage, LLM agents complete tasks and produce trajectories. In the final stage, an LLM reviews the trajectories and judges their success. Language models are competitive with human annotators, detecting and filtering out harmful content with an accuracy of 97%, generating feasible tasks with an 89% rate, and judging successful trajectories with an 82.6% accuracy. Scaling the pipeline, agents based on Llama 3.1 70B solve 16.7% of tasks for 150k sites. Training on the data generated by our pipeline is competitive with training on human demonstrations. In data-limited settings derived from Mind2Web and WebLINX, we improve Step Accuracy by up to +89.5% and +122.1% respectively for agents trained on mixtures of data from our pipeline, and human data. When training agents with all available human data from these benchmarks, agents fail to generalize to diverse real sites, and adding our data improves their generalization by +149.0% for WebLINX and +156.3% for Mind2Web. Code will be available at: data-for-agents.github.io.
Understanding Visual Concepts Across Models
Jun 11, 2024



Large multimodal models such as Stable Diffusion can generate, detect, and classify new visual concepts after fine-tuning just a single word embedding. Do models learn similar words for the same concepts (i.e. <orange-cat> = orange + cat)? We conduct a large-scale analysis on three state-of-the-art models in text-to-image generation, open-set object detection, and zero-shot classification, and find that new word embeddings are model-specific and non-transferable. Across 4,800 new embeddings trained for 40 diverse visual concepts on four standard datasets, we find perturbations within an $\epsilon$-ball to any prior embedding that generate, detect, and classify an arbitrary concept. When these new embeddings are spliced into new models, fine-tuning that targets the original model is lost. We show popular soft prompt-tuning approaches find these perturbative solutions when applied to visual concept learning tasks, and embeddings for visual concepts are not transferable. Code for reproducing our work is available at: https://visual-words.github.io.
Leafy Spurge Dataset: Real-world Weed Classification Within Aerial Drone Imagery
May 08, 2024



Invasive plant species are detrimental to the ecology of both agricultural and wildland areas. Euphorbia esula, or leafy spurge, is one such plant that has spread through much of North America from Eastern Europe. When paired with contemporary computer vision systems, unmanned aerial vehicles, or drones, offer the means to track expansion of problem plants, such as leafy spurge, and improve chances of controlling these weeds. We gathered a dataset of leafy spurge presence and absence in grasslands of western Montana, USA, then surveyed these areas with a commercial drone. We trained image classifiers on these data, and our best performing model, a pre-trained DINOv2 vision transformer, identified leafy spurge with 0.84 accuracy (test set). This result indicates that classification of leafy spurge is tractable, but not solved. We release this unique dataset of labelled and unlabelled, aerial drone imagery for the machine learning community to explore. Improving classification performance of leafy spurge would benefit the fields of ecology, conservation, and remote sensing alike. Code and data are available at our website: leafy-spurge-dataset.github.io.
Stylus: Automatic Adapter Selection for Diffusion Models
Apr 29, 2024



Beyond scaling base models with more data or parameters, fine-tuned adapters provide an alternative way to generate high fidelity, custom images at reduced costs. As such, adapters have been widely adopted by open-source communities, accumulating a database of over 100K adapters-most of which are highly customized with insufficient descriptions. This paper explores the problem of matching the prompt to a set of relevant adapters, built on recent work that highlight the performance gains of composing adapters. We introduce Stylus, which efficiently selects and automatically composes task-specific adapters based on a prompt's keywords. Stylus outlines a three-stage approach that first summarizes adapters with improved descriptions and embeddings, retrieves relevant adapters, and then further assembles adapters based on prompts' keywords by checking how well they fit the prompt. To evaluate Stylus, we developed StylusDocs, a curated dataset featuring 75K adapters with pre-computed adapter embeddings. In our evaluation on popular Stable Diffusion checkpoints, Stylus achieves greater CLIP-FID Pareto efficiency and is twice as preferred, with humans and multimodal models as evaluators, over the base model. See stylus-diffusion.github.io for more.
Effective Data Augmentation With Diffusion Models
Feb 07, 2023Data augmentation is one of the most prevalent tools in deep learning, underpinning many recent advances, including those from classification, generative models, and representation learning. The standard approach to data augmentation combines simple transformations like rotations and flips to generate new images from existing ones. However, these new images lack diversity along key semantic axes present in the data. Consider the task of recognizing different animals. Current augmentations fail to produce diversity in task-relevant high-level semantic attributes like the species of the animal. We address the lack of diversity in data augmentation with image-to-image transformations parameterized by pre-trained text-to-image diffusion models. Our method edits images to change their semantics using an off-the-shelf diffusion model, and generalizes to novel visual concepts from a few labelled examples. We evaluate our approach on image classification tasks in a few-shot setting, and on a real-world weed recognition task, and observe an improvement in accuracy in tested domains.
A Simple Approach for Visual Rearrangement: 3D Mapping and Semantic Search
Jun 21, 2022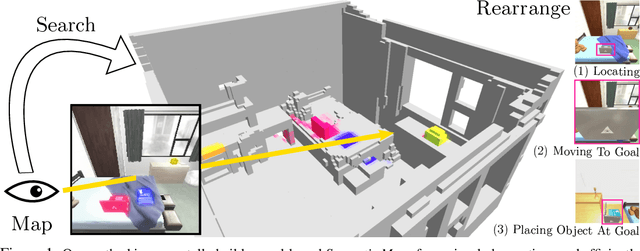
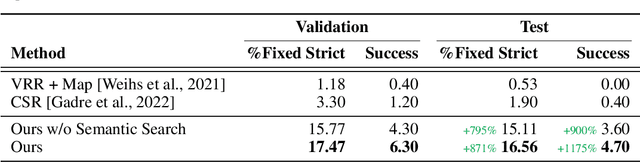
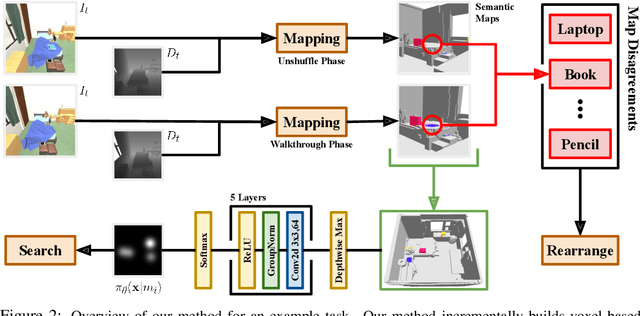
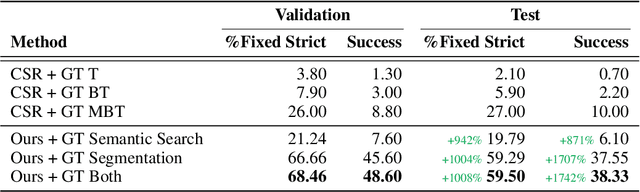
Physically rearranging objects is an important capability for embodied agents. Visual room rearrangement evaluates an agent's ability to rearrange objects in a room to a desired goal based solely on visual input. We propose a simple yet effective method for this problem: (1) search for and map which objects need to be rearranged, and (2) rearrange each object until the task is complete. Our approach consists of an off-the-shelf semantic segmentation model, voxel-based semantic map, and semantic search policy to efficiently find objects that need to be rearranged. On the AI2-THOR Rearrangement Challenge, our method improves on current state-of-the-art end-to-end reinforcement learning-based methods that learn visual rearrangement policies from 0.53% correct rearrangement to 16.56%, using only 2.7% as many samples from the environment.
AnyMorph: Learning Transferable Polices By Inferring Agent Morphology
Jun 17, 2022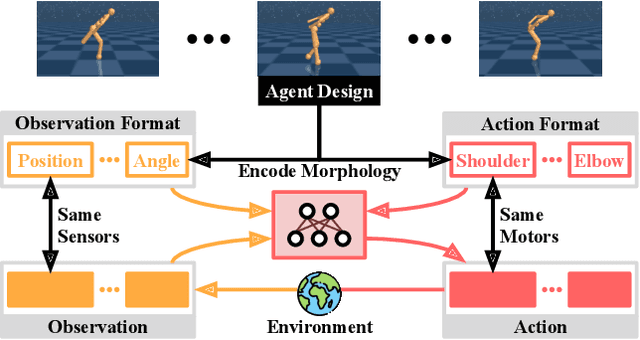
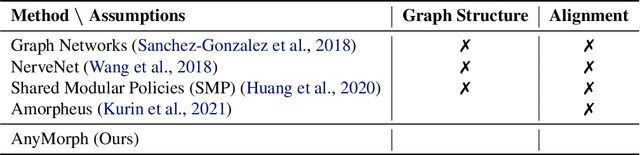
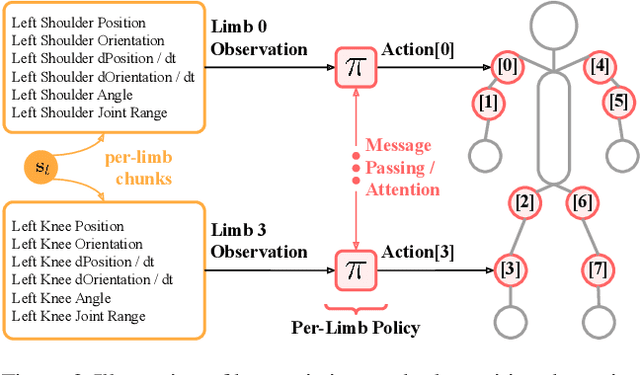

The prototypical approach to reinforcement learning involves training policies tailored to a particular agent from scratch for every new morphology. Recent work aims to eliminate the re-training of policies by investigating whether a morphology-agnostic policy, trained on a diverse set of agents with similar task objectives, can be transferred to new agents with unseen morphologies without re-training. This is a challenging problem that required previous approaches to use hand-designed descriptions of the new agent's morphology. Instead of hand-designing this description, we propose a data-driven method that learns a representation of morphology directly from the reinforcement learning objective. Ours is the first reinforcement learning algorithm that can train a policy to generalize to new agent morphologies without requiring a description of the agent's morphology in advance. We evaluate our approach on the standard benchmark for agent-agnostic control, and improve over the current state of the art in zero-shot generalization to new agents. Importantly, our method attains good performance without an explicit description of morphology.
Design-Bench: Benchmarks for Data-Driven Offline Model-Based Optimization
Feb 17, 2022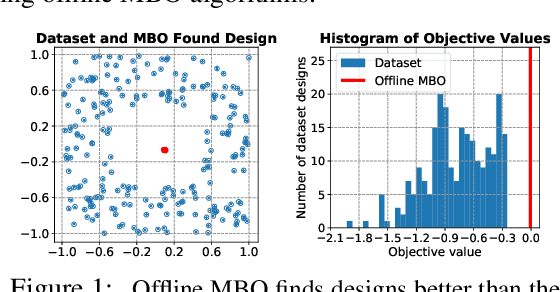
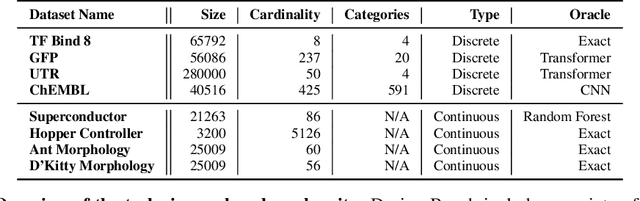
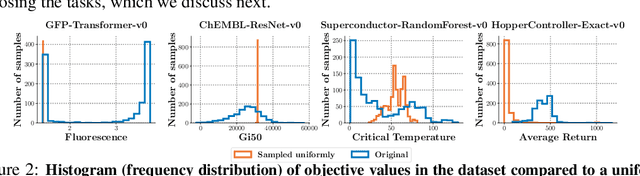
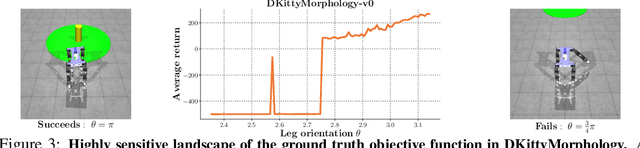
Black-box model-based optimization (MBO) problems, where the goal is to find a design input that maximizes an unknown objective function, are ubiquitous in a wide range of domains, such as the design of proteins, DNA sequences, aircraft, and robots. Solving model-based optimization problems typically requires actively querying the unknown objective function on design proposals, which means physically building the candidate molecule, aircraft, or robot, testing it, and storing the result. This process can be expensive and time consuming, and one might instead prefer to optimize for the best design using only the data one already has. This setting -- called offline MBO -- poses substantial and different algorithmic challenges than more commonly studied online techniques. A number of recent works have demonstrated success with offline MBO for high-dimensional optimization problems using high-capacity deep neural networks. However, the lack of standardized benchmarks in this emerging field is making progress difficult to track. To address this, we present Design-Bench, a benchmark for offline MBO with a unified evaluation protocol and reference implementations of recent methods. Our benchmark includes a suite of diverse and realistic tasks derived from real-world optimization problems in biology, materials science, and robotics that present distinct challenges for offline MBO. Our benchmark and reference implementations are released at github.com/rail-berkeley/design-bench and github.com/rail-berkeley/design-baselines.
Discovering Non-monotonic Autoregressive Orderings with Variational Inference
Oct 27, 2021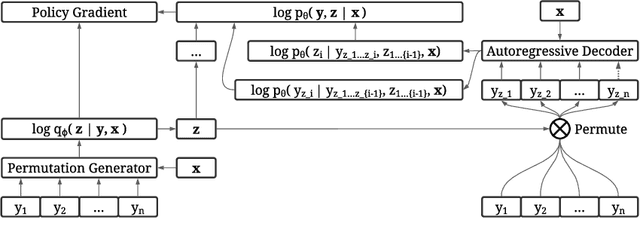
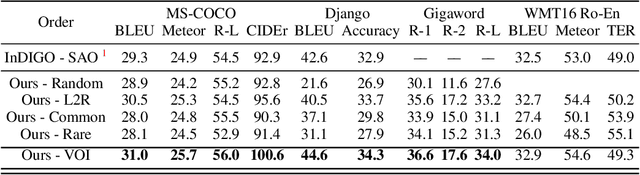
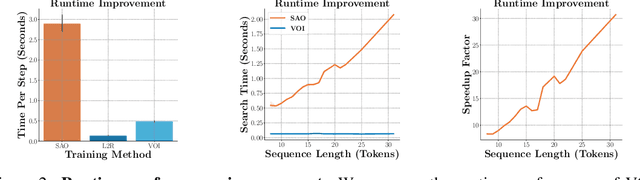
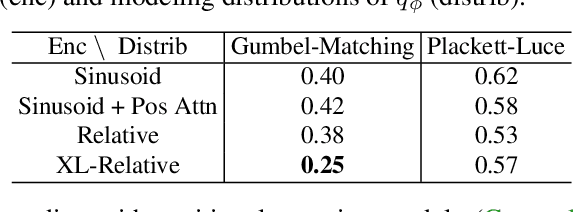
The predominant approach for language modeling is to process sequences from left to right, but this eliminates a source of information: the order by which the sequence was generated. One strategy to recover this information is to decode both the content and ordering of tokens. Existing approaches supervise content and ordering by designing problem-specific loss functions and pre-training with an ordering pre-selected. Other recent works use iterative search to discover problem-specific orderings for training, but suffer from high time complexity and cannot be efficiently parallelized. We address these limitations with an unsupervised parallelizable learner that discovers high-quality generation orders purely from training data -- no domain knowledge required. The learner contains an encoder network and decoder language model that perform variational inference with autoregressive orders (represented as permutation matrices) as latent variables. The corresponding ELBO is not differentiable, so we develop a practical algorithm for end-to-end optimization using policy gradients. We implement the encoder as a Transformer with non-causal attention that outputs permutations in one forward pass. Permutations then serve as target generation orders for training an insertion-based Transformer language model. Empirical results in language modeling tasks demonstrate that our method is context-aware and discovers orderings that are competitive with or even better than fixed orders.